One of my colleagues doesn’t know map reduce since he think “why would I need map reduce since I know multiprocessing, multithreading”, on the other side, I think why would you need to use multiprocessing since you can use mapreduce. Clearly, there is some commonality between the fucntionalities between these two. Mapreduce probably has the advantage of not only running multi-threading given a server, but also can easily run on multiple physical machines in parallel. In another way, mapreduce can do some work that multiprocess cannot handle.
However, if we have a relative big file, where it will take long time for a single thread to process but meanwhile it is still small enough to fit into our server, or even fit into memory(64 GB for a server is very common). which approach will be faster? not only from the execution perspective, but also from the development/coding time perspective.
Here is some code that I have written in Python using the multiprocessing (just want to side-bypass the GIL for now because I am newbie 🙂 ).
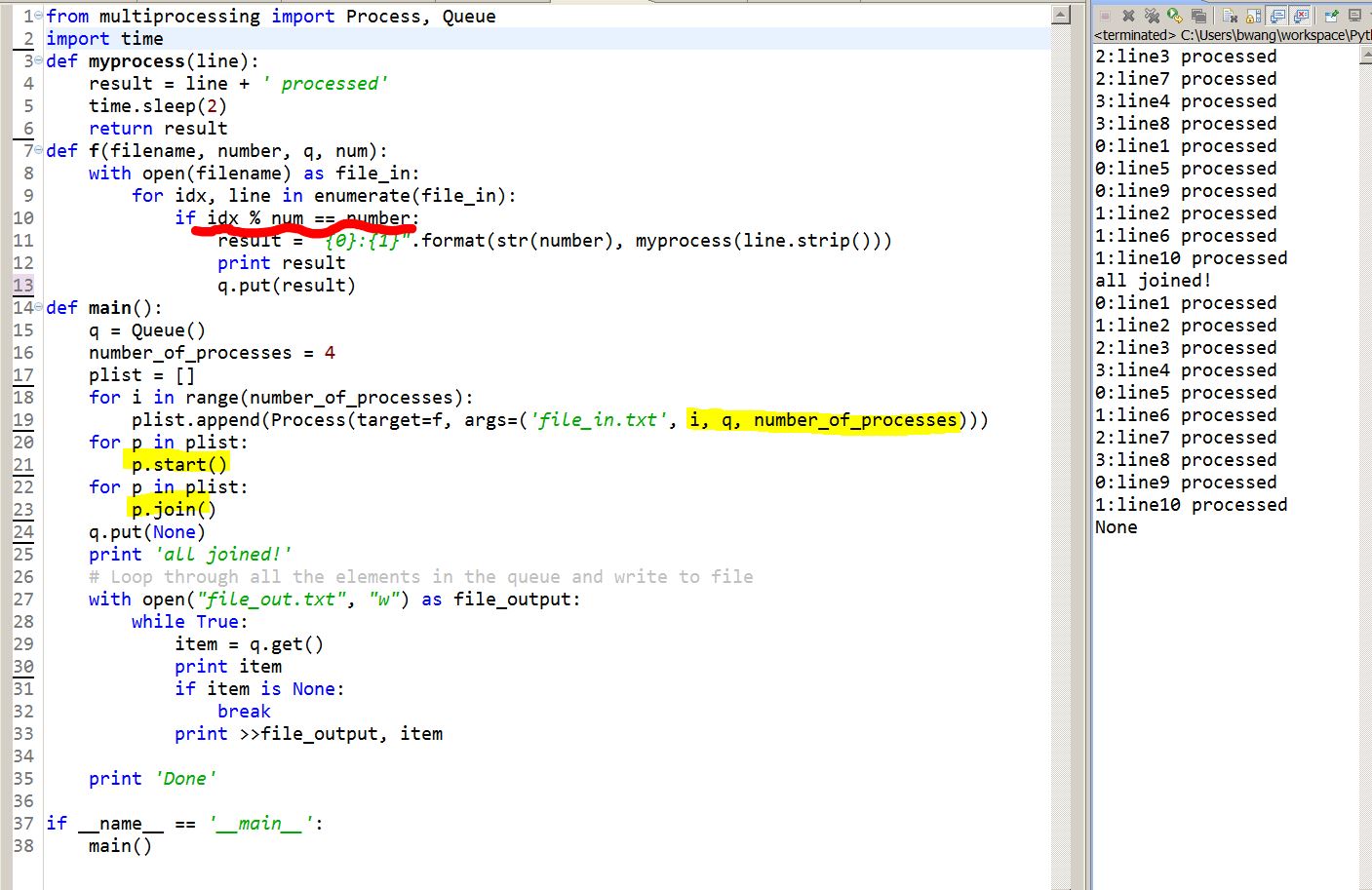
The goal is to read one file line by line and do something with each line, and then write the result to the same output file line by line, leveraging the multi-core and multi-threading what so ever to fully utilize the power of the whole computer.
