Array-based representation of a binary decision tree.The binary tree is represented as a number of parallel arrays. The i-thelement of each array holds information about the node `i`. Node 0 is thetree’s root. You can find a detailed description of all arrays in`_tree.pxd`. NOTE: Some of the arrays only apply to either leaves or splitnodes, resp. In this case the values of nodes of the other type arearbitrary!
For a tree, it certainly has a few non-array attributes like node_count, capacity and max_depth. Other than those three, there are 8 methods which are arrays and all unanimously has the size of node_count.
1. children_left
each element stores the node id of the left children for the i-th node, of course, if i-th node doesn’t any child, it will use the value TREE_LEAF=-1. As the binary tree always follow the priority that the left child will always has the values that smaller than the threshold. Of course, all the children have a node id greater than its direct split node so children_left[i] > i.
2. children_right
very similar to child_left
3. feature
feature[i] holds the feature to split on for the internal node i -> Key
4. threshold
threshold[i] holds the threshold for the internal node i -> Value
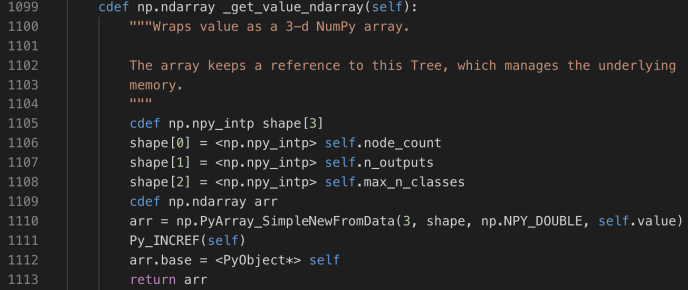
5. value
value is a bit complex, it has the shape of [node_count, n_outputs, max_n_classes]. The documentation says “Contains the constant prediction value of each node.“
6. impurity:
impurity at node i
7. n_node_samples:
holds the number of training samples reaching node i
8. weighted_n_node_samples:
holds the weighted number of training samples reaching node i

In the tree method, there are not that many methods that meant to be used by the users, and the sklearn developers achieved this goal by forcing the methods to be only available in Cython by declaring them using cdef. However, there are still a few methods that are being defined using cpdef which must be familiar to most sklearn users.
1. predict(X)

2. apply(X)

3. decision_path(X)
The decision_path code is very similar to other methods which it look through all the samples, and within each sample, it will populate the outcome. However, within the code of decision_path, it has used the indptr and indices and also the pointer to these two arrays, indptr_ptr and indices_ptr to point to the data.

If you are confused by indices, indptr and data, don’t worry, all those variables are the key variables for the CSR (compressed sparse rows) matrix in Scipy.
Instead of reading its official documentation, you can find this great Stackoverflow question. Here is a screenshot provided by user Tanguy explaining how those variables got put together.

4. compute_feature_importances()

