As an analyst, I spent a significant amount of time typing, all kinds of typing, writing code in Jupyter notebook, navigating through the servers within bash, browsing the internet or even just writing emails and text editing in general, or even right at this second, typing this blog up (I guess Jupyter notebook and blog writing both falls under the browser navigating). Most people might not have the opportunity or access to watching some of the best “typers” in a close distance, some of you who constantly do pair programmings with your coworkers, coaching your junior team members how to use linux, or even just by sitting in a meeting watching your someone sharing their screen, you can clearly tell a difference in people’s productivity not necessarily by people’s IQ, nor methodology, merely noticeable time saving/wasting led by operatational efficiencies introduce by how fast they can instruct the computer in general, or simply typing.
Blind Typing

To me, blind typing is as much a necessary skillset in the 21st century as driving to society after Ford commercialized automobiles. I happen to have the opportunity sit in several technical interviews with lots of candidates with various experiences based on their own claims, and various levels of experiences based on their own demonstration. I came across college students who navigate through stackoverflow and google like playing starcraft 2 with a 200APM cracking the coding interview like no one’s business, and at the same time, tortured by watching self-claimed decades of experience senior staff delete lines of text again and again because they made a typo in previous lines of code but unable to notice it till the very end because the attention is all on the keyboard to find the right key. People claim that writing or programming is only about typing, and many top notch programmers aren’t the fastest typers in the world, it is more about the logic, the ideas, which I fully agree and bear that philosophy deep in my heart.But in my humble opinion, having great logic and beautiful written code doesn’t conflict with you typing fast. Making blind typing your second nature with 60 words per minute minimum and decent amount of accuracy (no constant backspace) will certainly free your mind to focus more on thinking.

