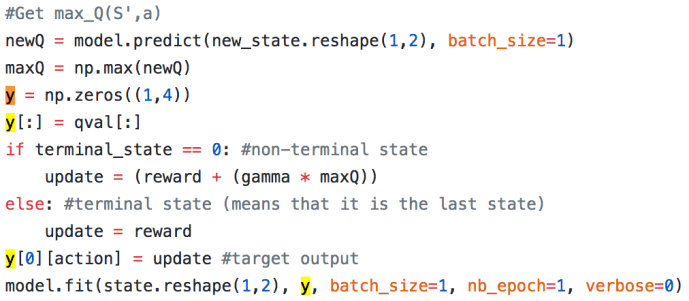
twp – tradeWithPython is a utility library meant to help quant who uses Python. You can find the source code here and the documentation here. This library has been used by several projects so I am going to take a dive into the backtest module and show how to use it (given the author did not put too much thought into the documentation, or he thought it is already straightforward enough :)) .
You can find the source code for the backtest module here. At a high level, backtesting in the financial realm refers to “estimate the performance of a strategy or model if it had been employed during a past period.” This will enable quants to quickly evaluate any given investing strategy without conducting real experiment nor waiting for another significant amount of time while still gain some real life insight with confidence by doing simulation on existing data. For example, backtest is the first class citizen of the popular algo platform quantopian.
Anyway, now you understand how important backtest is in testing algo now, let’s go through the source code twp.backtest to look through how a backtest module got implemented and what are the key metrics got captured there.
Let’s take a look at the class Backtest directly, the constructor itself has included all the key data elements outright.

Price is a panda Series which contains the time series of pricing information. If we are looking at stock price, pd.Series([1,2,3,4,5]) could represent the information that the given ticker is $1 per share on the first day, say Monday, has a one dollar increment for the rest of the week, ended $5 dollar on Friday. Signal is a variable that contains the financial activity or trading operation, for example, [NA, NA, 3, NA, -2] is a valid Signal variable which can be interpreted as the investor is in a long position of three shares of stock on the third day and in a short position of two shares on the last day, assuming the signal type is “shares” versus “capital”. The rest of the parameters are fairly easy to understand.
Now lets look at the body of the source code of the constructor:

At line 117, signal got “cleaned up” by call ffill() followed by fillna(0). These two methods used in conjunction is very common for dealing with time series information with missing values. Using the example where signal = [NA, NA, 3, NA, -2] again, ffill() is the same as locf in R, which in essence is to fill the missing value with the last non missing value. However, for the leading missing values, like the first two NAs in our example, there is no preceding valid value, then it will stay NA. After that, fillna will replace all the NAs, in this case, the leading NAs with whatever value got passed along, which is set to 0.

Next is the tradeIdx variable, it is basically the difference between every two pair of consecutive elements so theoretically, tradeIdx is exactly one element shorter than signal. However, for the very first element of the Series, there is no element prior to it to subtract with, it will be filled with NA so it has the same length as the input Series. Then fillna(0) will replace NA with 0 right after that.

Then tradeIdx will be used to slice the signal and store the trade into the variable self.trades, keeping the index number.
Now, let’s talk about the “shares” variable. It was calculated in this way
tradeIdx = signal.ffill.fillna.diff.fillna != 0
trades = signal[tradeIdx]
shares = trades.reindex.ffill.fillna
In essence, “shares” is basically “trades” and basically “signal”. So that in case, to calculate the delta, or in another way, on what day did the investor sold the stocks, we need to calculate the difference of shares to calculate the delta.

The screenshot above clearly explained how it looks like. And let’s translate the verbose code into plain English, which might be a bit easy to interpret. In the end, this basically describe a scenario where this person netted $6 by borrowing money to buy 3 shares of stock on the third day. And flipped it on the last day, where the price per share increased by 2 dollar. That left a $6 net profit on the book. At the same time, this person not only sold all the shares he borrowed, he is even in a position of “-2” on the last day, which indicates that he sold some shares that he even does not own. He could be borrowing two shares from somebody else at the value price of $5. He could have sold it on the next day and then buy it back in a future when the price is low, in that case, this person can not only pay back the two shares to its original owner but also profit since the he is in a short position and the price dropped in his favor.
Let’s give another example with some initial cash say $100 at the beginning and put this person in a short position given a growing underlying stock price – unlucky.

As you can see, this person borrowed and cashed out some stock on the third day, -9 on value and 109 on cash. Then the underlying price of stock keep going up and the three shared that he owned used to worth 9 dollars now he is in the situation which he owes 15 dollar worth of stock, which net a loss of 6 dollars.
Sharpe


Then in the backtest, the author implemented a method for a class called sharpe and there is also a utility function defined outside the class called sharpe with an argument which is the daily sharpe ratio, it basically convert from daily to annualized sharpe.

Today, we have covered the majority of the logical part of the backtest module, however, there are still a few functions like plotting that we need to further evaluate in the second part of the tutorial.