In a short sentence: Nutch will go through the content in regex-urlfilter line by line, within each line, it will check if the regular expression in that line matches the URL, if so, it will include or exclude the URL depending on what is the sign +/-, and SKIP THE REGEX(es) THAT BELOW THAT ONE! otherwise, it will keep trying all the filters and exclude the URL in the end if there there is not a single regular expression matches.
To be honest, my first assumption of how that regex-urlfilter.txt works was totally “wrong”. What I was thinking was “OK, whatever regex I put in there will all be applied to be used to filter the URL. And in the end, the URL will be excluded/included depending on the results of all the regex. Which is totally not the case how Nutch is implement. In Nutch, one URL is actually filtered by only one regular expression, ONLY ONE regular expression that first matches.
If you think you have a better time understanding the code instead of my emotional description, here is a snippet of the source code how the filter part.
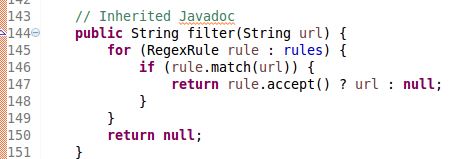
As you can see, when it is looping through all the rules/regex, the whole method will return either URL(include) or null(exclude) whenever URL matches the rule depending on the “sign”. The source code of Rule object is also attached below to help you understand the accept and match method. It is nothing more than the java.util.regex whose usage is better explained here.

Here are a few examples to let you get started without going through the source code:
Say if you think you want to crawl that URLs that belong to the directory /browse of the website but you don’t want the URLs that contains question mark ‘?’ i.e. dynamic pages. If you put:
# regex-urlfilter.txt +^http://www.example.com/browse -[?]
Then your crawler will not filter out those dynamic pages, because when Nutch start filtering after normalizing, it will first check if the URL, say http://www.example.com/browse?productid=2 start with http://www.example.com/browse, and the answer is yes, then it will just stop filtering and then categorize the URL as included. Of course, your regex “-[?]” will be totally ignored in this case. So to make this work, you can just switch the order like:
# regex-urlfilter.txt -[?] +^http://www.example.com/browse
Then it will be perfect. Also, theoretical analysis always feels weak if you ask “I have a big file of regular expression, will it work or not!”, and you don’t want to start crawling and realize it is wrong after unleashing the monster. You can set up Nutch in Eclipse and test it easily with literally a few lines of code:
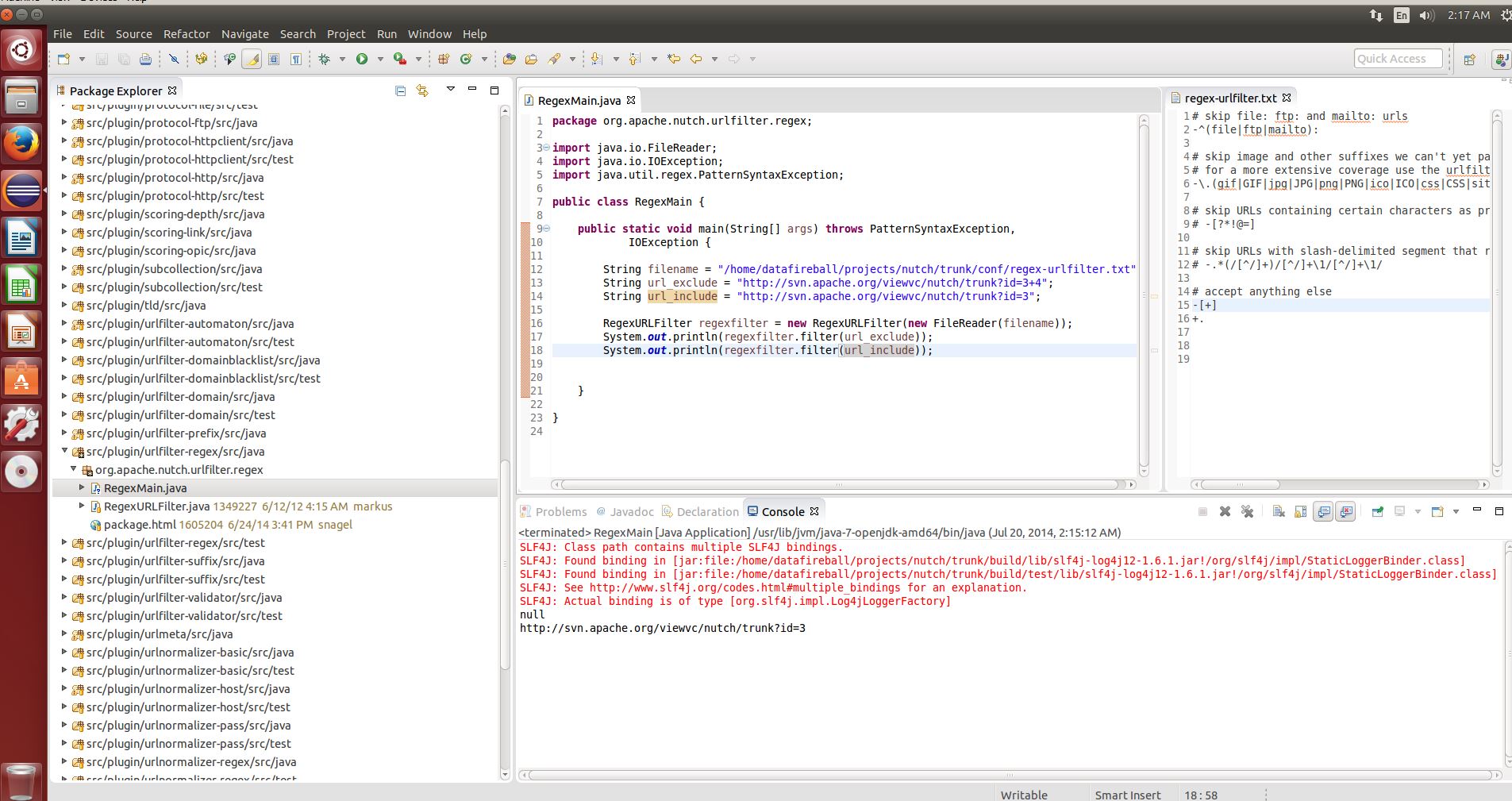
Now good luck!
