One will be so humbled if you don’t take everything for granted. In this post, we will look into a basic yet fundamental Browser operation – Selection.
Selection is probably an operation that most people learned even when they were a child, literally. You were taught to use the mouse to select the area of content by starting to hold the left key, move to cover the area that you like to select and end by releasing the left key.

Your selected text is an object called Selection and there are so many ways to access it and one way is by calling getSelection.
By reading the definition of Selection, we also learned that it not only covered the pointer selected range, can also include the text selected by moving the caret. 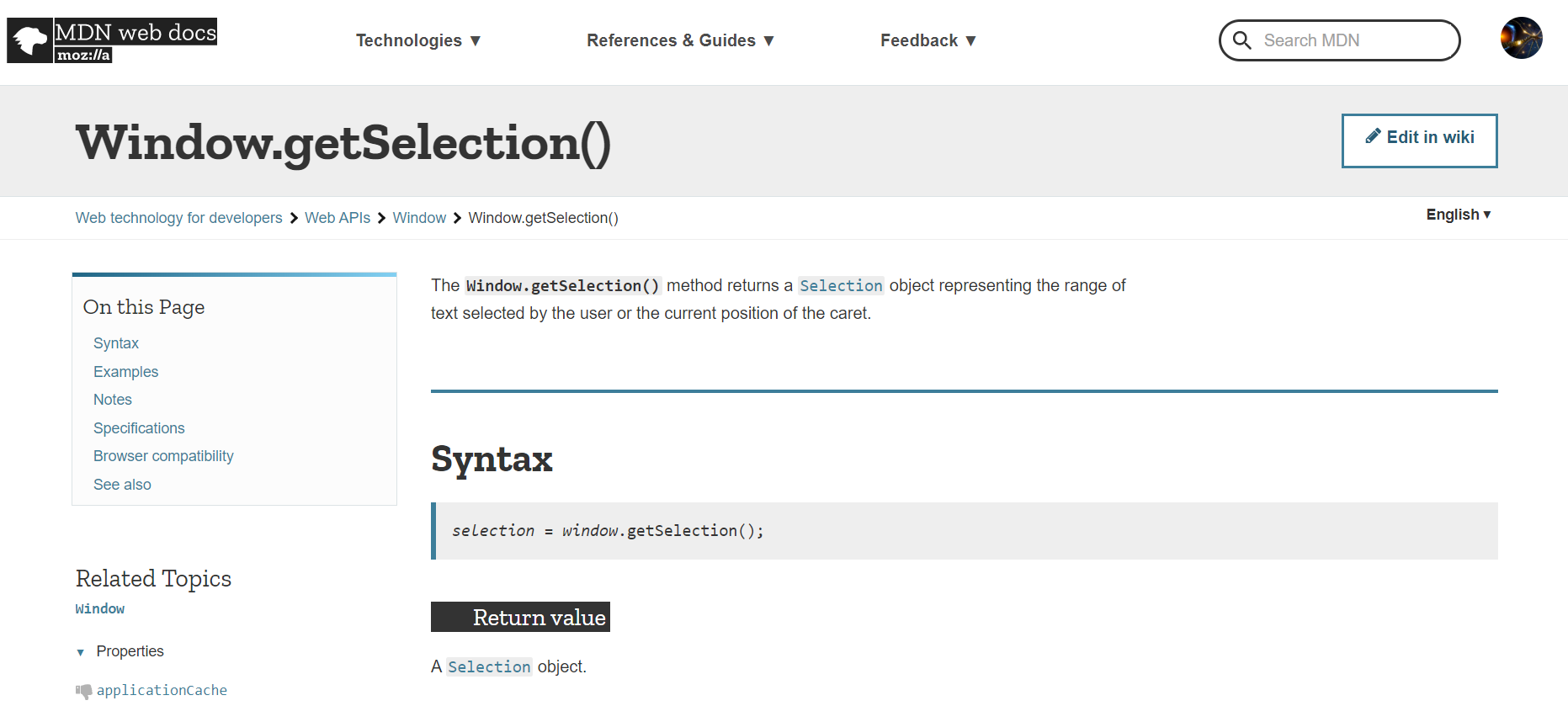
Based on the definition, there are two key concepts that constitute a Selection, one is called the anchor (start) and the other is called the focus (end). And here, we are going to disassemble a selection object and learn that way.
