This post, actually this upcoming series of posts, will be focused on gaining more knowledge of the exactly implementation of sklearn. Not only how in depth the algorithm got implemented, but also learning the best practices and styles of one of the most popular python library or even machine learning library out there. And today focus will be looking at the _tree.pyx.
To really dive into the details of trees, one has to be familiar with the underlying data structure used for implementing a decision tree, or a tree in general. Under the _utils.pxd, can you easily find the declarations for two key data structures Stack and Priority Heap and its relevant implementation atomic unit – StackRecord and PriorityHeapRecord.
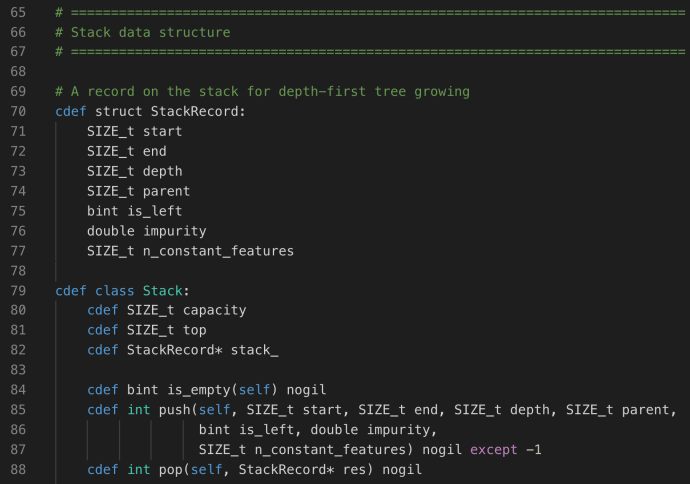
No surprise, Stack is the commonly used data structure which supports FILO logic, hence, we have the push and pop method. Each record is actually fairly interesting which we are going to future explain what each attribute is being used for.
After that, it is another data structure called priorityHeap.

I came across a great post about PriorityQueue with BinaryHeap which you can find the more interesting reading and Python implementation here. At a very high level, the regular Stack is used for depth first tree builder and the PriorityHeap is used for the best first tree builder. In the ideal world, both tree builders will lead to the same final tree but one is learning faster and usually is preferred when we need cut off the learning process early with pruning (like decision stumps in GBM). To simplify, we will start by focusing on depth first tree builder.
Now let’s switch our eyeballs to the _tree.pxd.
Like StackRecord, the atomic unit of a tree is node, and each node is made of its left and right child (identified by the ID), the split feature, the threshold (regression), impurity gain during split, and others.
Then let’s take a look at the Tree class’es attributes. Node* and double* are the two pointers/arrays that store the true content of a decision tree.
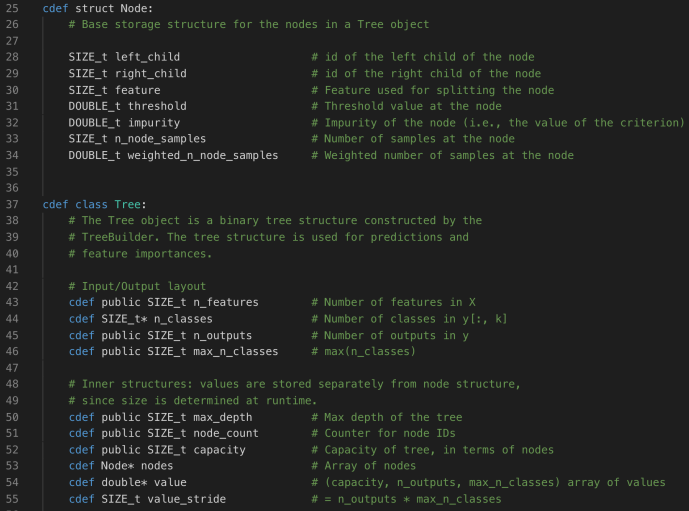
Now we have skimmed through the basic data structures, let’s switch to the _tree.pyx implementation and take a look.
