WAV (WAVE, waveform audio file format) is one of the most popular audio file formats out there. Understanding how the format is structured, how the data is stored is the key to understanding audio. This blog post will be my study note of the file format and a deep dive into a WAV file by looking into the hex code.
Here is the wiki page of what WAV is in general, and here is another tutorial from topherlee that really mapped out the file structure of a wav file. You can download a free sample wav from a site called wavsource for later analysis. (I downloaded the about_time.wav from here).
1.View Binary File
First, we need to figure out a way to view binary files, there are so many tools out there but I found a really cool way from stackoverflow. If you open the file in VIM, it will look like this:

Then you can run the command :% ! xxd, you will have a view like this:
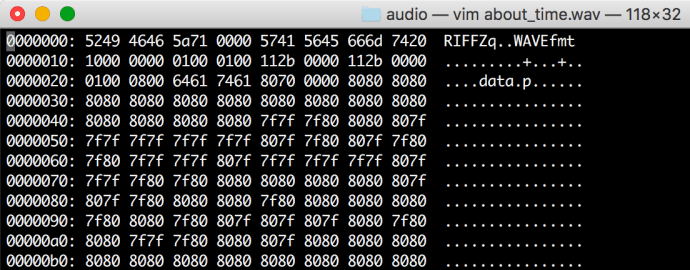
This is not something magical about VIM, it is because there is a command in Linux called xxd that most people don’t know, it is out of the scope of this post to dive into xxd, however, that online is all you need, to quit the hex view, you need to run `:% ! xxd -r` and you are good to go.
2.Understanding format header
Like most of the file format, the first few bytes are about the metadata header about the file, I found this really helpful website soundfile.sapp.org that explained the structure of the wav format. The following image shows the canonical wave file format in a simple way.

Attached is an image that I made 🙂 that explained every byte in the WAV file.

