As we have discussed previously, finding the most efficient keyboard could be viewed as a shortest distance problem where we arrange all the keys in a way that will minimize the total traveling distance given a specified typing task.
At first glance, it is different from commonly used graph algorithms as they mostly start with a graph (V, E) and our problem is actually to find the graph given the path. This blog post is meant to implement a solution using dynamic programming, reducing a challenging problems into smaller ones and then we will discuss the efficiency next.
Previously we have mentioned that there are n! permutations of different key layouts. For example, we face n different possibilities when we decide the the position of A, then if we fix B, there could be n-1 positions available as one position just got occupied by A, so on and so forth. We have n*(n-1)*…*1 = n! possibilities.
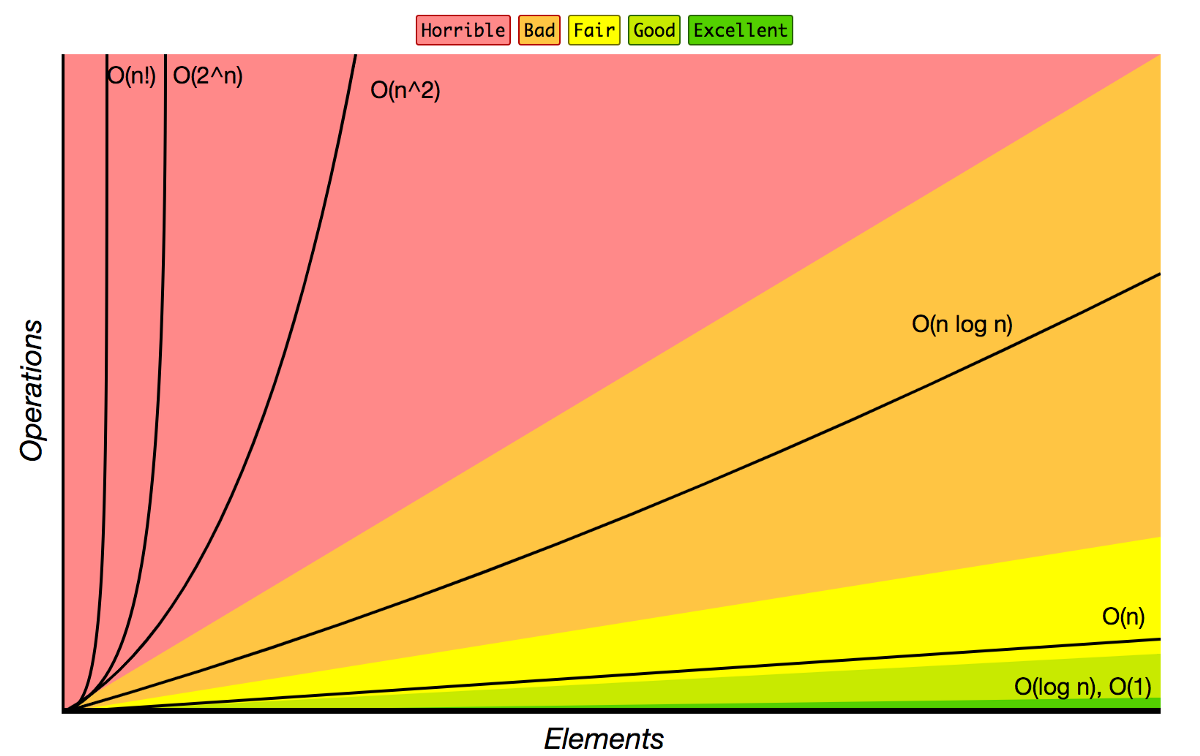
To refresh everyone’s memory, here is a graph of computational complexity. Factorial growth is obviously the worst growth pattern, so bad that with only 60 elements, you can end up with 60! ~ 10e82 which is the same number as the total atoms count in the known universe. Actually, there are more than 100 keys on a full size standard keyboard. So here we go, we know that a brute force approach will stand no chance of searching for the best layout.
Now let’s discuss what are some of the unique properties that might enable us to avoid some searches. Or if we view our search paths as a tree, what are some techniques that we can use to prune the tree. Or can we reduce a huge problem into smaller subproblems.
Say for example, we need to map N characters to N keys and there also exists a typing task which is a sequence of those characters which we need to enter. There must exist one or at least one layouts that will yield the shortest distance. So let’s find a random layout called L. And we can decompose the total cost into several components. In the layout, let’s start with a key say K1.
Total Distance for L = Distance (sequences that contains K1) and Distance (sequences that don’t contain K1)
To be more specific, the sequence is a simple string of characters which we can break down into pairs of characters (from, to). For example “hello” can be broken down into “he”, “el”, “ll”, “lo”. If we pick character “e” as the target, the total distance can be categorized into two groups, (“he”, “el”) and (“ll”, “lo”). The reason being now we can reduce it to a smaller problem, one that is independent and easier to compute. In Distance (sequences that don’t contain K1), it has one less key, one less position, and the sequence doesn’t contain K1.
Distance (sequences that contains K1) is not determined yet as it is dependent on the positions on the rest of the keys. This is also the part where we can potentially improve some efficiency as the frequencies are not evenly distributed, you probably have pairs like “th” much more often than “xz”. If we will be able to follow certain order (maybe by frequency) when loop through all the keys, the most influencers will be focused on first. Even if we cannot afford a full search and we still follow a strategy like breath first search, those unknowns might only contain less frequent used keys, positions and pairs which could be immaterial so it might turn out to be a good approximation.