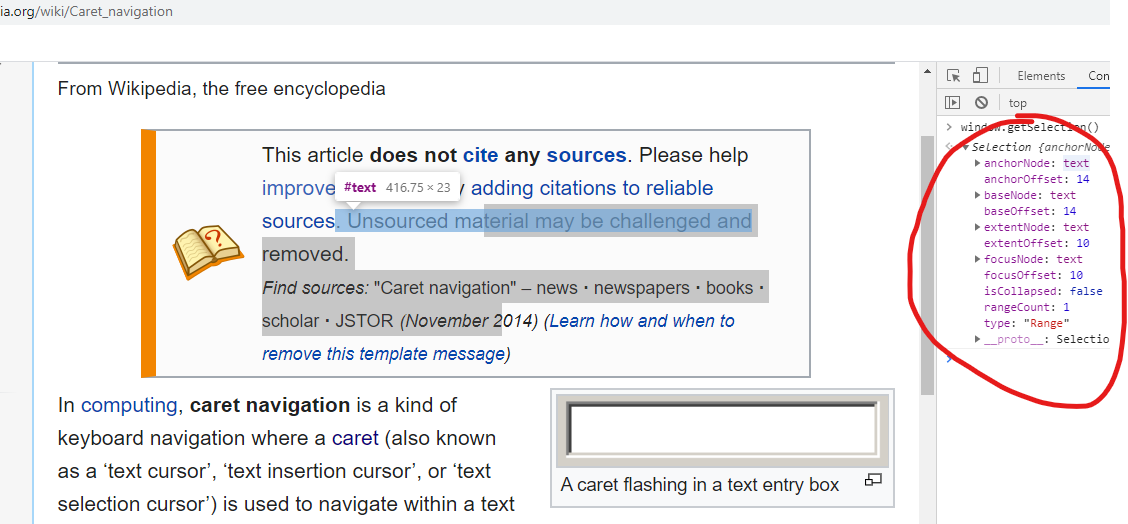
Here I highlighted some text in Wikipedia (grey area as now the focus is in the developer console from “terial may..” to “November 2”.
anchor
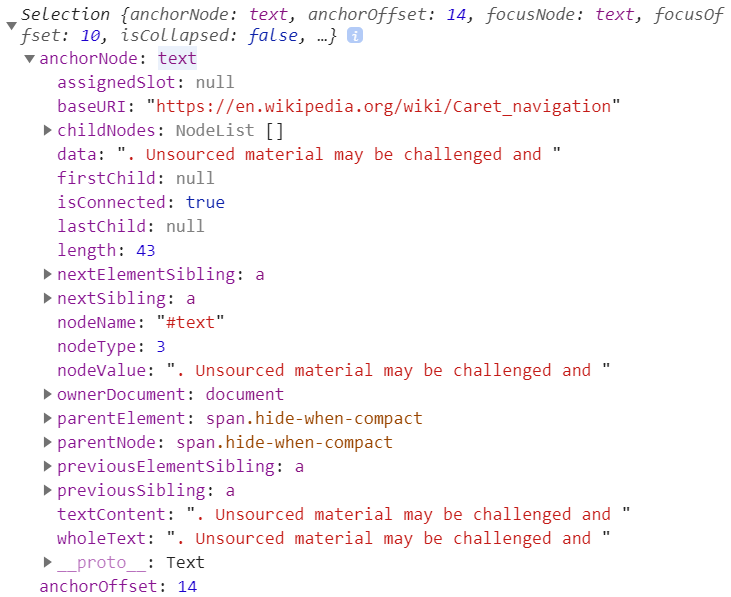
At first glance, there might seem like overwhelming amount of information but just like any class, once you have seen it more, things become easier and easier. Actually, archorNode is a simple object of the most common class – Node.
Also, anchorOffset stores the value of 14. Because our anchorNode is a text, 14 is simply the number of characters inside the text, to mark the exact position. As previously mentioned, our selected text starts at the charcter “terial..” and the character before it “a” is the 14th character in the string so that makes sense.

focus

for baseNode and extendNode, they look like concepts only available in Chrome and just aliases for anchor and focus [source].
HTML
Here I took a screenshot of the snippet of the HTML code. The anchor node and focus node are both highlighted in yellow. Now it is even easier to put the previous concepts into the context, like why the anchor node is a text, that its previous and next siblings are both hyperlinks and its parent is a span, etc.

