Recently I have a project that I have lots of raw data (time series data), however, the output need to some higher level statistics which requires some aggregation of the raw data. So here are the choices that I have, either for every request, pull the raw data and calculate it on the fly, or preprocess all the raw data and store the stats somewhere else, so when use needs the data, then it is simply a look up.
Since the data is pretty big and updated at a daily level, batch preprocessing all the data is like boiling the ocean, and what is even worse, we need to reboil the ocean every day. There is also a possibility that the user who requested this service won’t even be able to use all that much data that frequent, which will result in a huge waste of computing power. On the other hand, calculating on the fly faces some other challenges, you need to ensure your logic is so well written and generic and will succeed for all the parts. Mostly important, the performance need to be fast enough to serve as a service. In the history, I wrote my python code in a style that “hmm, it is fast, hmm.. it is taking a long time”. Nothing more than a linux “time python script.py”. Now I face the challenge of turning whatever calculation into something that will be fast at a service level (<100ms). Have a quantitive understanding of how much time each step takes, where the bottle neck is and then we can strategically to improve certain parts without switching to other programming languages (C, Java)..
Then I learned that this type of analysis is called profiling:
“A profile is a set of statistics that describes how often and for how long various parts of the program executed.” – Python Documentation
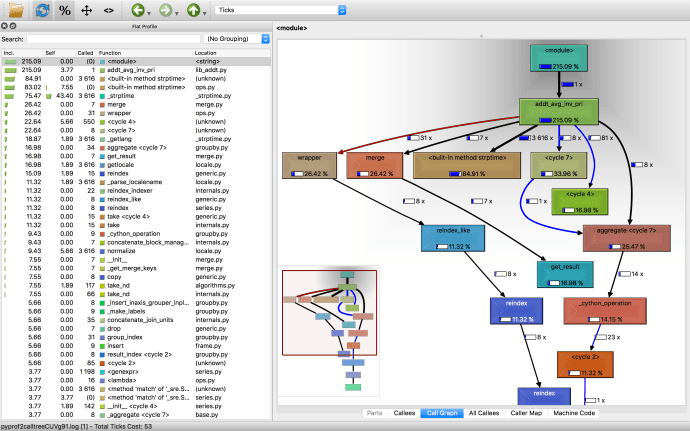
The cProfile is the de-facto profiling tool to benchmark Python code. It is not the mostly user friendly tool but once you spent some time on it, getting familiar with its syntax, then you will have a tool like linux top command but for your python code.
import cProfile
cProfile.run('range(10)')
Either the python documentation or pyMOTW can help you get started quickly. Then I came across a blog post from Julien Danjou – Profiling Python using cProfile: a concrete case which introduced me to KCacheGrind.
If you are a Mac user like me, brew install everything following this instruction.
pip install pyprof2calltree, and then you will be good to go.
pyprof2calltree -k -i file_profile
In the end, you will have a beautiful visualized way of how long each step takes.