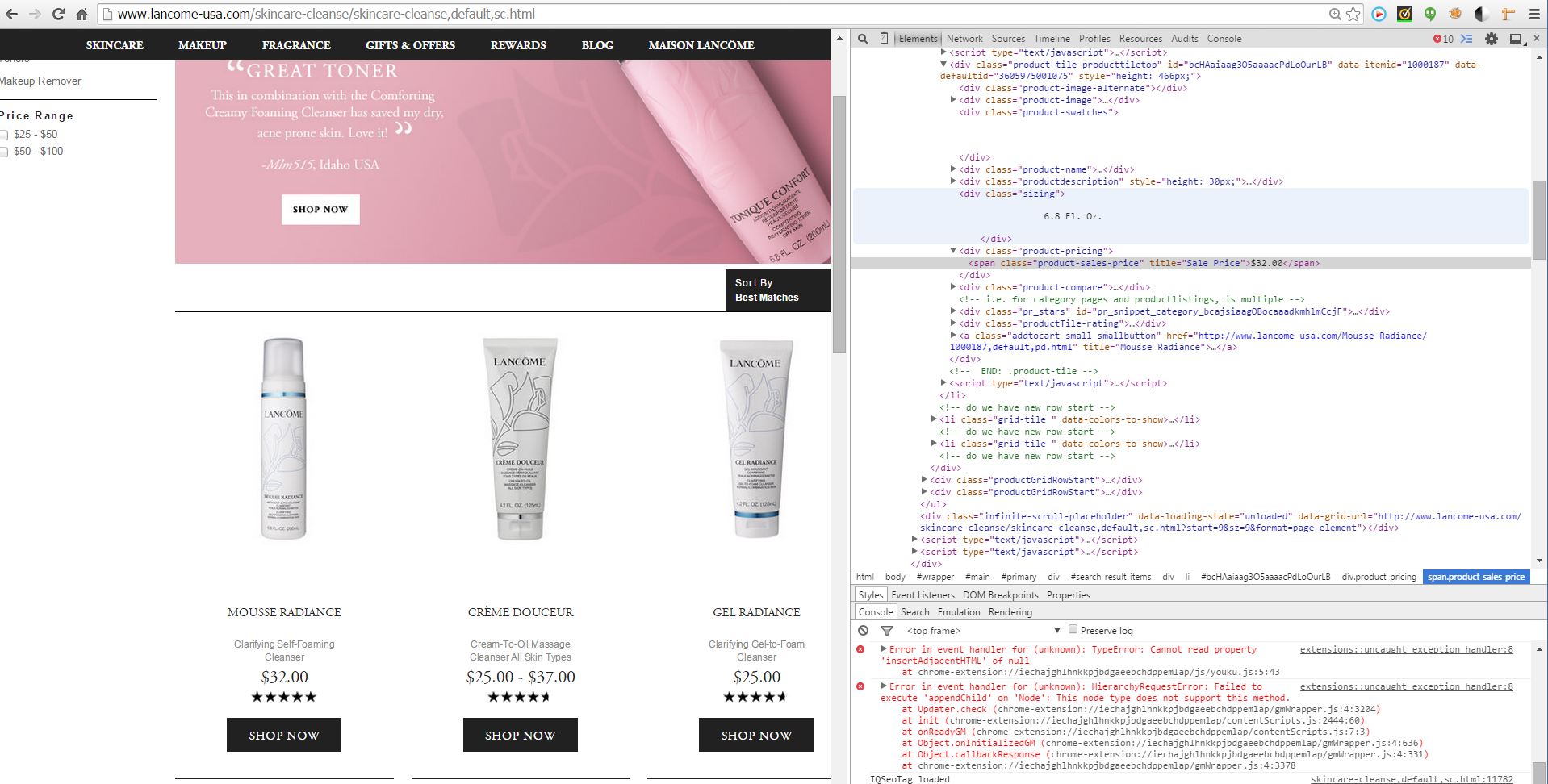
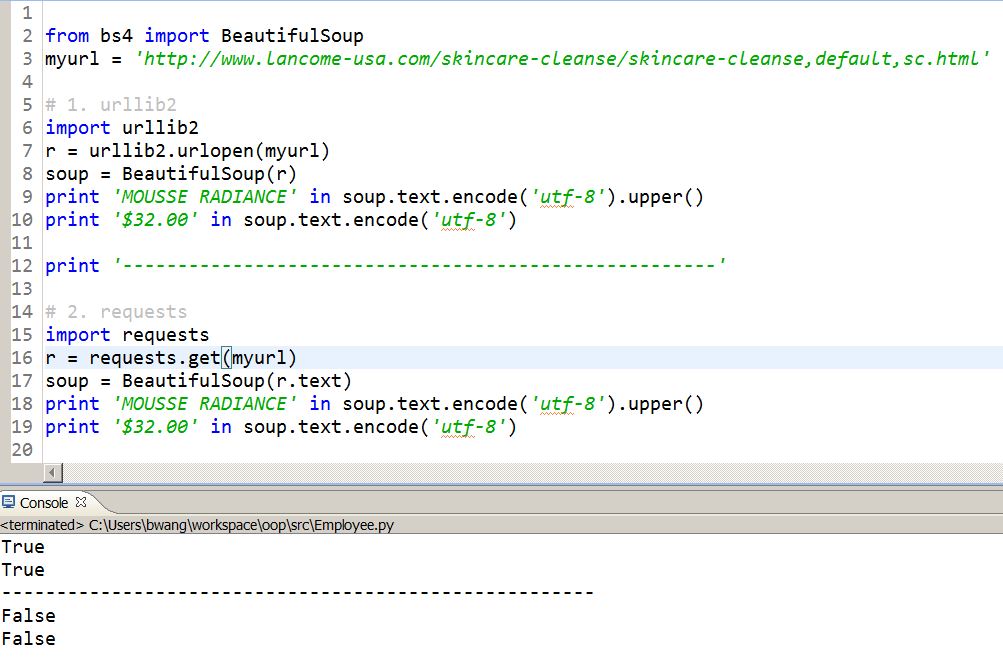
GF: hey baby, can you help me get the pricing for my wishlist?
BF: absolutely, I can help you scrape lancome’s whole websites and give you all the pricing! (fingercrossed).
I took a quick look at lancome’s website and realized that it is a very typical website, every tag has well formatted class name or id. Even if they don’t have well formatted json requests while monitoring their network activity, it is still doable just collect the populated HTML and use beautifulsoup to narrow down to the desired elements and content.
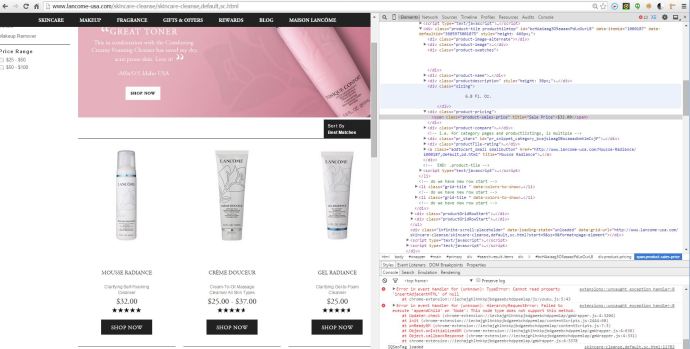
