You have to buy Lucene in Action! I personally think Lucene in Action and Solr in Action are the best two technology book that I have read. I am trying to follow the example Sample Application 1.4.
You can download and run the example code here. I don’t have that much experience working with Java, most of the projects that I have worked with use the build tool Maven, looks like the POM file will take care of all the dependencies and the build process. This time, the author of Lucene in Action decided to use Ant.
At the beginning, I thought it might be another headache, however, it turned out to be so easy to follow the tutorial, simply download the source code, navigate to the project root directory where build.xml is located. And run the command:
ant Indexer
And you just type in a few input arguments through the command line and the program will locate the example and everything finishes smoothly.
I was super surprised at how easy this is and looking at the build.xml, we see how this happens:
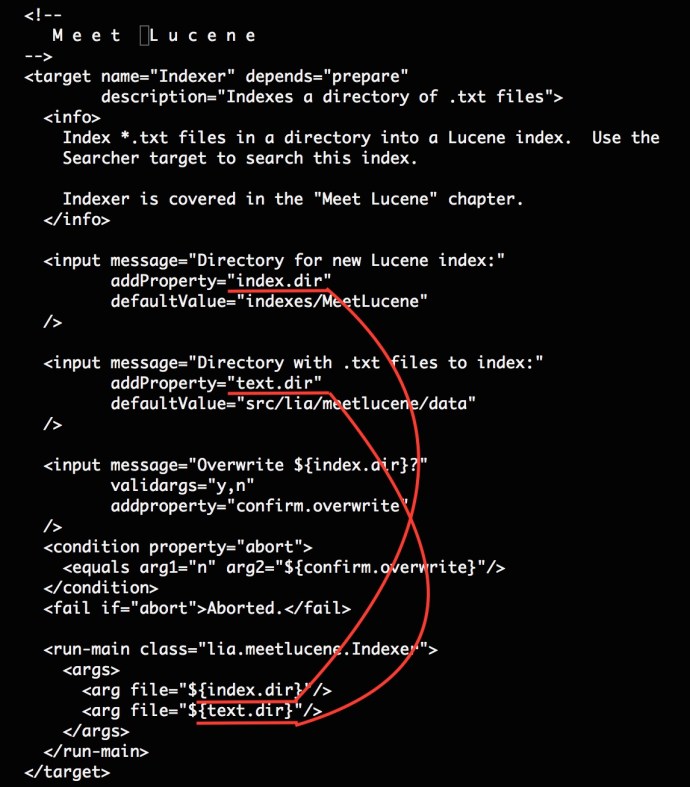
the name attribute of target defines why ant Indexer will locate this build block. Then we have an info tag. Following the info, we have two input blocks where defined the prompt message, variable name. In the name, the run-main block is very interesting, where class defines where to look for the main class in the package and passes the two arguments to the program.
After running the Indexer and Searcher, you will see there is a folder that we specified, indexes/MeetLucene that got generated. And there is the folder where all the indexes have been stored.
$ ls
_0.cfs segments.gen segments_2
There are are three files under the index folder and they are all binary files which is not that straightforward to interpret. I even did not find a good place in the book explaining what those files are for.
After a quick Google search, you can find Lucene Index File formats here.
CFS: compound files
Segment_N: active segment file
Here is a screenshot of the first few lines of the cfs file. And clearly we can see it is a compound file of a few different smaller files.

- _0.tii The index into the Term Infos file
- _0.tis Part of the term dictionary, stores term info
- _0.fdx Contains pointers to field data
- _0.nrm Encodes length and boost factors for docs and fields
- _0.fdt The stored fields for documents
- _0.prx Stores position information about where a term occurs in the index
- _0.frq Contains the list of docs which contain each term along with frequency
- _0.fnm Stores information about the fields