Dynamic
One interesting observation when playing with the Selection is that the Selection objection is dynamic or always referenced to the current selection by the user.
For example, in the following exercise, I create a variable called s by calling window.getSelection(). All of attributes are either null or 0 as the default value because I have not selected any content. Then I start clicking around on the web page and the selection object got updated to the position where I clicked.
As I have mentioned previously, a caret movement is also a type of selection and a click will move the focus to certain position, and you can almost think it as a area of selection where the anchor is the same as the focus.
Of course, when I select an area, all the attributes of the selection object got updated accordingly.
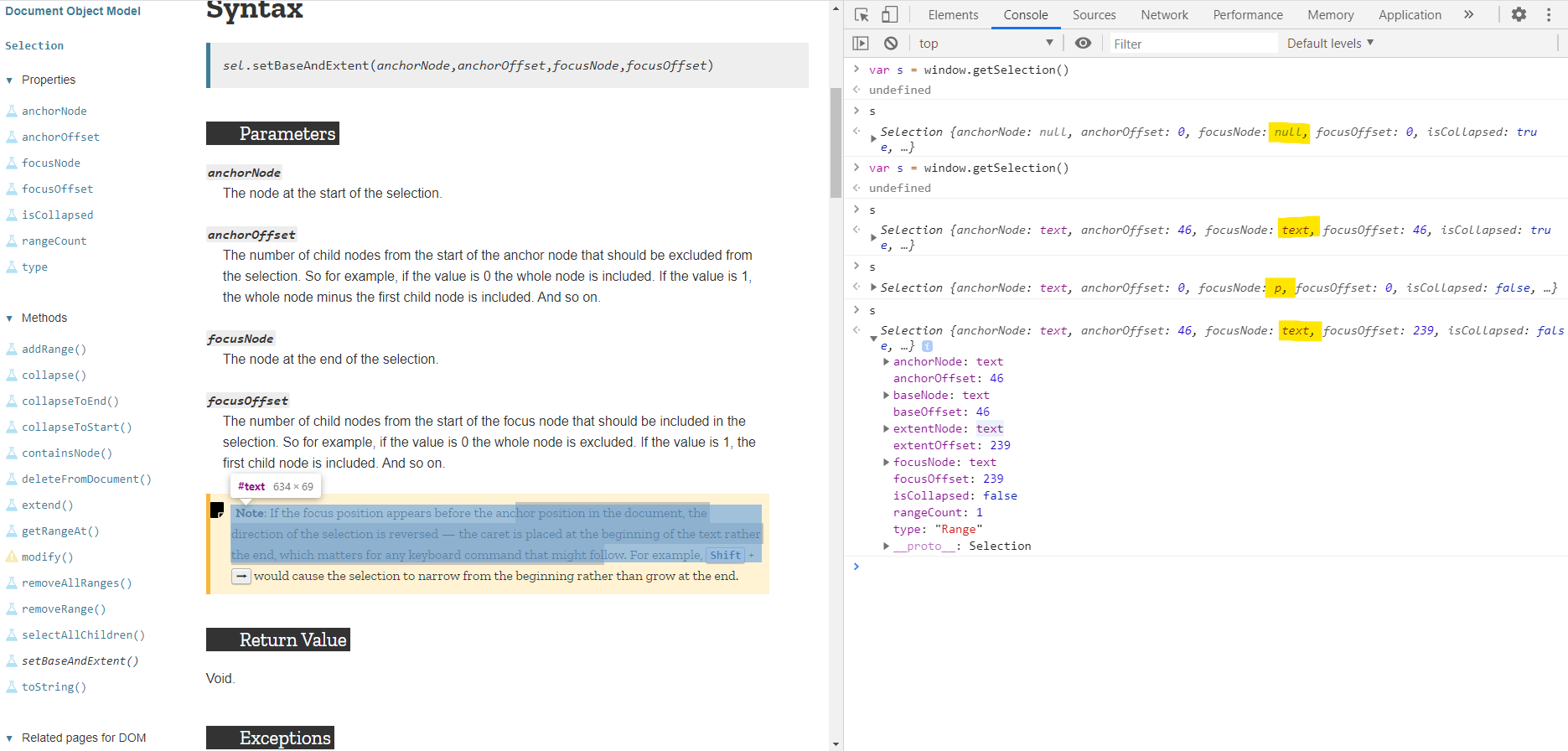
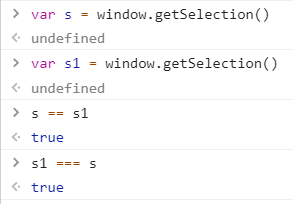
So do all the roads lead to Rome? I created two variables s and s1 and by using the equal and strict equal, clearly they are referencing to the same object as both condition are true.
