Autocomplete is a feature that dramatically improves users searching experience. So what is autocomplete or suggester if you have never seen these terms before.
Here is a screenshot of how autocomplete and suggest looks like in Google.
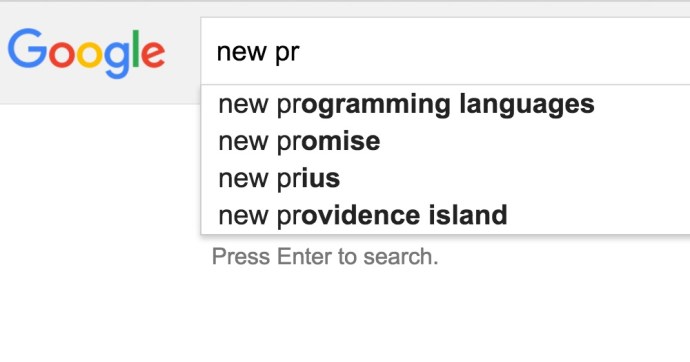
If you want to learn more about how suggester works in Solr, here is a confluence article I found very helpful.
There are two definitions that I want to highlight, data dictionary and lookup implementation.
Lookup-Implementation: “The lookupImpl parameter defines the algorithms used to look up terms in the suggest index. There are several possible implementations to choose from, and some require additional parameters to be configured.”
Dictionary-Implementation: “The dictionary implementation to use. There are several possible implementations, described below in the section Dictionary Implementations. If not set, the default dictionary implementation is HighFrequencyDictionaryFactory unless a sourceLocation is used, in which case, the dictionary implementation will be FileDictionaryFactory”
Here I am going to share how to get the dictionary factory up and running and in this case, I will use the filedictionaryfactory which Solr will locate an external file where the suggestions are specified.
FileDictionaryFactory
“This dictionary implementation allows using an external file that contains suggest entries. Weights and payloads can also be used.
If using a dictionary file, it should be a plain text file in UTF-8 encoding. Blank lines and lines that start with a ‘#’ are ignored. You can use both single terms and phrases in the dictionary file. If adding weights or payloads, those should be separated from terms using the delimiter defined with the fieldDelimiter property (the default is ‘\t’, the tab representation).
This dictionary implementation takes one parameter in addition to parameters described for the Suggester generally and for the lookup implementation:”
I first created a suggestion file under the collection folder (techproducts). And here is how the file looks like:
$ cat ./example/techproducts/solr/techproducts/bwsuggester.txt
# This is a sample dictionary file.
acquire
accidentally\t2.0
accommodate\t3.0
alex\t4.0
test
test1\t1.0
test2\t2.0
test3\t3.0
ceshi
ceshi1\t1.0
ceshi2\t2.0
ceshi3\t3.0
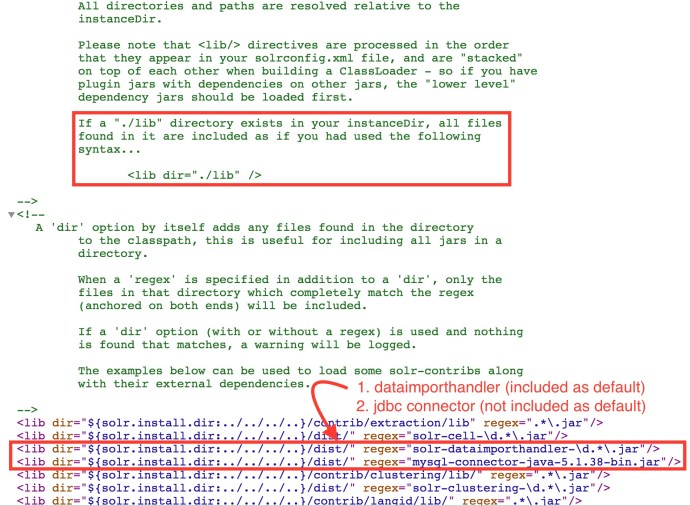
And then you need to modify the solrconfig.xml to use the filedictionaryfactory:

In the end, you can restart solr by issuing the commands:
bin/solr stop -all
bin/solr start -e techproducts
They should restart solr and take the latest configuration file into consideration.
Then lets take a look at the how to query the suggester using Solr API.
http://localhost:8983
/solr/techproducts/suggest?
suggest=true&
suggest.build=true&
suggest.dictionary=mySuggester&
wt=xml&
suggest.q=ceshi2
And here is how the result looks like:

The good news is Solr is already using the external suggestion dictionary that we provided. But the bad news is that it did not parse out the weight correctly and more work need to be done.




 In the end, everything works out of box 🙂
In the end, everything works out of box 🙂