Here, I wrote a play book to distribute the configuration files to the cluster.You can access the playbook from my github account.
Then run the command, format the namenode and start_dfs.sh


When you try to use HDFS, it will tell you the service is in safe mode and whatever you do, seems like you cannot turn off the same mode. I did some google and people say it is due to the replication number, in my case, I have four nodes, 1 namenode, 1 used as resource manager and two other nodes used as slaves/nodemanager/datanode. In which case, there will be at most 2 nodes to store data. However, the replication factor for HDFS is 3 out of box, which means the data will always be under replicated. Also, the resource is extremely limited on a raspberry pi whose memory is only 512MB.
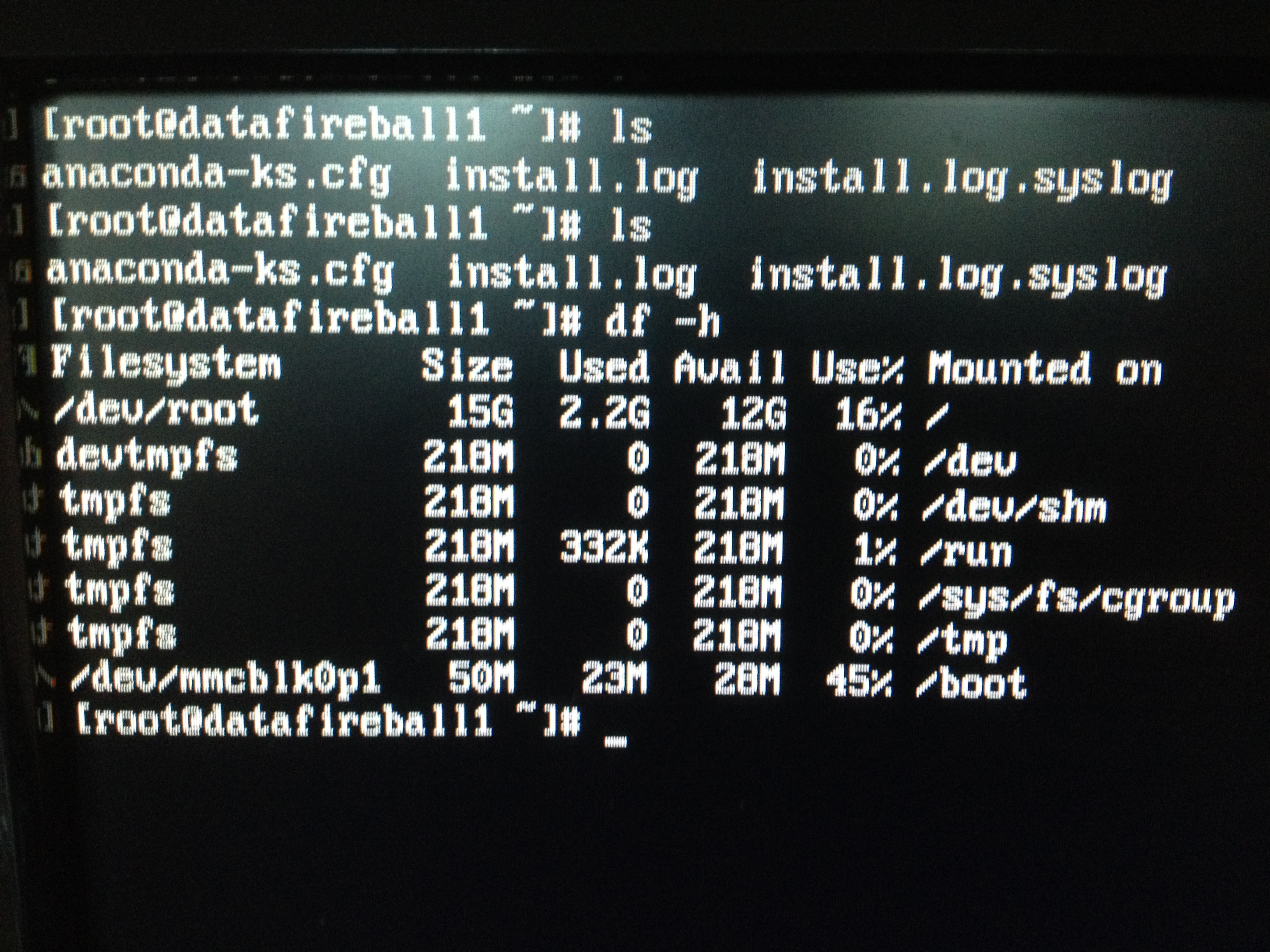
Actually, when I was trying to change the configuration file of hadoop, so the big elephant will fit into the raspberry pi box. I noticed that the board that I was using as the name node is actually a board with 218MB. I remembered that I got this board when Pis first came out and I pre-ordered it for my friend Alex and myself. In this case, I need to switch the namenode probably with another data node so the namenode will have enough resource to get hell out of the safe mode.

- There are a few things that I might do in the future, maybe set up Fedora also on my beagleboard-xm which is more powerful than raspberry Pi…
- I can run a virtual machine in my laptop just to act as the namenode to drive the other PIs. I don’t know if I can read the img file from the current SD card and create a virtual machine on my box.
However, I can think I already got a lot of fun from what I have done in this weekend. Myabe I will do that in the future or not… And “认真你就输了” (You lose when you get serious!) 🙂