D(K, P) = sum( D(k, p) + D(K-k, P-p) ) for p belongs to P for a given k
If we need to first and only fix one key, and this key can have certain number of positions, for each position, we can call the same function to a smaller problem for the rest of the keys and rest of positions.

By looking into this search tree, we can find opportunities for improvement. For example, In K2 layer, there should be N * (N-1) total children, but in reality, we can cascade down to layer N-2, we already see computational duplications that can benefit from memoization. For example, when we fix K1 at Pos_i and then fix K2 at Pos_j contains the same subproblem as we fix K1 at Pos_j and then fix K2 at Pos_i. How many redundant calls we can eliminate, N*(N-1) – C(N,2).
Now if we go deeper, for any given layer i, we theoretically will have N * (N-1) * (N-2) * … * (N+1-i) in the most naive way but there will be tremendous amount of redundancies. We will have (N-i) many keys that need to be mapped in the next layer.
There is an interesting property of combination. Which C(N, i) = C(N, N-i) = N! / (i! * (N-i)!). Intuitively speaking, we have N nodes in the first layer, and we can also say at the very last layers, we only need to calculate how to place that last key on the keyboard which is still N different choices. Given this symmetric property, the real execution actually has a shape similar to an envelope where the head and tail are skinny and grow as it approaches the middle.
So in layer1, there will be N = C(N,1) nodes. In the last layer, we also need only N = C(N,1) nodes. So if we are going to arrange 26 keys. The widest layer will be right in the middle. C(26, 13) = 26! / 13! / 13! ~ 10e6 ~ 10 million, this is much smaller than 26! ~ 10e26.
So the total nodes across all the layers can be summed up as:
C(N,1) + C(N,2) + … C(N,N) = 2^n, actually the complexity is exponential rather than factorial. This is a huge progress by just using memoization.
As you can see, this only includes the recursion part, it still has not included the known key part. As we fix more and more keys, it position will need to propagate back to the previous layers to update the distance. So, let’s think about how complex that will be.
When we fix one key, the typing pairs related to that one key will be stored separately and excluded from future recursive calls, and its value can only be gradually updated as more and more keys got fixed.
In the first layer, we have N positions, and all those N branches share the same characters pairs as they are the same subset related to the key that we are fixating. The only difference being that key is being stored at different positions.
In the 2nd layer, we have N – 1 positions left with N – 1 characters. And we fix another key, as we are positioning the second character at N -1 positions, it will go back to the previous step and being able to calculate the distance with pairs that contain these first two keys. In reality, we will have N*(N-1) different unique position pairs that we will be able to populate. There is an interesting property here as switch the position between two keys won’t change the distance, so in reality, we only need to calculate N*(N-1) or C(N,2) positions pairs. At the same time, it will identify and include all the pairs with key2 (without key1), store it at this layer and send the rest of the pairs (without key1, key2) to the next layer.
In the 3rd layer, we fix another key with N-2 positions available. As we now have the 3rd key positioned, it will send its position to the previous layers. It will not only send its position to the 2nd layer so the pairs with key2, key3 can now being computed, and theoretically speaking, there is also C(N,2) positions or pairs that we need to calculate. Also send back to the first layer so key1 and key3 and also now being computed. So the total is C(N,2) for key1 and C(N,2) for key2, which the total “call back” are like 2*C(N,2).
So on and so forth, we can calculate the total work for this kind of call back
Total Call Back = 1 * C(N,2) + 2 * C(N,2) + … N * C(N,2) = (1+2 + … + N) C*(N,2) = (1+N)*N/2 * N * N (N-1)/2 ~ N^4
Comparing with the recursively calls 2^N, N^4 is still polynomial and its computational complexity is probably so small that can be ignored as we increase N. (eg. if N=30, 2^N=1B, and N^4 < 1M).
Thoughts:
- Is there something else that we can leverage by looking into the properties of our specific problem?
- As we are searching for the minimum, there could be cases that we might be able to prune the a whole branch of tree if there are cases that “we have not arranged these keys yet, but assuming that they all share the same possible minimal distance, the sum still exceed our record minimum, then we can give up those branches completely”.
- Looking into the distance calculation, it is strictly looking up spatial distance in a 2D Euclidean space through like a distance matrix, if that is the case, is it possible to vectorize some of the calculations so we are not going to boring for loops to improve efficiency.
- Taking legacy QWERTY layout into consideration, a complete different layout without material improvement won’t be well accepted. Is it possible that we start with qwerty and then switch keys 1, 2, 3 at a time so the majority of the layout stay intact but we find the ones that with the highest return on investment given the minimum amount of changes.
- There are many other approaches to solve NP-hard problems which I other people advised me this problem belongs to. Like certain type of heuristic search, simulated annealing, genetic algorithm or different types of reinforcement learning. Those all will be interesting topics to look into.
Before we think about how to find a better algorithm, this is actually already too much talk and we better off write some program to evaluate our reasoning making sure it is not flawed. In the next post, we will be writing some programs and validate many of the statements here.


















