There are more than more websitse populating web content using dynamic methosd like making Ajax calls, executing Javascript..etc. And Nutch doesn’t have the mechanism built in at this moment to handle those pages. I am planning to figure out a way to integrate Selenium with Nutch, I saw momer has written a Nutch plugin for Selenium, however, it is need some effort to make it work since it is not maintained actively. Since now, everything is new to me, like how to write a plugin, how to use selenium in Java, how to optimize the selenium performance..etc. I am planning to write a few posts to share my progress on this part.
First I have to figure out, under the hood, how Nutch is fetching the content. Maybe after I understand how it works. I am replace the fetching part with selenium. I set up the debug mode for Nutch in my virtualbox following these tutorials, NutchInEclipse and NutchTutorial(trunk).
I injected one URL(http://datafireball.com) into crawldb following Tejas tutorial. Then I generated the fetchlist by running “org.apache.nutch.crawl.Generator” as the Main class and pass the crawldb and segments folder as the program arguments.
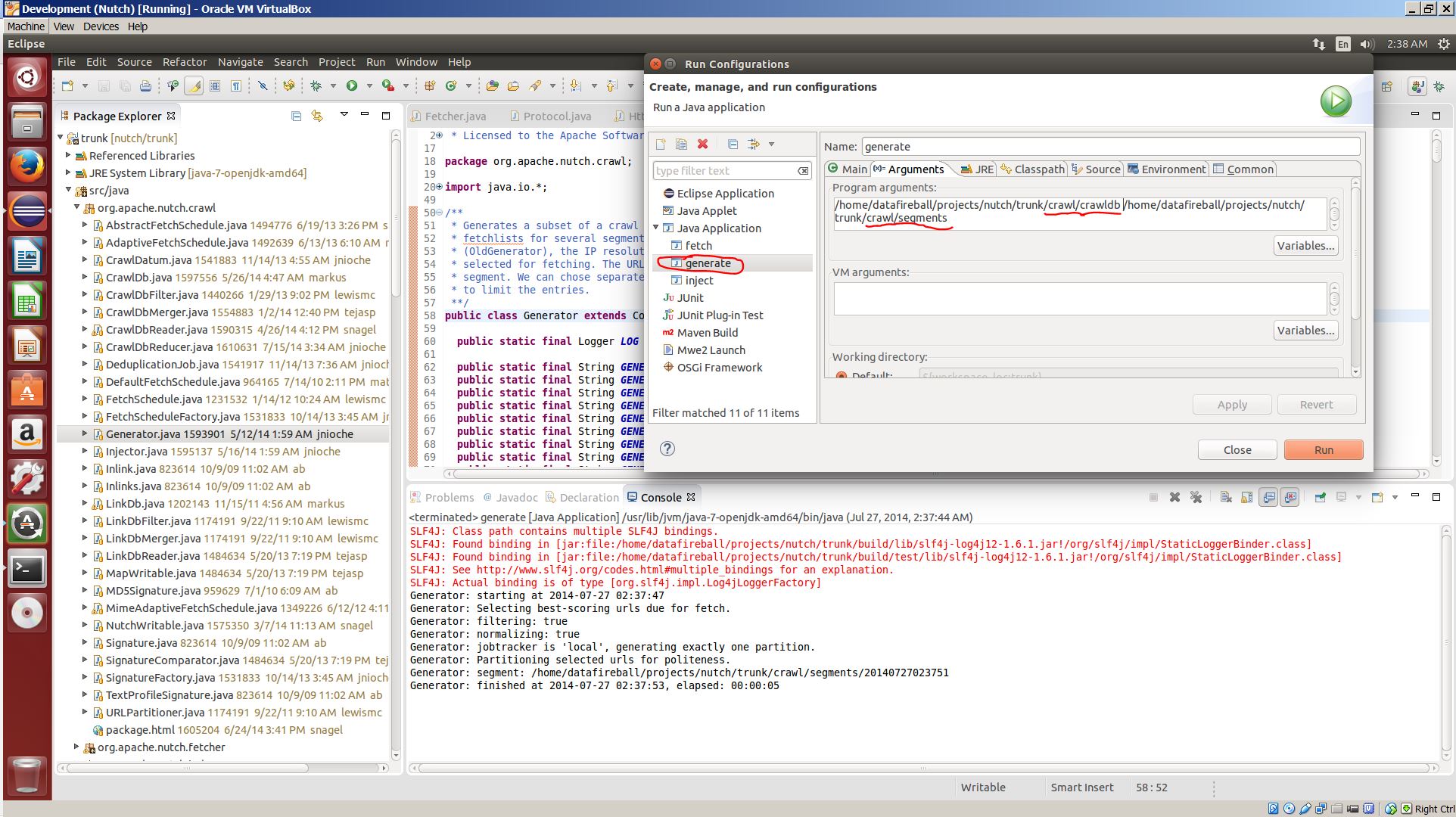
Now we have the fetchlist generated and we need to run the fetch step in debug mode, in that way, we can step through the process and accurately locate which part actually did the fetching. Of course, I created a new run configuration in Eclipse and set the main class as org.apache.nutch.fetcher.Fetcher and pass the newly generated fetchlist, `/home/datafireball/projects/nutch/trunk/crawl/segments/20140727023751` in this case as the program argument. Before you hit the DEBUG button, there is one thing that we need to do: set the breaking point! Going through the source code of the Fetcher class, you can have a brief idea of where the fetching might happen. Here I set the break point at line 675 since there is line of comment “fetch the page” :). Hit the debug button and the program will run for a few seconds and then pause at the line 675.

