
Book of Programs for Machine Learning C4.5 from J. Ross Quinlan
For those who are into A.I. know the existence of a very popular machine learning technique called a decision tree. It is so well known that people without any machine learning background probably used it under the scenarios like “if A happens, we should do B, but if not, we should do C. However, even if A happens, we might …”. The easiest way to visualize it is to start at the beginning called the root and break it down into different scenarios based on conditions.
Even in Finance, traders want to understand how likely the interest rate might move towards the current spot price, rather than on a pure condition based, they actually assume the condition stay the same but with different probabilities of going up and down, and might use option exercise conditions to prune the tree. In essence, tree is a great way of visualizing decision makings, and using data to draw an optimal tree that best represent the underlying probability distribution or “predicts mostly right” is the specialized field of construction decision trees based on data.
Wikipedia: Binomial_options_pricing_model – Interest Rate Tree
I have used this technique for years and even today, many of my favorite models are still using decision trees as the building unit, but it is just a matter of ensembling them in a different way like random forest or gradient boosting machines. Clearly, decision trees are very important but very few know its real history. Actually, the decisions trees that everyone is using actually even appear before modern computers.
![[picture]](https://www.rulequest.com/Personal/quinlan-small.jpg)
Ross Quinlan – Australian Computer Scientist and Researcher
Literally, the book is only 100 pages of content and the rest are all ancient C code. In these 100 pages, the chapter II is what interested me the most discussing the criterion of building test – in modern ML lingo, splitting the trees.
I came across learning ML from the practical perspective that cross entropy is just another cost function people commonly used that is best for classification problem. Not only because it is bounded from 0 to 1 but also has this vague feeling that it goes low when the number of wrong predictions goes wrong and vice versa. I never truely understand the meaning behind cross-entropy until I read what Quinlan said.
Here is directly quoted from the book
“…Even though his programs used simple criteria of this kind, Hunt suggested that an approach based on information theory might have advantages [Hunt et al., 1966, p.95] When I was building the forerunner of ID3, I had forgotten this suggestion until the possibility of using information-based methods was raised independently by Peter Gacs. The original ID3 used a criterion called gain, defined below. The information theory that underpins this criterion can be given in one statement: The information conveyed by a message depends on its probability and can be measured in bits as minus the logarithm to base 2 of that probability….” – Quinlan 1992, p.21
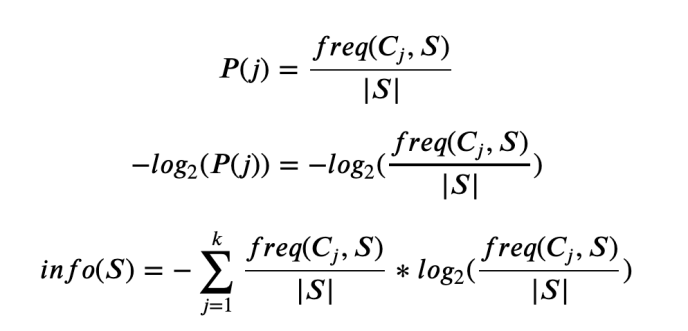
So basically, Quinlan emphasized that the reason that he and many others picked entropy, or cross entropy as the KPI / criterion was based on what information theory said. OK, then who came up with that then? what it actually means?
Now we need to jump from 1990s even further to when the measurement of modern information was introduced by Claude Shannon.


This guy published a paper in 1948, YES, even a year before the people republic of China was founded. This paper – the mathematical theory of communication serve as the milestone for the Digital age, now that you know how it revolutionized the A.I. field? well, that was not even half it, have you heard of Huffman coding, the algorithm behind your gzip, 7zip, and others? the bottom-up greedy tree construction coding algorithm that you scratch your head about in college, well, David Huffman came up with his coding algorithm under when he was a student of Fino and there comes the famous Shannon-Fino coding, well, the same Shannon. Imagine if Shannon is still alive, do you know how many Github stars that he will have or how many stackoverflow points he will get? …
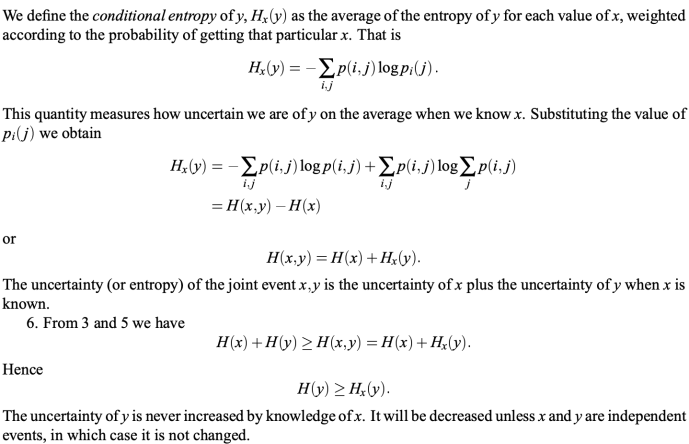
1948 seriously? well, let’s not give him too many credits as we are talking about Quinlan’s book. So basically, they used this information theory based measurement as the bedrock for machine learning cost function.
which later on, Quinlan also introduced a modified version of criterion which is pretty much the relative gain, gain ratio, rather than the absolute gain.