I used urllib2 to make a simple http request and clearly what I want is captured in the response and then it is just a matter of parsing the HTML, thanks to Beautifulsoup, life is so easy now.
Then the idea of using requests quickly came up to me. However, seems like the requests library is not working right out of box.
Here is a screenshot of comparing urlib2 with requests.
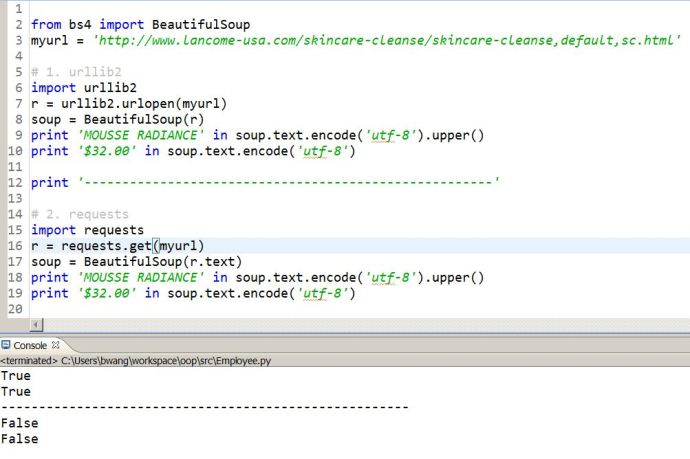
In the end, I realized that `r.text` is not enough. First, r.text will return the html in the unicode format and then screw up the soup while passing to the BeautifulSoup function.
In the end, I have to upgrade my Python version and meanwhile using r.content instead of r.text to make it work.