“If both operands are objects, return true only if they refer to the same object.”
– Mozilla
Selection Constructor
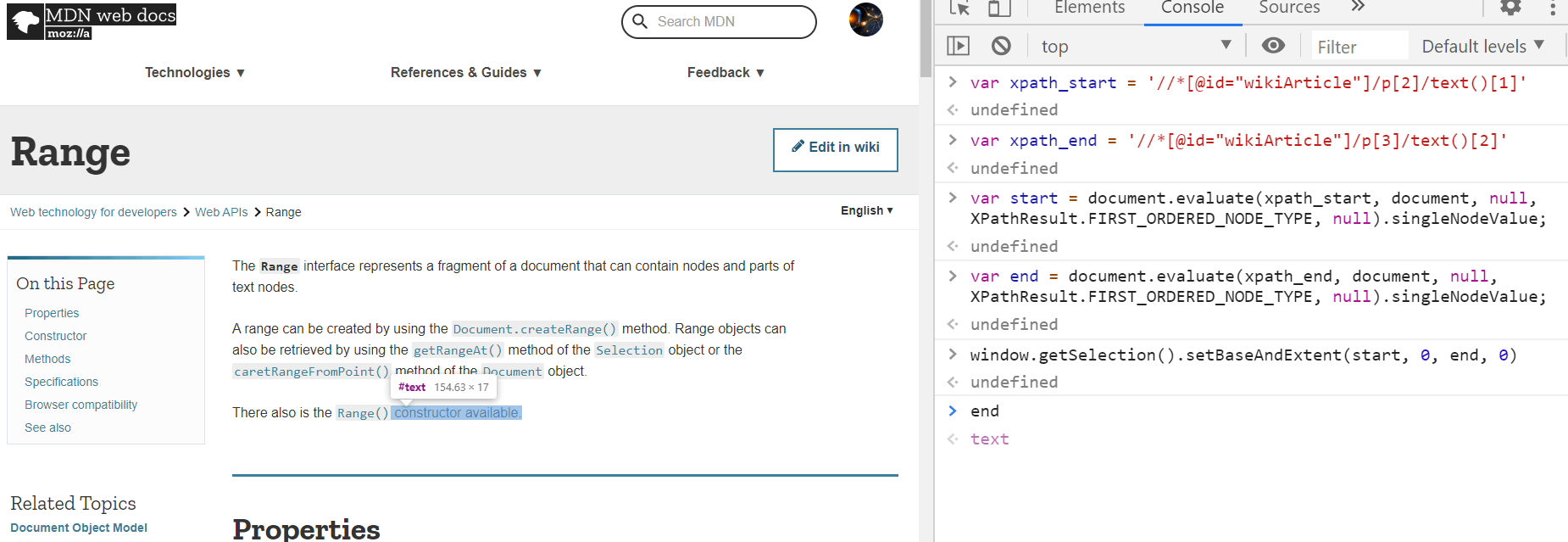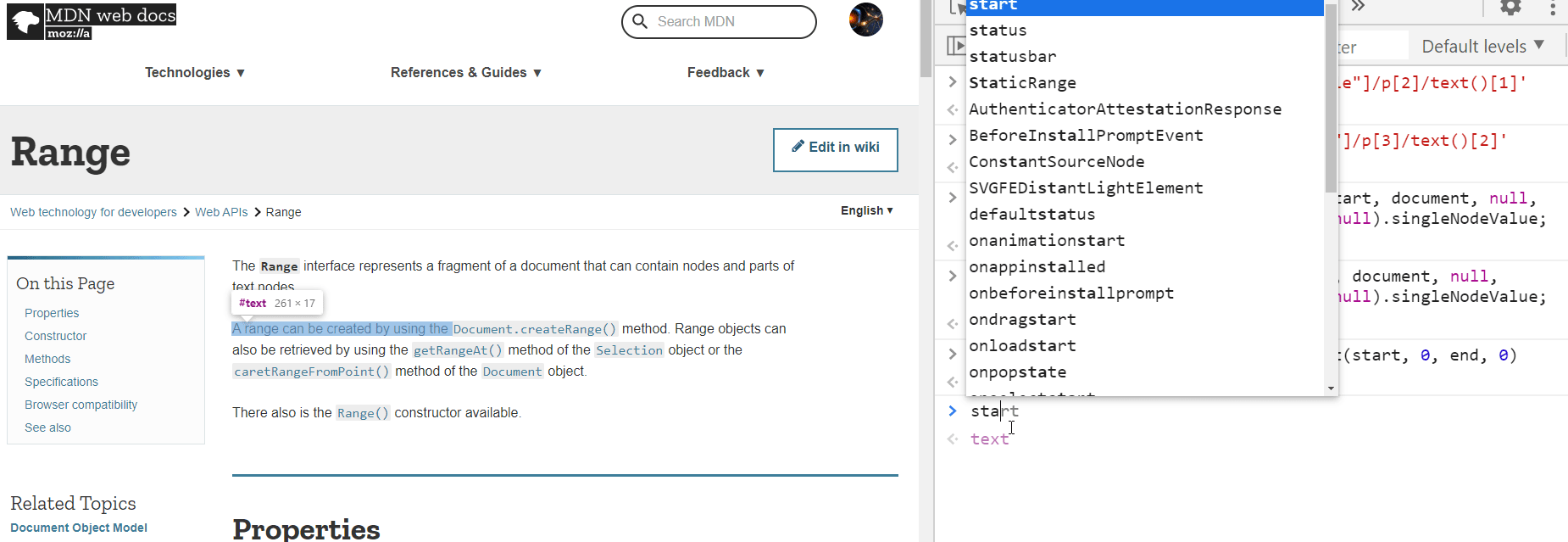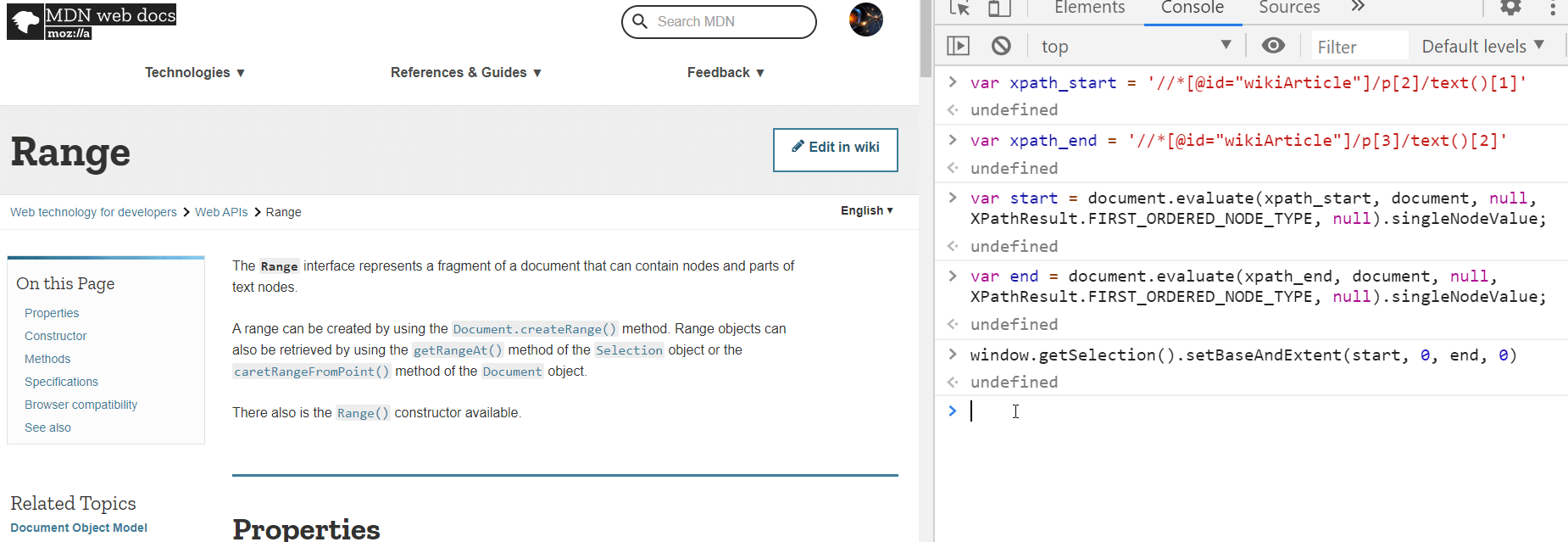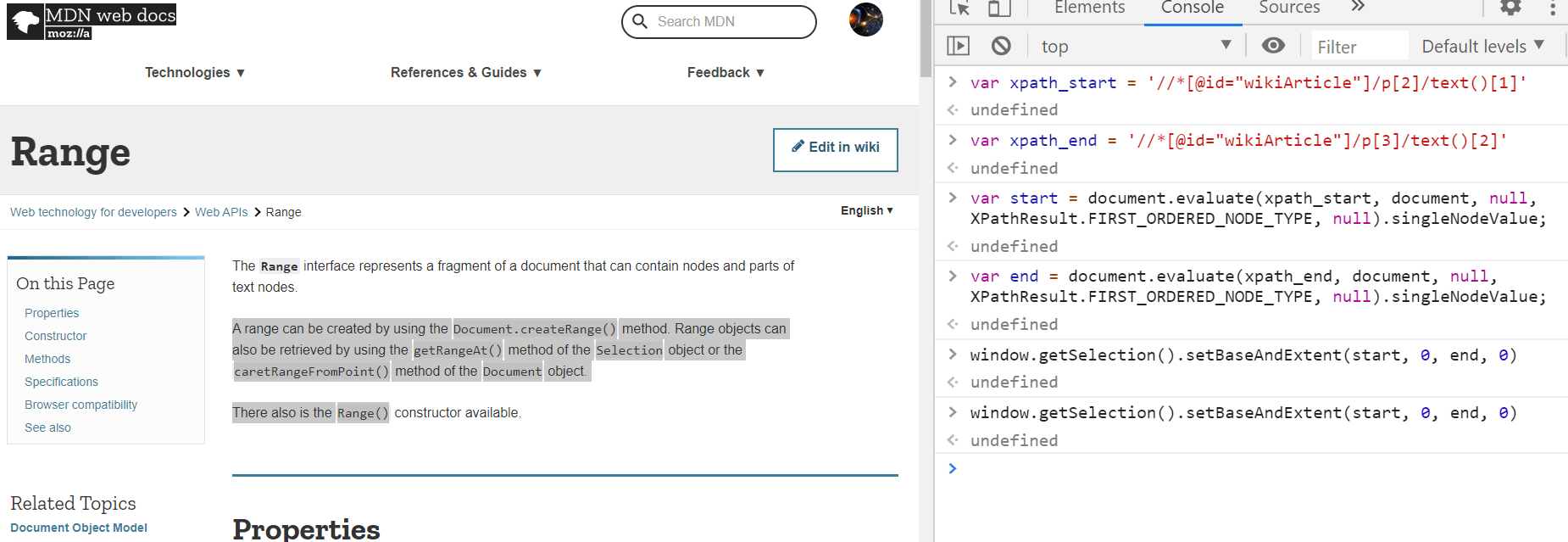
At first glance, it looks like Selection only needs a anchor, focus and the corresponding offsets if they are texts. To confirm our understanding is right, let’s try if we will be able to code a Selection object from scratch, rather than select by mouse.
In the following screenshot. I select a position and stored the anchorNode and its offset as anchor and anchor_offset. They two variables preserve the start position so I can use it later. Then I did the same thing to store the ending positions into focus and focus_offset. In the end, I called the setBaseAndExtent to assign the selection start and end to be those two positions and magically, all the content between those two positions got highlighted. It is working!

Through this exercise, clearly there are two types of variables that worth mentioning, variables like s that will change as the user change, instead of the value, it preserves the reference, a linkage to another variable or object that constantly changes. There is another type of variables like anchor, anchor_offset, focus and focus_offset that once being created, it took a “deep copy” of the start and end position, and regardless of how s changes, those variables are intact.
The explanation of that question goes beyond the scope of this article but here are two blog posts that helped explain assign and copy.
Now we have a good idea of how Selection work, even able to recreate a Selection ourselves programmatically, the next question will be can we memorize the selections and store it somewhere for future use? Almost use selection like a highlighter?
Multiple Selection
Multiple selection appear in several scenarios, like you can select multiple icons on your Desktop by holding the Ctrl key and then operate in a batch fashion. In Microsoft Excel, you can do something similar too. In a Browser, can you remember if you have ever selected multiple paragraphs at once? If your answer is no, you are not alone.
