I want to install Spark locally, in that way, I can easily try out the SparkR package without worrying about breaking the team cluster.
There are a few things that you need to know and prepare beforehand:
- Spark was originally written in Scala which need JVM, so be ready to set up a Java development environment and you also need the Scala interpreter if you want to build everything from source code.
- I was installing Spark from source using Maven. I am not a frequent Java developer so my maven version got out of date 3.0.3 where it requires minimum 3.0.4 to work. I followed this tutorial where downloaded the latest maven and modified the softlink of /usr/bin/mvn to point to the latest maven.
- Spark is not a small application, which means that you need to optimize your jvm limit. It gave me the “memory error” a few times until I switched off most of my apps and increased the Java heapsize.
- There is a fantastic series of videos where one of them really walked through the installation in detail.
- IT IS GOING TO TAKE A LONG TIME.
Overall impression, the setup was pretty easy, probably due to the fact that I have installed Scala and built some other projects from sources before, so the environment was almost ready. The building process `mvn -DskipTests clean package` took quite a while to download all the dependencies and the whole process took about minutes to finish after I changed the Java heapsize ot be 1GB.
For later reference, there was a list of projects printed to the screen following the building order while compiling. It was quite interesting to see that Spark is already well connected with whole Hadoop ecosystem.
$ mvn -DskipTests clean package
..
Found 0 errors
Found 0 warnings
Found 0 infos
Finished in 1 ms
[INFO] ————————————————————————
[INFO] Reactor Summary:
[INFO]
[INFO] Spark Project Parent POM ……………………… SUCCESS [ 4.261 s]
[INFO] Spark Project Networking ……………………… SUCCESS [ 10.123 s]
[INFO] Spark Project Shuffle Streaming Service ………… SUCCESS [ 5.928 s]
[INFO] Spark Project Core …………………………… SUCCESS [03:23 min]
[INFO] Spark Project Bagel ………………………….. SUCCESS [ 20.073 s]
[INFO] Spark Project GraphX …………………………. SUCCESS [05:43 min]
[INFO] Spark Project Streaming ………………………. SUCCESS [08:31 min]
[INFO] Spark Project Catalyst ……………………….. SUCCESS [11:37 min]
[INFO] Spark Project SQL ……………………………. SUCCESS [15:13 min]
[INFO] Spark Project ML Library ……………………… SUCCESS [20:38 min]
[INFO] Spark Project Tools ………………………….. SUCCESS [ 39.707 s]
[INFO] Spark Project Hive …………………………… SUCCESS [14:10 min]
[INFO] Spark Project REPL …………………………… SUCCESS [03:11 min]
[INFO] Spark Project Assembly ……………………….. SUCCESS [06:22 min]
[INFO] Spark Project External Twitter ………………… SUCCESS [ 36.120 s]
[INFO] Spark Project External Flume Sink ……………… SUCCESS [ 45.845 s]
[INFO] Spark Project External Flume ………………….. SUCCESS [01:17 min]
[INFO] Spark Project External MQTT …………………… SUCCESS [ 43.300 s]
[INFO] Spark Project External ZeroMQ …………………. SUCCESS [ 39.041 s]
[INFO] Spark Project External Kafka ………………….. SUCCESS [01:59 min]
[INFO] Spark Project Examples ……………………….. SUCCESS [11:35 min]
[INFO] Spark Project External Kafka Assembly ………….. SUCCESS [01:21 min]
[INFO] ————————————————————————
[INFO] BUILD SUCCESS
[INFO] ————————————————————————
[INFO] Total time: 01:49 h
[INFO] Finished at: 2015-04-17T01:14:42-05:00
[INFO] Final Memory: 77M/829M
[INFO] ————————————————————————
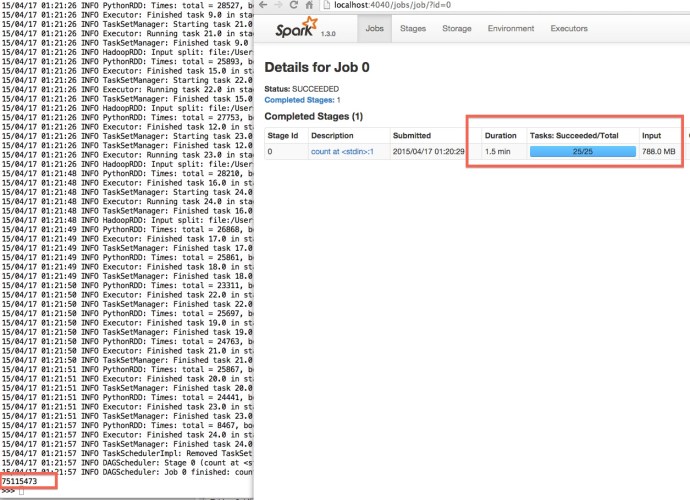
After two hours, it took me 1.5 minutes to count700MB file 75 million rows.
(it took me almost a millin to count using ls and 13 seconds to use Python std…:( )
TODO: performance tuning.