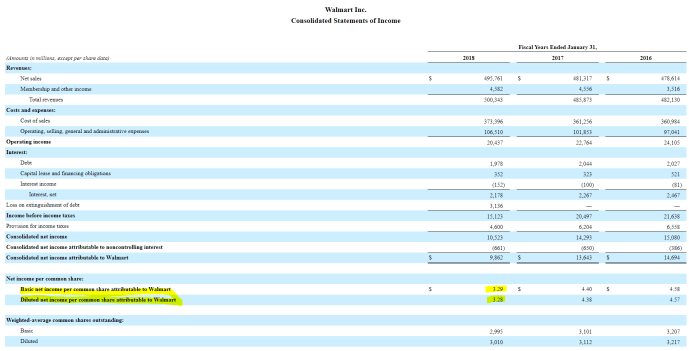
When reading about the financial statements for any given company, or any spreadsheet in general, a situation any person constantly run into is numbers are presented in a slightly inconsistent way regarding the signs (+/-). For example, if there is an expense line item, people might assume it is an expense (outflow of cash) and will present the way as is. Sometimes, people will actually consider expense is different from income and will present it in a different way from revenue by including the numbers in a brackets like (400). Things can get really complex because there are metrics derived from a series of basic metrics like net income (bottom line on statement of operations) which should be the ultimate result after adding/subtracting the relevant gains and losses. I always have a hard time by calculating the final results because the signs for each line always confuse me. In the end, I ended up playing with signs for each line with my fingers crossed, wishing that I will be “lucky” enough to make the math work.

Above is part of the cashflow statement from unaudited 10-Q for Arrow Electronics, Inc., a public listed company. They did a great job because the bottomline for the cash used for operations are a simple arithmetic sum of all the number, given you treat numbers in parenthesis as negative, hence to subtract.

However, I want to use this data as an example to see how my script will be able to “auto detect” that the numbers in parenthesis should actually be subtracted. The Python script will take a brute force approach to find the right signs for each line item in order to reach to the right “bottom line”. The idea is very simple, it will switch signs for each line (positive, negative or exclusion) until it finds all the right sign and approximate to the bottomline within certain error tolerance.
Now let’s take a quick look at the implementation.
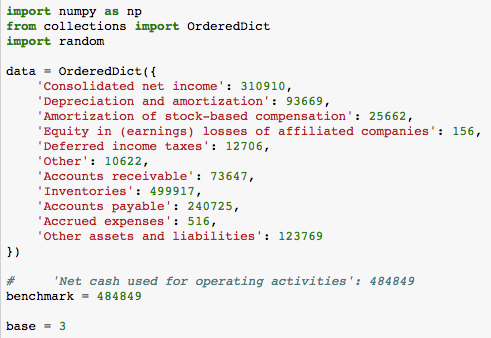
First, we load all the data points into a data structure, since we are not sure about the signs for each line, or even should we include one line item or notat all, we will treat them all the same as positive numbers to get started. Benchmark variable is the final answer that we need to match. Base variable is 3 because for each number, it can either be treated as a positive number, a negative number or not included (for example, there could be an intermediate variable. Including the intermediate variable along with all the basic variables will lead to double count).

baseN is a utility function that I borrowed from Stackoverflow, it can convert from a integer into a string format representation of any base. For example, baseN(4, 3) will be 11. We will use this function to help us loop through all the possibilities.
Then the next step is to try out all the possible combinations. Frankly speaking, I should have done way more research than I did but the first thought that came to my mind is to loop through all the possible combinations and represent the each state as a number of base 3. For example, in total, we have 11 elements. Then we have a number of 11 digits which each digital can have three states (negative, not included, positive). It can be represented as (0, 1, 2) for each state. In that case.
00,000,000,000 represents a possibility where all numbers should be treated as negative and clearly the total sum will not add up to our benchmark. Then next,
00,000,000,001 represents a situation all numbers except “Other assets and liabilities” 123769 will be negative, and only 123769 will be excluded. And of course, it will not add up.
00,000,000,002 means treat the last number as positive leaving the rest as negative.
00,000,000,010 means treat the second to the last as excluded and the rest of negative.
So on and so forth, when the number keep increasing till 11,111,111,111, then we should have iterated through all the possible combinations, hence, np.power(3, 11) ~ 177K.

Weight is a variable that stores the sign for each variable. The code is pretty straightforward and I just want to clarify that the use of np.isclose is essential because all financial statements do some sort of rounding. It will be really hard to perfectly add up all the numbers and by tuning the error tolerance will be critical, something within 1% is probably a good rule of thumb.
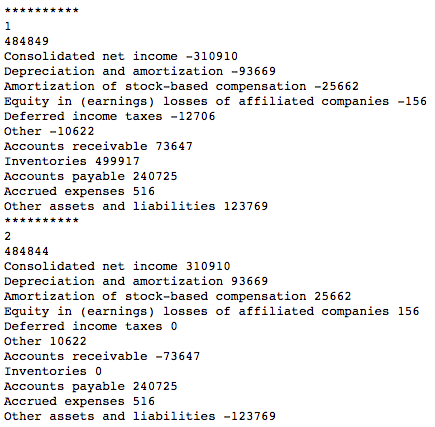
In the end, the final outcome will look like this, as you can see, since I am comparing using the absolute value, the script gives me two answers where it successfully identified the lines items under “changes in assets and liabilities” should be treated as a opposite sign as the rest of the items.
There are several limitations to my implementation just out of the box. The first one will be the scalability. The complexity of this brute force approach will grow exponentially as the number of variables increases.
Here are some interesting ideas for further exploration.
- How can you build mathematical relationship automatically within a financial statement or even across financial statement, across different years. For example, AR change in cashflow is the difference between end AR in balancesheet, ..etc.
- How can you solve the scalability issue by aggregating numbers to reduce number of variables, for example, now we can exclude all these 11 variables from future computation because they can be replaced as one variable – Net Cash used for operating activities.