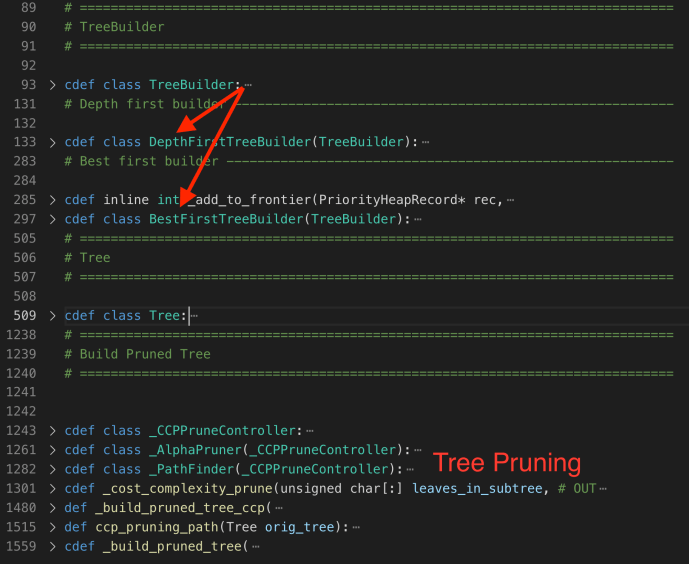
The whole _tree.pyx isn’t quite complex, only ~1600 LOC and if we are only interested in the Tree class implementation and the easiest tree builder DepthFirstTreeBuilder, you only need to read a few hundreds of lines of code. So let’s get started.
At the beginning, they first declared a TreeBuilder class as the basic interface which further got extended into different types of TreeBuilder (depth first or best first). It only has an internal method _check_input to ensure the data is contiguous.

Across the whole implementation, there are numerous places that for performance reasons making calls to compress sparse matrix and others. Those functions play a pivotal role regarding making a python library fast enough but itself might deserve a dedicated series and less relevant to the tree implementation which we will skip for now.
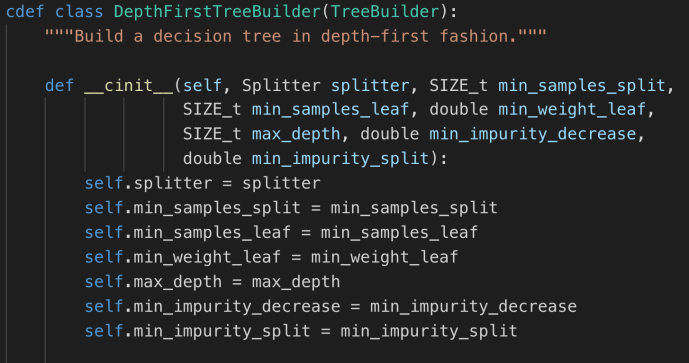 The constructor of DepthFirstTreeBuilder includes several key parameters when builder a tree. Splitter is the various splitter implementation which we will cover later. Now let’s go through the build method and see how each attribute drives the building process.
The constructor of DepthFirstTreeBuilder includes several key parameters when builder a tree. Splitter is the various splitter implementation which we will cover later. Now let’s go through the build method and see how each attribute drives the building process.
max_depth determines the maximum depth of the decision tree. As decision is a binary tree, when it is complete, the number of nodes grow exponentially. For example if you have 1 level, there are total 1 node, which is the root, if you have 2 levels, you have 3 nodes, and if you have three levels, you have 7 nodes, and when you have N levels, you will need 1+2+4+… = 2^0 + 2^1 + 2^2 + .. 2^ (N-1) = 2^N – 1 in total.
And as you can tell from the first few steps of the build method, that is exactly how max_depth is being used. 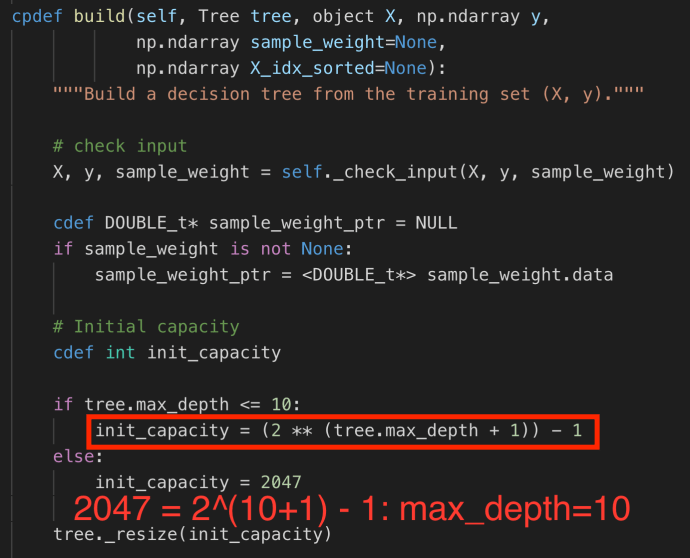
The next steps will be actually building the tree by working on the popped record and pushing its two children iteratively.