- 10 00 00 00 (little endian) ~ 00000010 (hex) ~ 16 (dec): subchunk 1 size
- 0100 (little endian) ~ 0001(hex) ~ 1: audio format PCM
- 0100 (little endian) ~ 0001(hex) ~ 1: channel number:
- 0100 (little endian) ~ 1 (dec): sample rate
- 0800 (little endian) ~ 8(dec): bits per sample
- 80 70 00 00 (little endian) ~ 28,800 (dec): subchunk 2 size
A quick summary of the all the metadatas
- channel: 1
- file size: 29Kbytes
- 8 bits per sample
- PCM audio format
- sample rate: 11, 025 (samples per second)
- byte rate: 11,025
A few interesting math equation to help you understand those terminologies better:
- Bytes Rate = (Sample Rate * BitsPerSample * Channels) / 8
3. Understanding data format
First we need to refresh our freshman memory, what is a “signed short”, short is simply a two bytes representation of a number, not as a long as four bytes integer, but good enough to represent our audio data, 16bit! that is all we need. For signed short, a positive integer will be the way it is, however, for negative numbers, it will be its two’s compliment. So what is a “two compliment”? it is simply to subtract the absolute value of the negative number from the range, in this case is 2^16, i.e the signed short of -N ~ (2^16 – N).
For example, -32640, signed short will be 2^16-(32640) =32896 (decimal) = 1000,0000,1000,0000 (binary) = 8 0 8 0 (hex).
One more example, 32639, signed short will be 32639 (decimal) = 0111,1111,0111,1111 (binary) = 7 f 7 f (hex).
Now after understanding how to map a number between (-32,767, 32,768) to byte codes on the disk/memory. We can start looking into the data.
Here are some Python code to read in the WAV file and extract the data part out.
 Looking into the data, we can see the first 14 samples are all -32640 and then the 15th sample changed to 32639. So based on the examples above, we know the bytes representation of -32640 is 8080(hex) and 32639 is 7f7f(hex). Now we might need to revisit our VIM xxd representation of the raw WAV file. We have covered the metadata part of WAV file, and starting from the data chunk, we can clearly see ‘8080’ repeated by 14 times and then 7f7f, so on and so forth.
Looking into the data, we can see the first 14 samples are all -32640 and then the 15th sample changed to 32639. So based on the examples above, we know the bytes representation of -32640 is 8080(hex) and 32639 is 7f7f(hex). Now we might need to revisit our VIM xxd representation of the raw WAV file. We have covered the metadata part of WAV file, and starting from the data chunk, we can clearly see ‘8080’ repeated by 14 times and then 7f7f, so on and so forth.
haha, now we understand all the nitty-gritty details about WAV, let’s take a look a data part and have a more intuitive understanding of “about_time”. The length of the data is 14400, which means 14400 samples and 16 bits each sample. In section one, we know the sample rate is about 11025 samples/second, theoretically, the total length of the audio file should be around 14400/11025=1.3 seconds.
TODO: the actual length of about 3 seconds, something is wrong here.
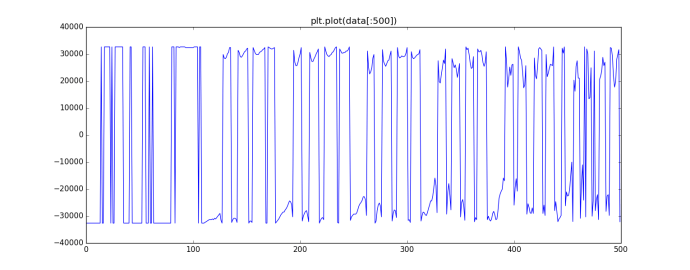
Here I am plotting the first 500 samples and you can easily see the sound, a few tips to interpret the lines, really high and really low means loud, really “dense” means high frequency, ie, high pitch. Of course, this is not a single sound, but a mixture.
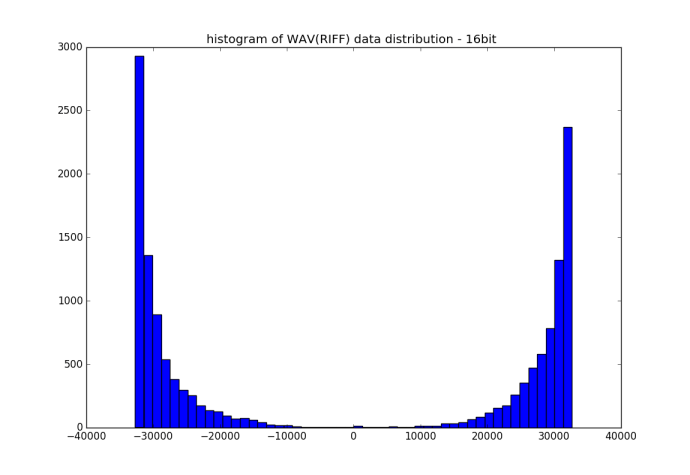
Here is a histogram of all the sample values distribution. I don’t quite understand what exactly does the value mean, the magnitude of the sound? If that is the case, does that mean most of the values are too loud? and too quiet? I assume in this case, it is simply the vocal of a male reading some words, mostly it will either be the guys voice and the quiet moment…
TODO: need to look into what does (-32,767, 32,768) mean?
In the end, here is a spectrum graph where I borrowed the source code mostly from here.
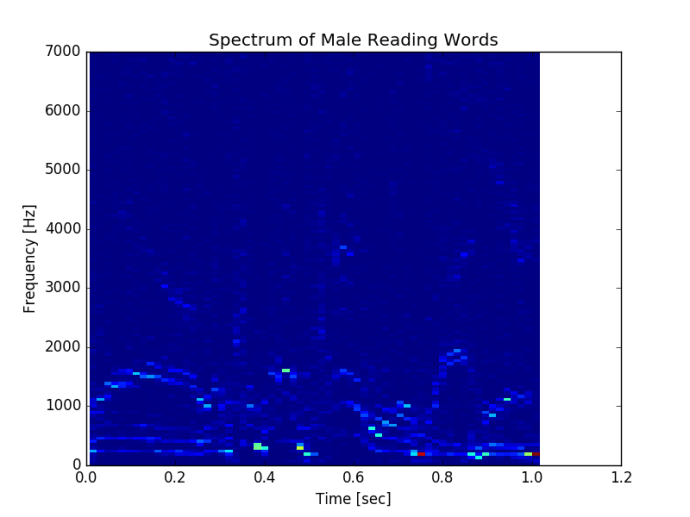
well, this is what I have done and need to do more research and have a better intuitive understanding of what everything is.