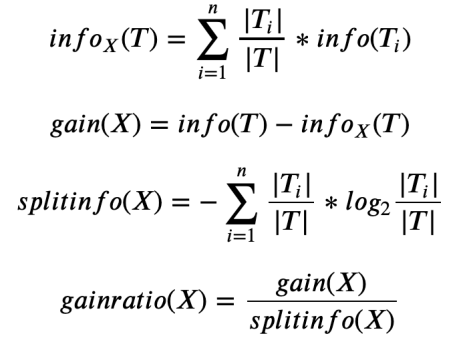
The interesting part first to me was that gainratio was not necessarily a typical change ratio. Other wise gainratio = (gain – info) / info. However, there is still some difference between split info and info.
Splitinfo is merely looking at how many records got split into each buckets, and it doesn’t worry about how “pure” each bucket is nor class distribution within each bucket. However, for info_X(T), test X will determine how training records go into which bucket, and likely there will be misclassification, then the info_X(T) will be calculated as not only on each bucket, but within each bucket, it will be calculated as the info within that bucket which has nothing to do with test, purely got class got distributed within that bucket. Or in another way, splitinfo even has nothing to do with the accuracy, not even using the label data. But info does.
Intuitively speaking, info_T won’t change, but as we apply different tests, T might get sliced and diced into different buckets (two buckets for a binary tree split), and then info_X(T) will change.
Assume that we find a group of test which split the training data into the same amount of proportion, say always 50/50, then the T_i / T part will always be the same, but depends on which class go to which bucket, the info(T_i) part will be different. So let’s assume that we have a good split, all cases within the same bucket has the same class. Then we know T_i will be 0 as it is so pure like the probability within the logarithm will always be 1, and there is no uncertainly. However, if the classification is not pure, then the log will be negative and everything will be positive, and maximized when it is completely random.
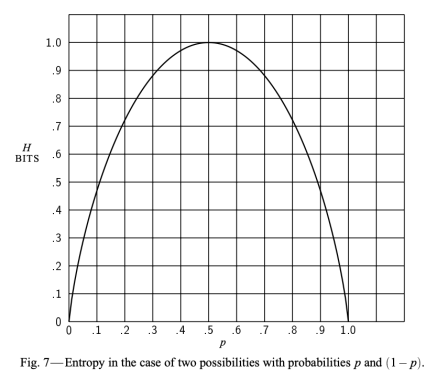
That sort of explained if we are trying to find the best split with the highest gain, we will need to find the split X with the lowest info, highest “purity”. However, a definitive approach of having the purest division is to have one branch for each record, but that is also the secret and that defies the philosophy of generalizable pattern recognition. So that is why Quinlan introduced the term gainratio which stops that from happening? how? because if we tend to over fit, there will be lots of buckets, and T_i/T will become small, really small if you have lots of classes, like a training data that has a primary key – unique values. so if we have n buckets: splitinfo = n * (1/n) log (1/n) = log(1/n) which will be a big number when n increased and the denominator of gain ratio will increase, which achieved the goal of not overfitting.
Well, that makes sense but doesn’t make sense at the same time. The goal is clear but the number of approaches to achieve the goal is endless. I do have the question that is there any reason that one criterion is better than the other, and if so, is there a possibility that there is a criterion that that will work the best without overfitting. Information theory is a theory in essence, and people trying to apply it might not applied it in a perfect way, for example, another commonly used criterion is Gini impurity which is defined as sum(p(1-p)), it has a surprising resemblance to info gain but instead of log(p), they used (1-p)? well, clearly, anything that has a reverse force has its legitimacy or maybe even other function like p * sin(p), or p * 1/e^p or … anything else.
Also, the common decision trees today are usually a binary tree that meet the criterion of yes or no, but is it necessarily the most accuracy or even efficient way of contructing a tree? certainly any other decision tree can be represented by binary tree but is it the best? just like people use B-Tree rather than binary search tree, ..etc.
Most importantly, even Quinlan mentioned in his book that building the smallest decision tree consistent with a training set is NP-complete [Hyafil and Rivest, 1976]. There could be 4M different trees for the sample example that has only a handful of records. How can you be sure that there isn’t a better way of doing this? …
Maybe there is an engineering approach to simulte and search for the best and generic approach, if there is one 🙂
