gzip is a commonly used data compression file format. There is also an application gzip that works with this file format. Recently I came across a use case where I need to apply some data transformation to a large dataset stored in the cloud. The data is so large that I cannot fit all the raw input data to the disk, not even the output data, but compression of the output, I should be able to based on estimation. This article is to discuss some of the characteristics of gzip file in general by walking through my use case.
I thought compression is not divisible. You need to first have ALL the raw input, then you can apply the compression, the compression will analyze the global frequency and build the dictionary to encode all the data. In that case, I might be able to process the raw data little by little, but still won’t be able to fit the uncompressed output, let alone compression. However, if the compression can be done piecewise, I can process a small fraction of the input, transform it, compress it, and iterate through this process until finish and put everything together in the end. Most importantly, this means I can even parallelize.
Now the whole question depends on whether a compression can be divided. The short answer is Yes. It can be.
Gzip fileformat is defined in RFC1952.
2.2. File format
A gzip file consists of a series of "members" (compressed data
sets). The format of each member is specified in the following
section. The members simply appear one after another in the file,
with no additional information before, between, or after them.
My previous impression of analyzing frequency could be true within a member, but based on the documentation, a gzip file could be a simple concatenation of multiple gzip file where each “member” is independent. By reading through the deflate documentation, the compression is actually happening block by block, the block size can vary but when it compress, it process about 64KB input at a time.
gzip -> members -> blocks
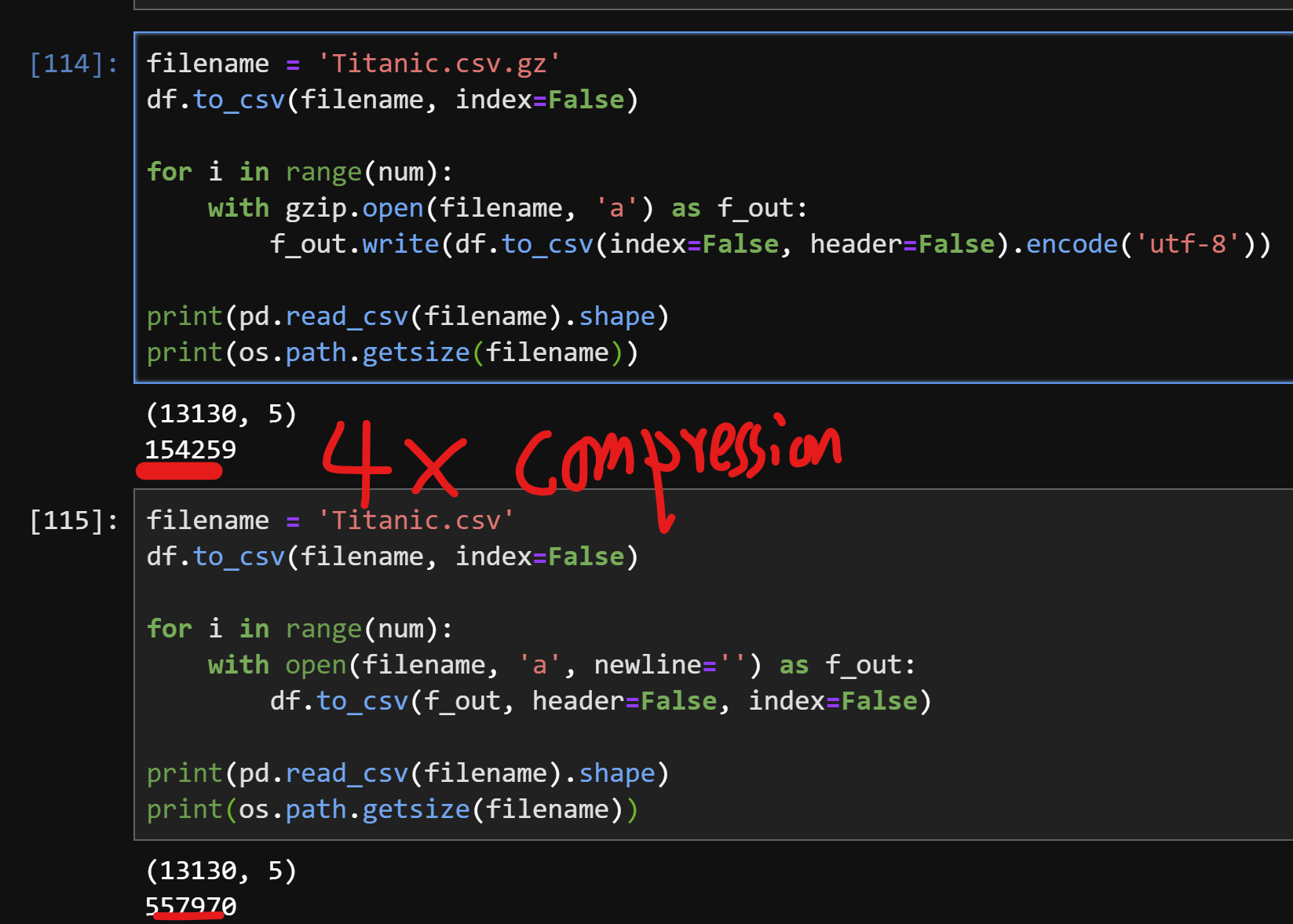
[114]. we first write the Titanic dataframe to a csv compressed in gzip format, p.s., if the file suffix is gz, pandas will autoapply compression to it. Then we created a loop to repetitively append the compressed datastream to the same gzip file.
[115]. is the same process but it is uncompressed, basically how to rbind csv files.
This code snippet demonstrated that we can keep “concatenating gzip files”. We still need to be aware of what underlying data format we are using. In this case, I am using a CSV which is very easy. The only tricky part is to make sure all the columns are consistent and you don’t mistakenly include the headers when you append data.
In the end, you have one gz file, after you uncompress it, you still have one large CSV file.
Resources:
GZIP file format specification version 4.3 Python gzip, zlib DEFLATE Compressed Data Format Specification version 1.3