A selection object represents the Ranges that the user has selected. Typically, it holds only one range, accessed as follows:
var selObj = window.getSelection();
var range = selObj.getRangeAt(0);
selObj is a Selection objectrange is a Range object
As the Selection API specification notes, the Selection API was initially created by Netscape and allowed multiple ranges (for instance, to allow the user to select a column from a <table>). However, browsers other than Gecko did not implement multiple ranges, and the specification also requires the selection to always have a single range.
Firefox is a Gecko based Browser and by holding the control key, you are actually able to select multiple ranges and access the different ranges through getRangeat(index) method.

Given that, we probably need to be careful of how we frame our discovery, in this case, I still will prefer to say that there can only be one Selection at a time, it is updated automatically as the user changes. However, one selection can includes multiple ranges.
Now we understand that Selection is almost a set of Ranges, it can include none, one or many.
The Range interface represents a fragment of a document that can contain nodes and parts of text nodes.
A range can be created by using the Document.createRange() method. Range objects can also be retrieved by using the getRangeAt() method of the Selection object or the caretRangeFromPoint() method of the Document object.
There also is the Range() constructor available. <- highly recommended example
By reading through the documentation of Range, we see the Range has more methods than just Selection, it not only has the methods of start and end, instead of anchor and focus but also methods related to clone, insert, rectangular and many others. This is to demonstrate that we could store the Range instead due to the benefit that the Selection got auto updated all the time but the Range that it includes can be easily copied.
However, we copy the state of range not only for preservation across the lifecycle of the active tab. We want to put it into a database on disk, send to an API and want to store it for eternity.
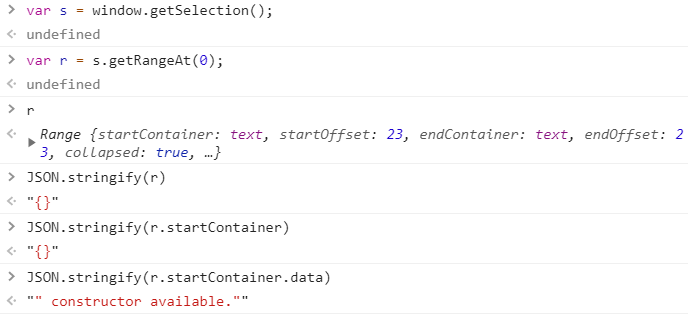
Here, we not only have a difficult time preserve the Range object, even the startContainer cannot be serialized. This is new and interesting to me. In my opinion, there should be a way to just save the object as is, all the attributes, everything. It means next time, I don’t even have to worry about the construction process and can just use AS-IS (like Python Pickle). Is it efficient, of course not, is it easy? to certain degree.
The second approach is to keep going down the dependency tree.
Can we easily store Selection? No, let’s go Range.
Can we easily store Range? No, let’s go startContainer.
Can we easily store startContainer? Maybe.
By reading through the documentation, we know that a container is a node itself. Once you can store the node, you can even by pass range and build the Selection directly. It is such a fundamental concept now and it might even worth to go through the documentation of Node and research what is the unique identifier for a node that we can use to recreate it from stored data.
Node is a very important concept in Javascript. All the Browser operations center around locating and manipulating certain objects within the page. That can be translated into locating certain nodes and do something with it. By reading through the documentation, the Node interface sort of got abstracted further, to a level where most regular end users (like the regular Joes who use Internet Explorer) won’t recognize it has anything to do with Browsing, because it is closely coupled to the underlying data structure, tree navigation.
Most of its methods are related to its relative position within the tree, the parent, the children, the sibling, etc.
The good news is that there are many ways to locate a Node within the DOM tree, like by its path from root, like by its tag name, by its relative position, by its class name, by its unique id, by its text, ..etc. I don’t believe there exists a way to uniquely identify a node because the DOM tree itself can get rendered differently based on different situations.
There are many ways of construction a XPath from an Element and also many ways of locating an Element from a given XPath. The content related to XPath is fascinating but the amount of information required to cover easily exceed the scope of this blog post. We will have a separate article related to XPath but for now, let’s assume that we are in a good shape.
Conclusion
The XPath was built using the Chrome Web Developer Console as there is an option called copy xpath for any inspected element.
Hopefully this post has helped some of you better understand how the selection and range object works.