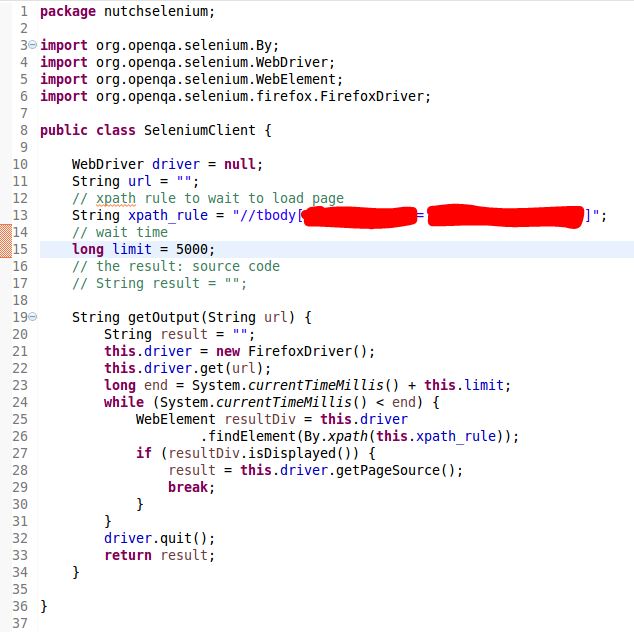
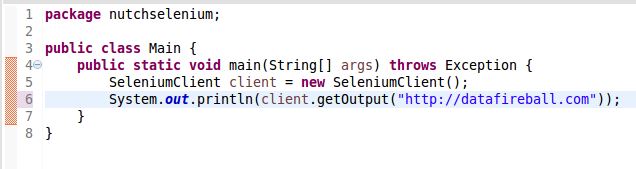
Vega is a visualization grammar developed by the folks from Trifacta(some history). You can have a brief idea of the idea of Vega in just one minute going to this online editor, which will map the json syntax to its corresponding virtualization. What is more, the community has also developed Python package Vincent to make Python plot beautifulsoup d3 quality graphs with Vega running behind the scene.
I installed Anaconda Python on my Ubuntu box since pandas is a dependency for Vincent, which Anaconda ships with pandas. There are hundreds of warnings while I was doing `sudo pip install vincent` and it also took me a 10+ minutes pausing now and then, in the end, it will finish, FYI.
My first impression of Vincent is it is actually not as awesome and friendly as rCharts in R. And after tinkering about for a while, I did not figure out how to do that in iPython notebook and instead generated the vega template and the vega.json to have a plot looks like below. It looks pretty slick but there is no hovering over and those interactive features that I assume should be delivered. And I still think it will prefer rCharts over Vincent unless one day that I have to develop it in the Python environment. iPython Notebook + Vincent + Flask? maybe …
But at this moment, I like Shiny + rCharts + ggplot2!