The training of stylegan2 probably accidentally defied the purpose of open source as it requires so much computing power, so much to a level that the regular joes won’t even come close to train their own model in a way that is supposed to.
You can read about the README page from Stylegan2’s github project. It usually requires several high-performance GPUs like Tesla V100 to train for several days. And it evenFor the limited audience who happened to have access to high-performance computers like Nvidia DGX 2, The repository can be little bit daunting because there are still thousands of lines of tensorflow code that you probably need to spend a few days to dig into.
In this exercise, I will show you my experience training some images using DGX, how the experience was and what did I do to improve the through put.
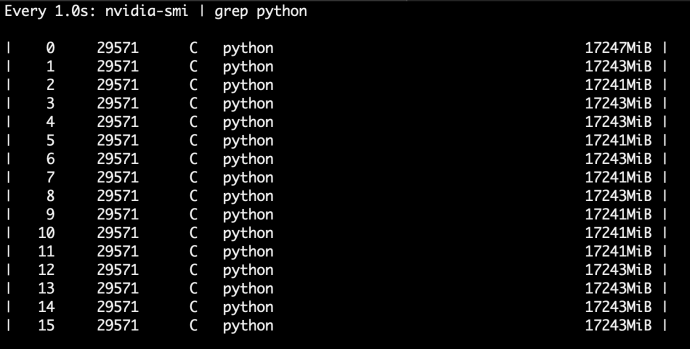
There’s one thing that I realized when I ran the training jobEste fault is thatOnly eight out of the 16 GPUs are being used. And I’ll put those eight GPUsThe GPU memory usage it’s only around 9 GB out of 32 in total for each GPU. So that as a problem, Each of the GPU is only usingAbout 20%Of its total memoryAnd only half of the GPU is being used. That is an overall memory usage of only ten percent.
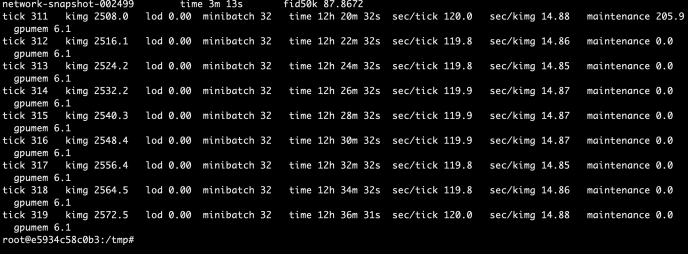
By looking into the main function of run_training.py, we realized that there isn’t really that much configuration the author mean to you to change, the only one is the number of GPUs and in the code it is limited to 1,2,4 and 8.
By further digging into the network code, we realize there are several parameters that looks interesting and promising for us to tinker with. for example, anything related to mini batch is probably a good starting point for us to try it out. in this case, I changed two parameters minibatch_size_base and minibatch_gpu_base each controls how many images to load for a minibatch and how many samples process by one gpu at a time. To be frank, I increased the value without really knowing what was going on behind the scene (minibatch_size_base from 32 to 128 and minibatch_gpu_base from 4 to 8)
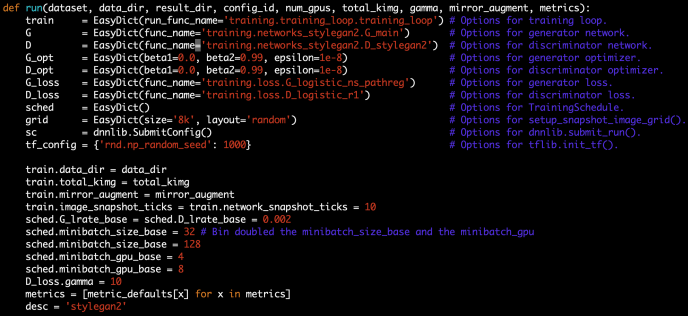
After the change I do have to say add to the beginning when the tensor flow graph was built, it took a very long time like 5 to 10 minutes, but when the training started by ticking, the throughput doubled. and the memory usage got materialy increased, like from 9 gigabytes to 17 gigabytes.
You’re might have to ask the question, Is there anything that I can do to change so that the total training time can be improved.
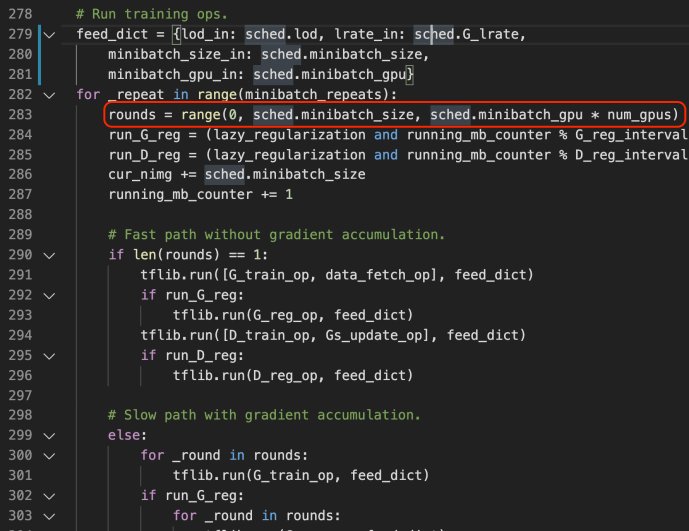

As you can tell, in about the same time, the new configuration has already reach tick 420 with about 3433 Kimg processes while the default configuration processed 319 tickets and 2572 Kimgs. That is about a 33% performance increase overall.
What bothered me a little is that as I am currently using all 16 GPUs, I expect the performance to be at least double, let alone each GPU is actually working harder now, which should add up to 4 times the amount of performance theoretically. By 33% is better than nothing.
