This is a video that I took with startcraft II in ultra setting running in the Cloud thanks to Geforce NOW.
First, here are some “lowlights” of my gaming machine:
- CPU: Processor AMD FX(tm)-6120 Six-Core Processor, 3500 Mhz, 3 Core(s), 6 Logical Processor(s)
- GPU: GTX 1050ti (upgraded)
- Memory: 16 GB (upgraded)
Now, let’s get to my experience of how Geforce Now surprised me.
I came across an activation code in my email inbox that Nvidia actually granted me the access to the Geforce Now free beta. I decided to give it a try and it turned out the experience was fantastic. In essence, it is to off load your gaming machine from doing all the heavy computing, instead, run the game on Nvidia hosted virtual environment and of course, you have to have reasonable and stable network to get the full value of it.
My office is in the second floor and the router is on the first. The wireless internet connection is mediocre so this test isn’t really the best representation of the full capability of Geforce Now. I am tested Starcraft II, Diablo III and battleground and all three of them performed really well.
The lagging is minimized to the internet connection, for Starcraft II players like me who doesn’t have a 300 APM, that lagging is trivial and doesn’t now really impact the gaming experience, but I am assuming if you are playing with any competitive shooting game, that few ms might matter. Anything else should be perfectly fine. I even bought battleground on the fly because my computer was never capable of running it and now I can play it on the Cloud, I spent quite a few minutes just staring at the sky rendered by those crazy machines in the cloud.
I see this literally as a game changer because by pooling all the gaming computing power into one centralized place, this should theoretically drop the total costing of each household spend thousands of dollars on getting the best gear on their own. However, I don’t think a company is running a charity but to maximize their shareholder financial benefits. As an end consumer, I know that the internet is getting faster and better (like 5G), if Nvidia is asking me should I buy a gaming PC or use their service, I might be willing to pay the subscription to play Geforce Now if the monthly subscription fee is close or lower to the monthly depreciation of the hardware.
Say a gaming machine is $2,000 and you expect to get the full usage of it and replace in three years. 2000/3/12 ~ $55/month. Of course, you don’t buy computers only to play games but for many gamers, they do upgrade their gear only because of gaming performance. Also, take into consideration that you can unsubscribe if you are taking a long vacation or busy working, it pays back.
Anyway, good job to Nvidia as usual and this made me wonder if our next generation will be asking the question “hey, daddy, what is that big black box? shouldn’t everything run on a TV directly?” 🙂
Download Geforce Now beta test
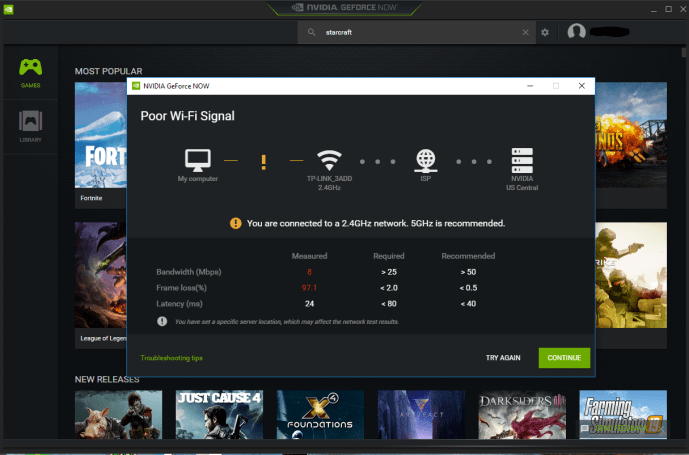
Run a test. My internet is on the low end and far from the router but still working.

Looks like from this step, it is already running on a Windows virtual machine. I am assuming they are collecting all the information like IP address, hardware spec in order to align the cloud resource to be best compatible with the consumer terminal.
Works perfect for me.