Today while I was doing some code review, I want to gauge the amount of effort by estimating how many lines of code there is. For example, if you are at the root folder of some Python library, like flask, you can easily count the number of lines in each file:
(python37) $ wc -l flask/* 60 flask/__init__.py 15 flask/__main__.py 145 flask/_compat.py 2450 flask/app.py 569 flask/blueprints.py ... 65 flask/signals.py 137 flask/wrappers.py 7703 total
However, when you open up one of the files, you realize the very majority of the content are either docstrings or comments and the code review isn’t quite as intimidating as it looks like at a first glance.
Then you ask yourself the question, how to strip out the comments and docstrings and count the effective lines of code. I didn’t manage to find a satisfying answer on Stackoverflow but came across this little snippet of gist from Github by BroHui.
At the beginning, I was thinking an approach like basic string manipulation like regular expression but the author totally leverage the built-in libraries to take advantage of lexical analysis. I have actually never used these two libraries – token and tokenize before so it turned out to be a great learning experience.
First, let’s take a look at what a token is.
TokenInfo(type=1 (NAME), string='import', start=(16, 0), end=(16, 6), line='import requests\n') TokenInfo(type=1 (NAME), string='requests', start=(16, 7), end=(16, 15), line='import requests\n') TokenInfo(type=4 (NEWLINE), string='\n', start=(16, 15), end=(16, 16), line='import requests\n')
For example, one line of python import code got parsed and broken down into different word/token. Each token info not only contain the basic token type, but also contains the physical location of the token start/end with the row and column count.
After understanding tokenization, it won’t be too hard to draw the connection between how to identify comment and docstring and how to deal with those. For comment, it is pretty straightforward and we can identify it by the token type COMMENT-55. For docstring, it is actually a string within its own line/lines of code without any other elements rather than indentations.
Keep in mind that we are parsing through tokens one by one, you really need to retain the original content after your work.
Frankly speaking, I cannot wrap my head around the flags that the author used to keep track of the previous_token and the first two if statement cases. However, I don’t think that matter that much so let’s keep note of it and focus on the application.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| """ Strip comments and docstrings from a file. | |
| """ | |
| import sys, token, tokenize | |
| def do_file(fname): | |
| """ Run on just one file. | |
| """ | |
| source = open(fname) | |
| mod = open(fname + ",strip", "w") | |
| prev_toktype = token.INDENT | |
| first_line = None | |
| last_lineno = -1 | |
| last_col = 0 | |
| tokgen = tokenize.generate_tokens(source.readline) | |
| for toktype, ttext, (slineno, scol), (elineno, ecol), ltext in tokgen: | |
| if 0: # Change to if 1 to see the tokens fly by. | |
| print("%10s %-14s %-20r %r" % ( | |
| tokenize.tok_name.get(toktype, toktype), | |
| "%d.%d-%d.%d" % (slineno, scol, elineno, ecol), | |
| ttext, ltext | |
| )) | |
| if slineno > last_lineno: | |
| last_col = 0 | |
| if scol > last_col: | |
| mod.write(" " * (scol – last_col)) | |
| if toktype == token.STRING and prev_toktype == token.INDENT: | |
| # Docstring | |
| mod.write("#–") | |
| elif toktype == tokenize.COMMENT: | |
| # Comment | |
| mod.write("##\n") | |
| else: | |
| mod.write(ttext) | |
| prev_toktype = toktype | |
| last_col = ecol | |
| last_lineno = elineno | |
| if __name__ == '__main__': | |
| do_file(sys.argv[1]) |
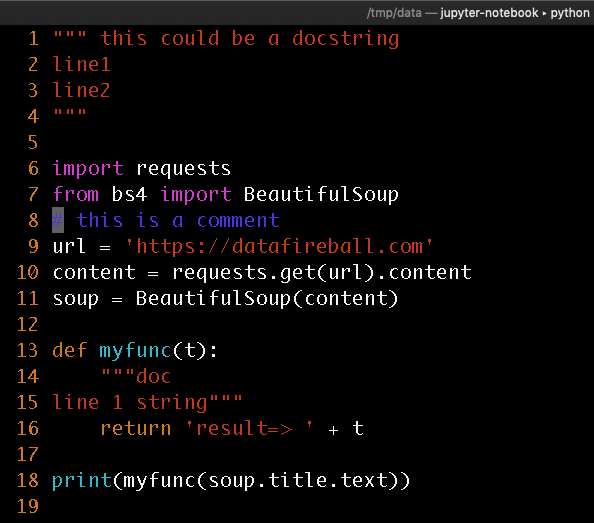
Here I created a small quote sample with test docstrings and comment in blue.
This is the output of tokenization and I also helped highlighted the lines that interest us. 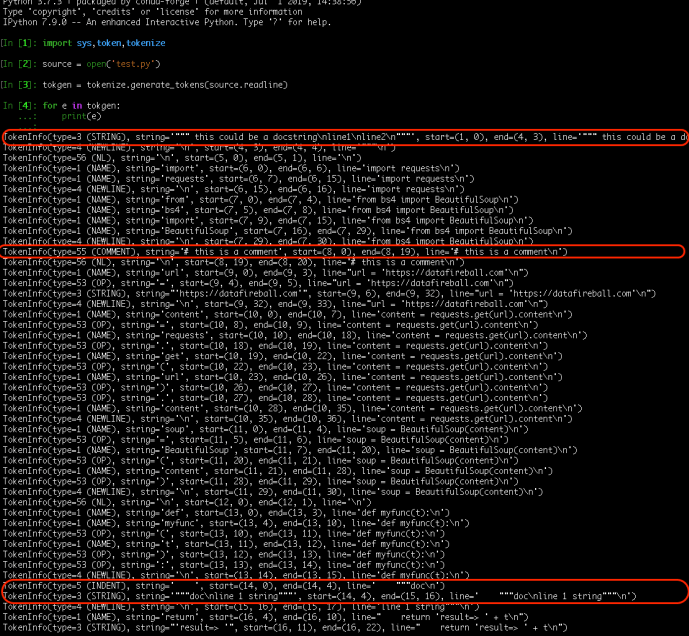
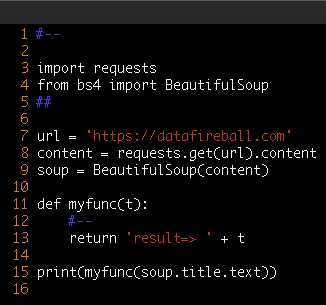
This is the final output after the parsing. However, you might want to completely remove the comments or even make it more compact by removing blank lines. We can either modify the code above by replacing mod.write with pass and also identify “NL” and remove them completely.

hi can you help with your post over at this thread
https://stackoverflow.com/questions/20365189/how-to-find-specific-video-html-tag-using-beautiful-soup
in your one liner which works great how would you add .mkv to that so it does both mp4 and mkv
thanks