From here, we can use the Step Into (F5) and Step Over (F6) button to run the program step by step. The thing that matters the most is the Variable window in the top right corner. There you will see a list of all the variables and the corresponding value.

Now we found that, after finish running the line `ProtocolOutput output = protocol.getProtocolOutput(fit.url, fit.datum)`. There is a new variable called output generated in the variable window and the content attribute of output contains the raw HTML page! Now I know that is exactly the right path that I need to chase after, but using F3(Open Declaration) will go to the definition of the interface instead of the implementation. Right click the function (Open Type Hierarchy) or just simply hit F4 will show you which classes implement this interface.
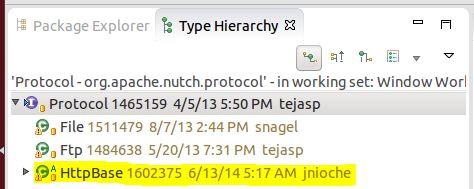
we know exactly that in this case, HttpBase is what we are interested in, but instead of diving into the source code I would prefer running the same debug again, and see what those code actually does. To keep the configuration settings the same, you need to remove all the directories in the crawl folder except for the crawl_generate. Then you set a breakpoint at the getProtocalOutput and step into that function.
Inside the function getProtocolOutput, we can locate it is the getResponse method of HttpBase that get the response and later assign it to the variable content. Keep going down this path, you have to take a look at the class HttpResonse. The code there is pretty exciting and inspiring. It basically describes the process of the nuts and bolts of a simple HTTP request. Building request header, create socket, get response…etc.
At this stage, we know that we can just simply replace the getProtocolOutput/getResponse/HttpResponse, method with a customized function that take a url and return the HTML using Selenium. Also the protocol-http, protocol-httpclient and lib-http are all in the plugin folder, then they are supposed to be easily pluggable and replaceable. In another way, we don’t have to modify any existing code, we can just simply create a new plugin, probably with most similar code as the http plugin but using Selenium.

The plugin I wrote works well, and with Nutch 2.2.1; additionally, a selenium-grid plugin I wrote also works. If you have any changes to make, a PR is suggested, rather than rolling your own, so that the community may benefit.
Thaanks for the post