The regularization is a trick where you try to avoid “overcomplexing” your model, especially during the cases in which the weights are extraordinary big. Having certain weights at certain size might minimize the overall function, however, that unique sets of weights might lead to “overfitting” where the model does not really perform well when new data come in. In that case, people came up with several ways to control the overall size of the weights by appending a term to the existing cost function called regularization. It could be a pure sum of the absolute value of all the weights or it could be a sum of the square (norm) of all the weights. Here is usually a constant you assign to regularization in the cost function, the bigger the number is, the more you want to regulate the overall size of all the weights. vice versa, if the constant is really small, say 10^(-100), it is almost close to zero, which is equivalent of not having regularization. Regularization usually helps prevent overfitting, generalize the model and even increase the accuracy of your model. What will be a good regularization constant is what we are going to look into today.
Here is the source code of regularizing the logistic regression model:
logits = tf.matmul(tf_train_dataset, weights) + biases loss_base = tf.nn.softmax_cross_entropy_with_logits(labels=tf_train_labels, logits=logits) regularizer = tf.nn.l2_loss(weights) loss = tf.reduce_mean(loss_base + beta * regularizer) optimizer = tf.train.GradientDescentOptimizer(0.5).minimize(loss)
As you can see, the code is pretty much the same as the one without regularization, except we add a component of “beta * tf.nn.l2_loss(weights)”. To better understand how the regularization piece contribute to the overall accurarcy, I packaged the training into one function for each reusability. And then, I change the value from extremely small to fairly big and recorded the test accuracy, the training accuracy and validation accuracy on the last batch as a reference, and plotted them in different colors for each visualization.

The red line is what we truly want to focus on, which is the accuracy of the model running against test data. As we increase the value from tiny (10^-5). There is a noticeable but not outstanding bump in the test accuracy, and reaches its highest test accuracy during the range of 0.001 to 0.01. After 0.1, the test accuracy decrease significantly as we increase beta. At certain stage, the accuracy is almost 10% after beta=1. We have seen before that our overall loss is not a big number < 10. And even the train and valid accuracy drop to low point when the beta is relatively big. In summary, we can make the statement that regularization can avoid overfitting, contribute positively to your accuracy after fine tuning and potentially ruin your model if you are not careful.
Now, let’s take a look at the how adding regularization performed on a neural network with one hidden layer.
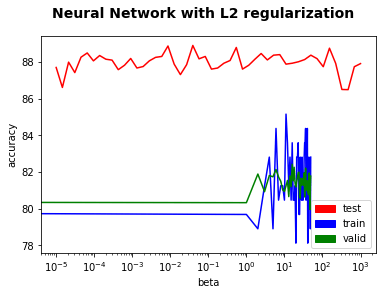
First, we want to highlight that this graph is in a different scale (y axis from 78 to 88) from the one above (0 to 80). We can see that the test accuracy fluctuate quite a bit in a small range between 86% to 89% but we cannot necessarily see a strong correlation between beta and test accuracy. One explanation could be that our model is already good enough and hard to see any substantial change. Our neuralnet with one hidden layer of a thousand nodes using relu is already sophisticated, without regularization, it can already reach an accuracy of 87% easily.
After all, regularization is something we should all know what it does, and when and where to apply it.
