You are probably working with R inside Rstudio most of the time and most of your code is either interactive and disposable. In that case, you might not feel the importance of understanding R’s stdin and stdout that much. However, after I started learning running Rscript on Linux server, running Hadoop Streaming using R as reducer or mapper, it forces you to understand how stdin, stdout and stderr work.
As you can see from tldp, there are always three files in Linux, and lets first start with stdout.
STDOUT:
In Hadoop streaming, the information is passed through each stage through stdin and stdout. In that way, if you don’t have proper logic to control the cleaness of your output, random output from third-party functions might be added to standard output in which totally screw up your code. SINK() is definitely a function that you have to learn, which will “direct the output to a file”, the file here could be a txt file or csv file, it can also be “/dev/null” or NULL(default as “stdout”). So to make sure your Hadoop Streaming only outputs the content you want. You can use sink function to suppress your output, i.e., diverts all your output to /dev/null. And only open the output right before you wants to write output and remember to switch back after that. Here is a tutorial from weblogs.java.net which I found super helpful to read through a hands-on example.
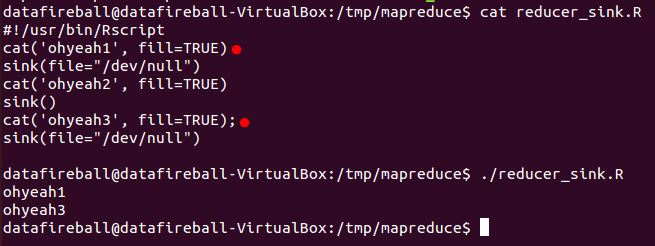
(This is a screenshot of a very short example demonstrating how to switch on and off output)
STDERR:

Error handling in R is super important in the process of writing a robust Hadoop Streaming job. However, maybe R users might found the error handling, or actually the documentation of error handling is not that straight-forward. Here is a great tutorial from WorkingWithData showing the ins-and-outs of the tryCatch function in R.
