There is this very interesting post from Hackernoon where the author built a self-learning trading bot that will learn and act accordingly to maximize the reward. The post is very fun since demonstrated the learning capability under a few naive models. On the other hand, it is actually the underlying implementation that intrigued me the most which I decided write this blog and go through the notebook provided by Daniel and learn more what is happening under the hood.
Reward
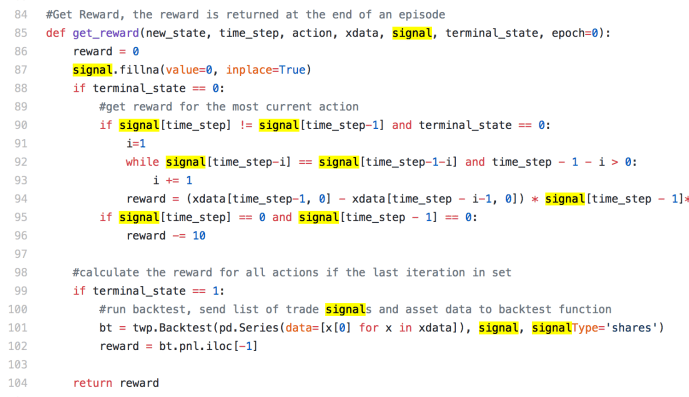
The get_reward function is probably one of the most important steps in designing a reinforcement learning system. In an trading example, it can be somehow straightforward at first glance because people can simply use the financial position ( like P&L) as the measurement, actually it is probably the one method many people will agree and adopt.
We can start by first looking into the terminal_state == 1 part of the code, which indicates that is the last step of the process. In this case, the author simply call the Backtest function straight out of box by passing in pricing information and the signal information, in this case, each element of xdata stores the state which contains the current price and the difference comparing with the previous day. Hence, [x[0] for x in xdata] is a list of all the prices. In this case, you can grab the P&L data for the last day and you are good to good. (click here to learn more about the backtest functionality within twp)
The most interesting part is actually by looking into how the intermediate steps rewards are calculated. Within the terminal_state = 0, there are two if statements all based on the value of signal[timestep] and signal[timestep-1]. Signal is “Series with capital to invest (long+,short-) or number of shares”. In that case, signal[‘timestep’] and signal[timestep-1] is the capital to invest for the current and previous step. The interesting part if the both of them are equal to 0, basically means nothing to invest, the author actually deduct 10 points from the reward variable, I think this is to penalize the activity of doing nothing probably. Then, the step of where the signal for today and yesterday are different, this is probably the most challenging part of this reward function.
It built a while loop and go backwards in time to compare the two consecutive days of signal until they are equal. Actually, if the previous step and the one before it happen to have no change. Then i = 1 and it jumped out of the loop and stays at 1. However, if this is a very active investor and every day is different. i could increase to be as large as timestep – 1. The code screenshot got cut off and here is the complete code for line 94.

Here I am having a hard time understanding how this reward function is established. I can understand the price difference part. And multiply by the number of shares gives you basically the profit, or loss if there is a price drop. At the beginning, I thought the author must really hate making money because he multiplied that profit by a negative 100. Later on, I realized that the signal is interesting, it could be a positive number which means the investor is in a long position of owning certain stocks and a negative number indicates the investor is in a short position cashing out his stocks. So if this person is selling, then signal is negative, and if the price increased, this actually ended up a big positive boost to the reward. +price * -share * – 100 = +100 P&L. Last but not least, he also added a component where he multiply the number of shares he owns yesterday by the number of days that he hold and divide by 10. This is also a positive number and grows linear as the number of days he holds this position (i) and by the absolute value of his position. Bigger the deal is, and this will lead to a bigger reward. In this way, how this second component in the reward function is structured probably will boost the performance of holding a big amount of stocks for a long time. This is interesting because the reward function is crafted in such a way that encompass several key data points but in the end, it will collapse back to the P&L, I am wondering why he did not use P&L just across the who journey.
All things said, this is actually one way of how reward function got implemented.
evaluate_Q
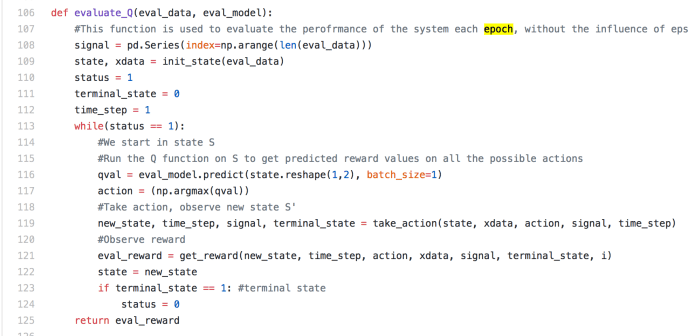
So here, the inputs to the evaluate_Q function are a trained prediction model – eval_model and a eval_data, which is a list containing a time series of pricing information.