Lebron James might be an exception who is “allowed” to type using two index fingers but only because he doesn’t even need to look at his “monitor” when he does his job, let alone “keyboard”.
Shortcut
To me, this is the differentiator which many people got left behind because now they have a way of doing things. Theoretically, yes, having the keys, backspace and arrow keys can help you navigate through if not all, very majority of your tasks. It is more intuitive, “makes sense”, but it is those black magics that made your job unique, it is those mysteries that distinguish you from the rest. And shortcuts are certainly the key. It get you to a place faster, faster to allow to make more mistakes, faster to save time, faster to achieve more, and faster to level that quantitative difference one day will actually make a qualitative difference that people who watch your screen suddenly drops their jaw to the ground.
You can pretty much Google search “shortcuts of” with any softwares that you use at a day to day basis, conquer the inertia of doing it in the old way and soon you will learn it. However, on a software to software basis, sometimes the marginal benefit is fairly low because some shortcuts are not quite frequently used, and those shortcuts won’t work in other tools so it will be good to start analyzing people’s typing behavior and come up with a some of the most generic and beneficial shortcuts to get started.
There is no doubt of those usual suspects like C-c (Control +C), C-v and C-z, if you are not already familiar with. Here I want to share a few shortcuts specifically related to text editing that I wish someone told me when I first started my career, or back to when I was access computer since 12 years old. I do have to say, many of the short cuts were actually learned from when I started using Linux, which a mouse or even a GUI is not readily available. You need to figure out how to only use a keyboard to do everything you wanted text editing.
Control + E
C-e: go to the end of the current line, this one works EVERYWHERE, in the browser, in code editor, in terminal and pretty much everywhere that I know of texting editing. Can you use mouse? sure, can you hit the right arrow key until you get to the end of the text? yes, can you use down Arrow key and it will get to the end of the line if the line your are editing is indeed the last line? yes. Can you … I believe there are a dozens of ways of achieving go the end of the current line but to me. I will share when I use this functions the most.
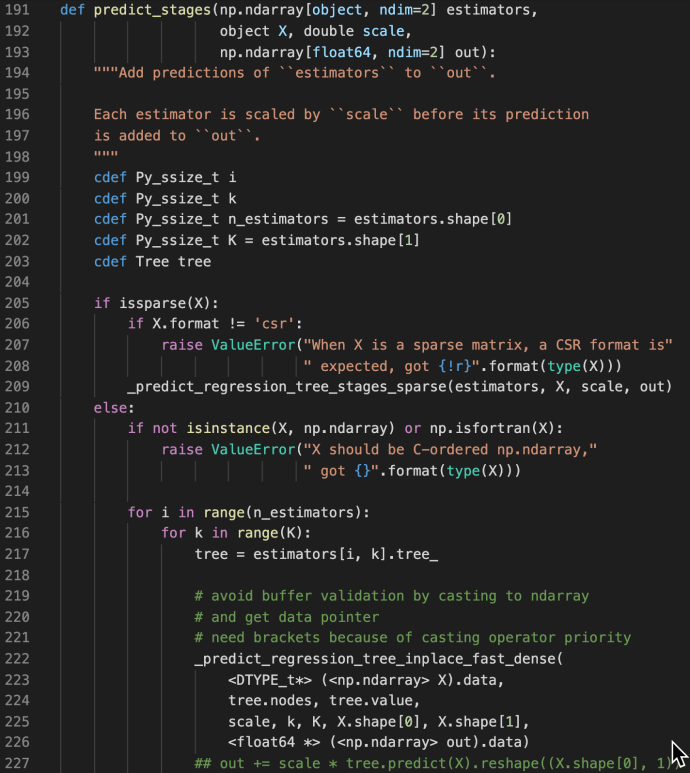
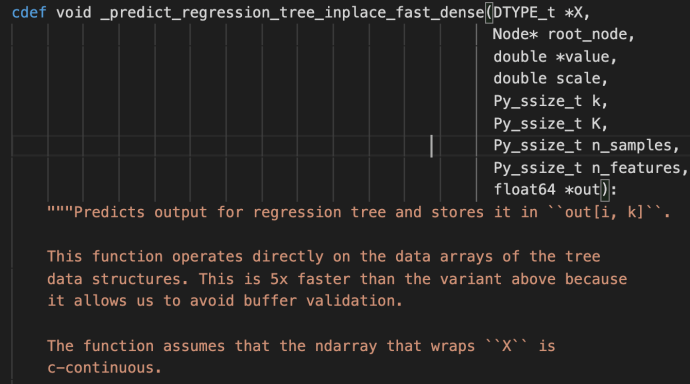
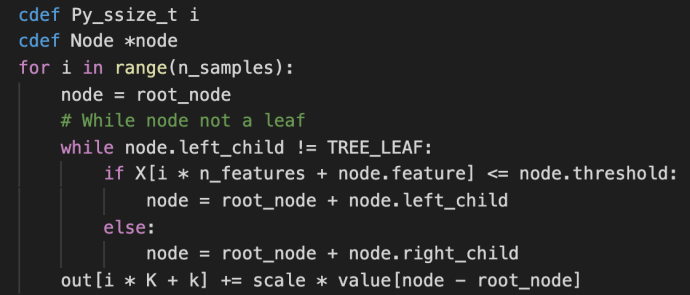
For example, when I edit Python code, I tend to use Jupyter Notebook which whenever I type any type of closure, like left open parenthesis, left brackets, single/double/triple comma, it will auto complete with the pairing half and focus your cursor in the middle. This is a great feature to save you the effort of counting brackets or avoid error out of accidentally missing the closure or actually saved you half of the typing because when there is an open, there must be a closure. However, now you are in the middle, after you auto editing the content, there isn’t necessarily a way to get back outside so you can keep editing, most people now will use the Arrow key, or god forbid, mouse, to navigate back to where they wanted to edit. Here is where C-e comes in which directly navigate to the end of the line which you can keep editing. If you are comfortable using Control keys or Meta keys (Alt or Option), C-e literally feels like one keystroke. but instead of completely moving your right hand away, find arrow keys, push it several times, and then reposition your index finger on the J key now feels too much work all of a sudden. In this case, there is a easily 2x or 3x+ inefficiencies introduced by not using C-e, and imagine how many closures you have in your code? every function has a closure, every collection (list, dictionary) has some sort of closure, indexing slicing, ..etc.
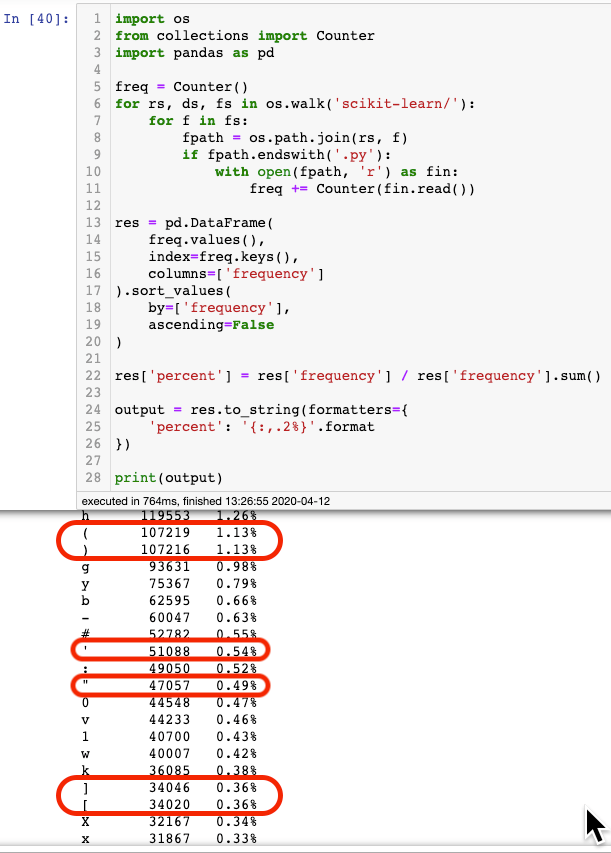
I did a character count on all the Python files within one of the most popular libraries out there, sklearn. As you can tell, there are about ~ 3% of all your keystrokes that can benefit from this little shortcut.

