In Tom White’s book, he mentioned in Chapter 6, Classic Mapreduce – He described from the macro perspective, the whole map reduce job could be mapped into 6 logical steps. Job submission, initialization, task assignment, execution, progress and status update and in the end, job completion.
We will start by looking at the job submission step first. Actually there is a class JobSubmitter in hadoop.mapreduce, and as the name indicates, this class handles how the job got submitted to the jobtracker from the client.

This method will get the source file system and destination file system and compare if they are the same ones by comparing host name and even port number.

Clearly, in the process of submitting the job, there will be some files involved that need to be sent to the job tracker, like the code files, the jar files, the customized configuration file etc. And before sending the file out, we need to check if the job tracker is actually on the same machine with the client. In that way, we don’t need to send the data out. And the return object of the method is the new Path(old path if exists).
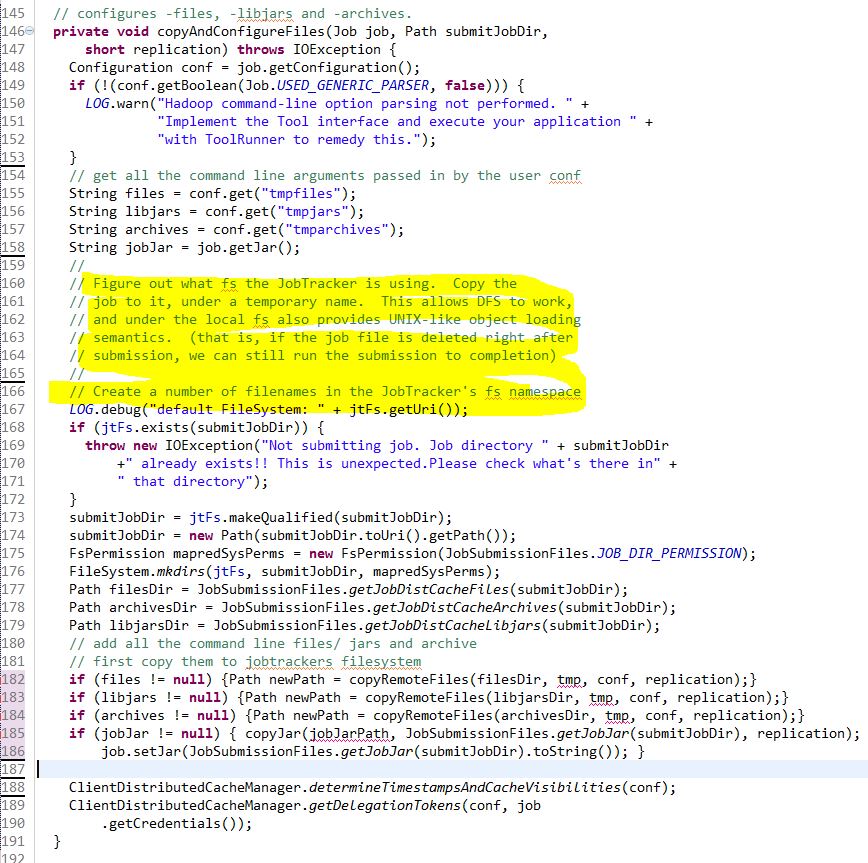
Of course, after checking if the local file system is actually the same as the remote file system. The smart and cautious hadoop developers will copy the files to the job track file system. In this step, it will check and load the files, libjars and archives. I omitted several lines of code and trying to fit the whole method into one screen shot. So the reader can have a brief idea of how this method looks like.

Now we are already half way through this class and I folded the rest of the class so you can have an overview of what is left in this class. As you can see, submitJobInternal might be the longest method in the code. And actually, the whole idea behind submitJobInternal is fairly straightforward. Maybe it will be helpful to understand if I categorize it into five words “1. Configure 2. Secret 3. Split 4. Queue 5. Submit”
(1). Configure:

basically configure the job based on the client attributes, set up all the configuration properties like user name, job id, host address, etc.
(2). Secret:
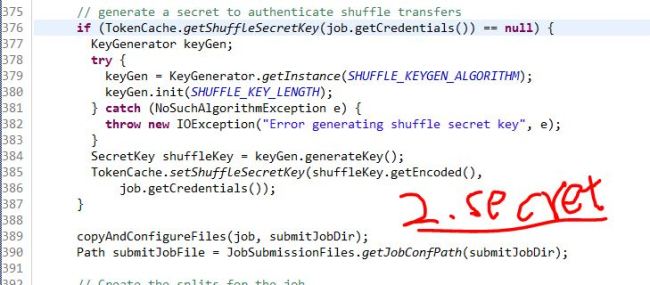
This job submission cannot happen with certain kind of credential behind it when distributing the job beyond only the jobid. It will get the delegation token for the job directory from the namenode and also generate a secret key.
(3). Splits

This method splits the input job logically.
(4). Queue

Set up which job queue the job need to be sent out and get the administration of that job queue.
(5). Submit

In this end, call the submitClient.submitJob method to submit the job to the jobtracker using the jobId, submission directory and the secret key/credentials. And after this is done, the staging table will get deleted and the job got submitted successfully.
Out of those five words, the Split is actually an interesting topic. Actually, there are three methods afterwards that are directly related to this concept. There are two scenarios when thinking about splitting input files as the input for mappers. If that is a job that has already been created, it will read in the number of mappers and split the input file based on that number. If that is a job that is new or doesn’t have the number of mappers specified, it will split in another way. After the splitting, it will sort the splitted file by size, so the file with the biggest size will get submitted first.

Note: The split is a logical split of the inputs, which means the files won’t be split physically into certain of chunks. And instead, each split file might just be a tuple which records the start line filename, number and offset.