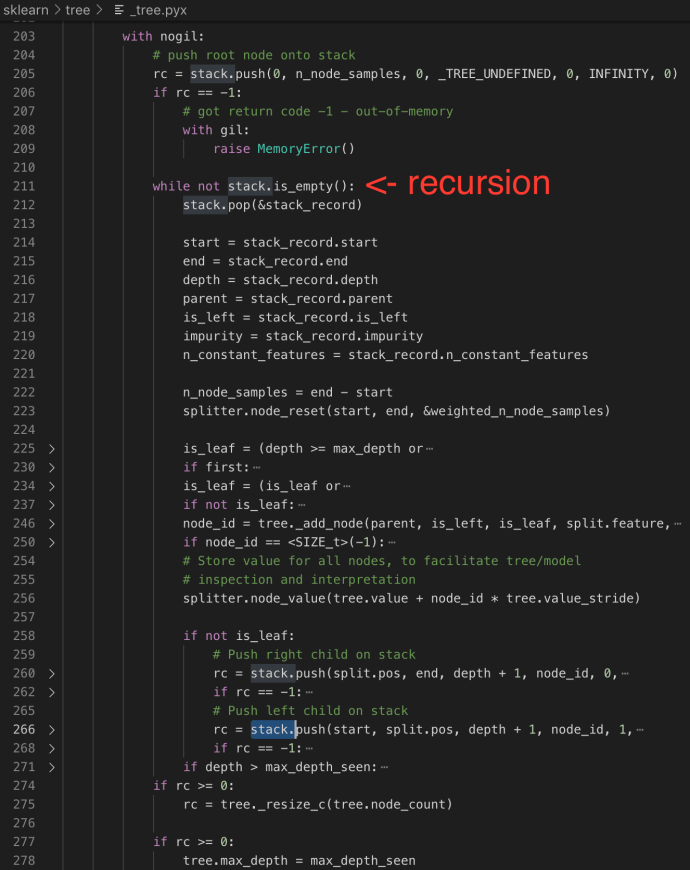
As you can tell from the code, the stack will pop each record and replace with two children if any. And that is also the reason that why the stack has the size of INITIAL_STACK_SIZE which is 10, the same as the depth of the initial tree capacity. In this way, it will first build/traverse the left most branch and then bottom up, slowly transition to the right and traverse the whole tree with only a stack of 10 records.
Now, let’s take a look at how splitter got called in the depth first tree building process.
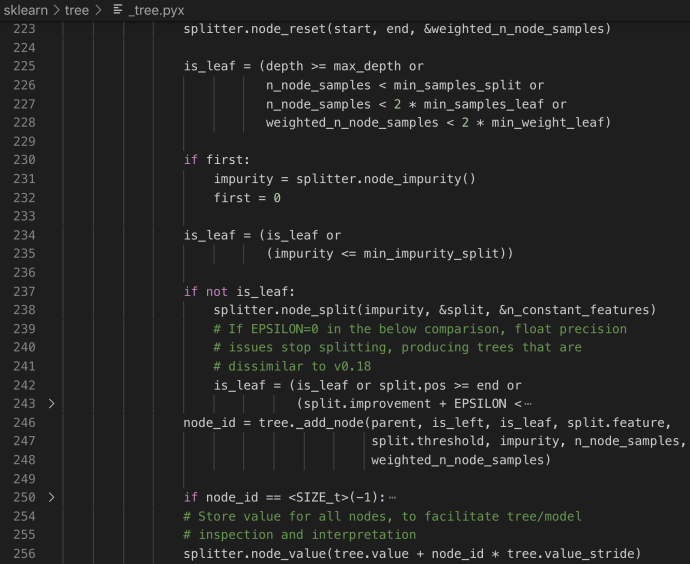
In the next post, we will spend more time looking into the node_split method and tree._add_node method to further understand the tree building details.
