If the data that you are trying to search/index is already in some sort of database that support JDBC, then you are in good shape.
I was once thinking that I can export the into into CSV-ish file and then use CSV uploader or even simpleposttool to help me upload those data into Solr. Clearly, this is such a common use case they even have a function that connect Solr directly with database to avoid this uploading and uploading process, and this functionality is called “Data Import Request Handler”.
This post is about quick and dirty tutorial where I was trying to load 1 million records into MySQL and then use the data import request handler to feed to Solr to index.
Believe it or not, I have not quite fully understood how to create a brand new core from scratch, in this tutorial, I completely forked the example project – techproducts where all the project structure has been well laid out. Then it is just a matter to change a few parameters here and there, add a few dependencies and that is it.
In the end, there are three places that I need to change:
First is schema.xml: since we are going to index our own data, I have to add in all the fields into schema.xml to make sure all the necessary sql table columns have a corresponding field in the schema.
Then, it is the solrconfig.xml: there are two places in solrconfig.xml where we need to modify. The first one is to add data import request handler

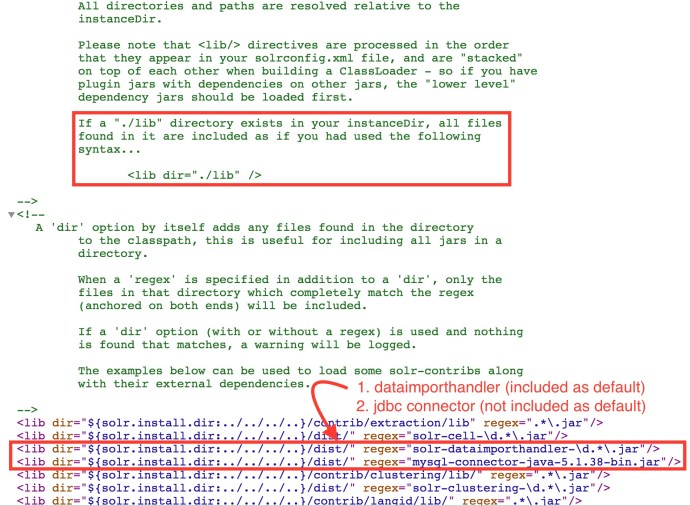
Then the second one is to include necessary dependencies to make sure they know where the jdbc driver is (MySQL in this case) and where the dataimporthandler is.
The dataimporthandler was included as default under the dist directory where I had to download the MYSQL jdbc driver myself to the dist directory and included in solrconfig.xml.
In the end, it is the file data-config.xml where all the mysql credentials and sql query and column name mapping are defined.
In the end, restart your project and you are good to go, you can either by calling the dataimport by issuing an http call or you can log in solr dashboard and click the execute “Button” there, here is how it looks like in the end including the data-config.xml content.
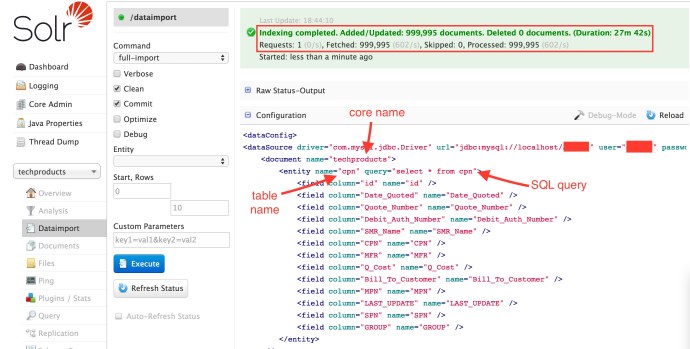
In the end, I have to say that the process was pretty easy, however, the out of box performance was not as satisfactory as I expected. It took almost half an hour to index only 1 million rows, and the bin/post command can upload 1 million rows in 24 seconds!
More research need to be done but this quick experiment is very meaningful since this solution could potentially seamlessly tie different types of relation databases all together (MYSQL, SQL server, Teradata, and even Hive, Impala…) without too much hassle. 🙂

Hi friend. GREATTTT post. I followed every step of it. I am having some issues though. I guess since I am a newbie at solr haha. Can you please show your managed-schema.xml? that has the rows that are being indexed? Because unfortunately I am successfully pulling rows from SQL database (I am using SQL Server 2014 but the mysql tutorial works the same) but my files are not being indexed unfortunately. I have 2 database columns needing to be indexed the 2 datatypes are nvarchar. Any Guidance? Thanks !!
Hi Kevin, thanks for your interest. I wrote this blog a while back and it is really hard for me to find it. I suggest you go to stackoverflow and maybe post the question there with a bit more detail. I am sure the community will be much more responsive and helpful than I do. Thanks!