People go to beginning of the line far less frequent than end of line as you right right beginning to ending! But if you do, which I use occasionally, C-a is the opposite of C-e.
Shift Click Selection
Sometimes, one needs to select a good chunk of text, copy and paste it somewhere. Have you had this experience that your selection is several pages and after you click your left mosue key, scrolling for pages after pages while holding that key down, only once in a while you accidentally let it go and you will have to scroll up and redo everything again? Sometime, we are talking about pages after pages. At least, I certainly remember the frustration when it happens and I have to hold my breath. There is a little trick that you can just click the start of the text that you want to copy, without holding anything, it is just like place a an invisible sign to mark the start of your selection, and then you can casually scroll down, and use “Shift + Click” to mark the end of the selection and everything will be selected! What is even better, after you mark the start, you can even use page up, page down, space and other keystrokes to navigate without even rolling that squeeky wheel on the poor mouse.
C-f/b better than Right/Left Arrow
As I have mentioned before, moving either of your hand away, so far away from the F and J key that you need to reposition should be avoided at all possible costs. Then people might ask, I need the Arrow keys to go forward and backward some certain characters like when there is a typo, missed typed several characters, or only when you noticed there is a typo in the middle of your line. Don’t worry, there are shortcuts too so you don’t have to use Arrow keys. You can use C-f to move your cursor forward by one character and C-b to move backward by one chart. holding those keys, just like using the arrow key will move as many characters as long as you are holding them down. This one took me a while to change the habit but once I get used to it – combination keys don’t slow me down anymore and reaching out to the arrow keys feel like a 5 hrs trip from LA to NY, again, reaching out to the mouse or trackpad is figuratively visiting India from NewYork, on an economy class in the middle seat with both of your neighbors need seat belt extension.
M-f/b faster than C-f/b
M is many contexts refers to the Meta (meta) key or the Alt key for your keyboard. If you are editing one line of texts and want to move way back or forard to make a change, holding down either arrow or C-f/b feels too long. Have you seen this before?

This is where some shortcuts conflict with each other and might be platform dependent as in Linux or Emac, it is M-f to move forward by a word and M-b to move backward by a word. In MacOS terminal, it is still the case, but certainly not the case in text editor. Instead it looks like Meta + Arrow keys to move by word just so everyone knows. 
Tab
Many people know that tab means autocomplete, but the level of adoption certainly varies. I have seen people use tab merely as a suggestion, still prefers to type literally every character out one by one, also have seen people use the mouse to choose from the autocomplete, probably trained by years of experience using filters in Excel.

Others
Later on, I realized that many of the short comes from Linux and here is a Emac reference card which if not all, very majority of the shortcuts related to Motion and Editing are applicable in all text editor. Even Google search bar 🙂 I will keep adding to this posts about great shortcuts that I found and share with you. Also, the ultimate secret to take the shortcut is to a good trade off between exploration and exploitation. Can you turn a code snippet into a small framework or function, can you use others libraries.