First, the variable got initialized into an empty panda series. and then the pricing info got to be used to initiate the xdata (a time series of all the states) in which variable state got initialized to be the first state. Next comes the grand while loop that will not terminate until the end. Each loop represents a time step, a day, a minute, or a second given how your time step is defined. At the beginning of the loop, the model will be used to predict the Q value for the given state. This will generate a value for each action taken under that state. In this case, we have only 3 different actions, buy, sell or hold. In this case, the eval_model.predict is supposed to generate a score Q value for each of those action taken. Whichever has the highest score will be deemed as the best action and be acted upon. Given the action taken, this will bring the process into the next state – new_state, time_step will increase by one and the signal variable will also be updated within the take_action function. In this case, the signal variable keep appending and appending until the end of the simulation. The eval_reward is actually calculated at every step and actually only eval_reward in the last loop got used. In my point of view, maybe the author should move that part of the code outside the while loop to improve some efficiency.
Main
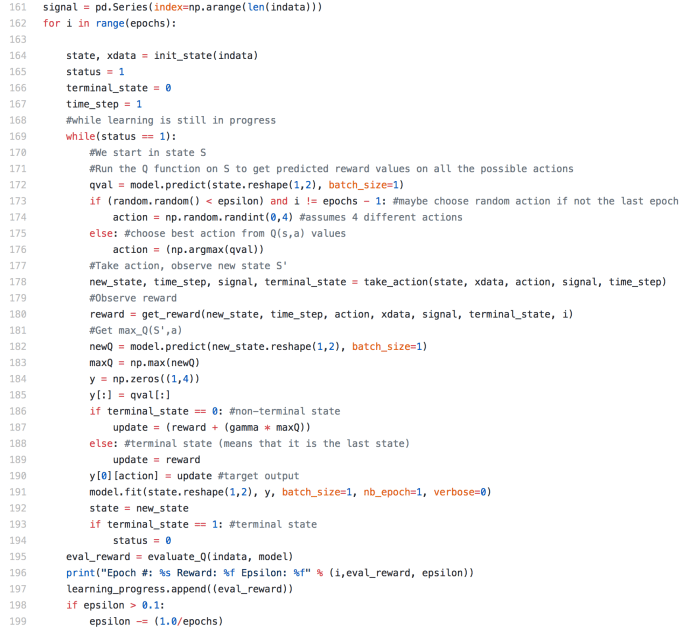
This is where the magic happens. First, it is the signal got initialized to be an empty panda series. Then it goes into a for loop, and the number of the loops is depending on how many epochs the user wants this model to run. Within each epoch, all the key variables got reinitiated but seems like signal variable got to escape from this process.
Within each epoch, there is this while loop looping through each state. This part of the code is actually fairly similar to evaluate_Q, you will see as we read more. First the model is being used to predict the Q value, however, before the Q value got used to pick the next optimized action. There is a random factor for exploration where there is chance that the next action will be randomly chosen to avoid local optimal or overfitting. Otherwise, actually most of the cases assuming you picked up a fairly small epsilon, the next action will be based on the estimation of the Q value. After the action being taken, all the key variables should be updated and we will land in a new state, then the new state will be used to predict the next Q value and now we can calculate the update to be the reward for the current step plus the best estimation for the next step at that time. Then this cycle will be fed to the prediction model and further enhance its capability to predicting the Q value for a given state and the right action to take.
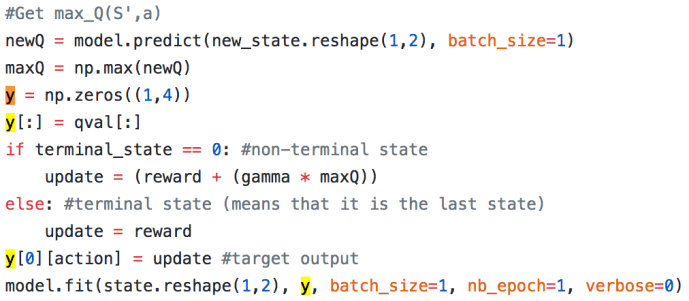
Again, I just want to highlight that how the recursion happened here. Probably a whole article should be contributed here to explain the mathematical reason behind how the model is updated and why the update is the reward with an attenuated future Q value. If you want something quickly and dirty, this stackoverflow is help explaining the difference between value iteration and policy iteration from the implementation perspective.
This is basically it, a more detailed explanation of the source code behind the interesting post about self learning quant.
Reference:
