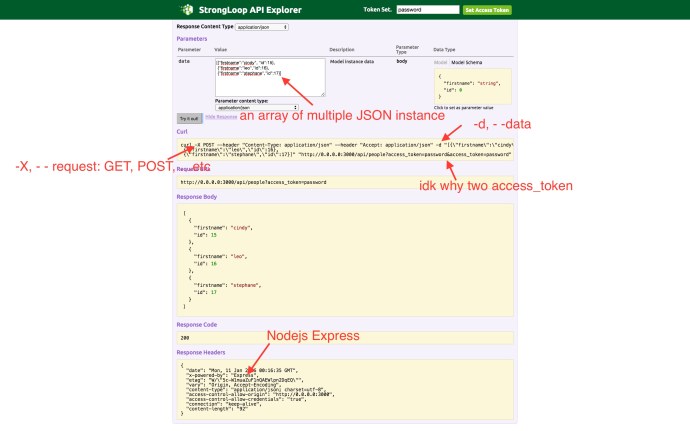
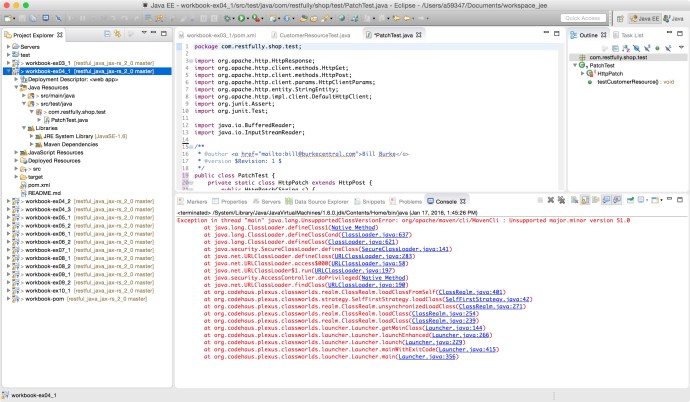
Following this quick start tutorial, I realized that they have been using the bin/post command a lot for testing. And the terminal returns this type of response.
$ bin/post -c gettingstarted example/exampledocs/books.csv
/Library/Java/JavaVirtualMachines/jdk1.8.0_66.jdk/Contents/Home//bin/java -classpath /Users/datafireball/Downloads/solr-5.4.1/dist/solr-core-5.4.1.jar -Dauto=yes -Dc=gettingstarted -Ddata=files org.apache.solr.util.SimplePostTool example/exampledocs/books.csv SimplePostTool version 5.0.0 Posting files to [base] url http://localhost:8983/solr/gettingstarted/update... Entering auto mode. File endings considered are xml,json,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log POSTing file books.csv (text/csv) to [base] 1 files indexed. COMMITting Solr index changes to http://localhost:8983/solr/gettingstarted/update... Time spent: 0:00:00.077
This is an example how Solr index csv file out of box, in the quickstart tutorial, Solr has indexed all different types of input files including but not restricted to CSV. Then I started feel so curious, what else can this magical SimplePostTool does!
Here is the Java doc for class SimplePostTool. Here is a perfect on line description of SimplePostTool
“A simple utility class for posting raw updates to a Solr server, has a main method so it can be run on the command line. View this not as a best-practice code example, but as a standalone example built with an explicit purpose of not having external jar dependencies.”
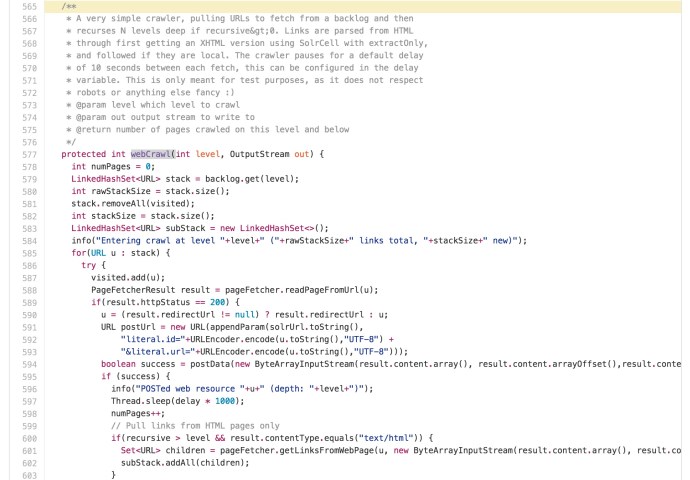
There is a very interesting method called “webcrawl”:
protected int |
webCrawl(int level, OutputStream out)
A very simple crawler, pulling URLs to fetch from a backlog and then recurses N levels deep if recursive>0
|
Here is the help manual of SimplePostTool:
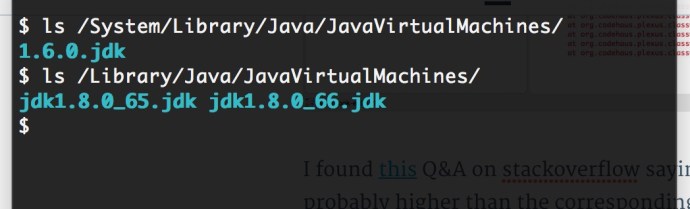
$ /Library/Java/JavaVirtualMachines/jdk1.8.0_66.jdk/Contents/Home//bin/java -classpath /Users/myuser/Downloads/solr-5.4.1/dist/solr-core-5.4.1.jar -Dauto=yes -Dc=gettingstarted -Ddata=files org.apache.solr.util.SimplePostTool -h
SimplePostTool version 5.0.0 Usage: java [SystemProperties] -jar post.jar [-h|-] [<file|folder|url|arg> [<file|folder|url|arg>...]] Supported System Properties and their defaults: -Dc=<core/collection> -Durl=<base Solr update URL> (overrides -Dc option if specified) -Ddata=files|web|args|stdin (default=files) -Dtype=<content-type> (default=application/xml) -Dhost=<host> (default: localhost) -Dport=<port> (default: 8983) -Dauto=yes|no (default=no) -Drecursive=yes|no|<depth> (default=0) -Ddelay=<seconds> (default=0 for files, 10 for web) -Dfiletypes=<type>[,<type>,...] (default=xml,json,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log) -Dparams="<key>=<value>[&<key>=<value>...]" (values must be URL-encoded) -Dcommit=yes|no (default=yes) -Doptimize=yes|no (default=no) -Dout=yes|no (default=no) This is a simple command line tool for POSTing raw data to a Solr port. NOTE: Specifying the url/core/collection name is mandatory. Data can be read from files specified as commandline args, URLs specified as args, as raw commandline arg strings or via STDIN. Examples: java -Dc=gettingstarted -jar post.jar *.xml java -Ddata=args -Dc=gettingstarted -jar post.jar '<delete><id>42</id></delete>' java -Ddata=stdin -Dc=gettingstarted -jar post.jar < hd.xml java -Ddata=web -Dc=gettingstarted -jar post.jar http://example.com/ java -Dtype=text/csv -Dc=gettingstarted -jar post.jar *.csv java -Dtype=application/json -Dc=gettingstarted -jar post.jar *.json java -Durl=http://localhost:8983/solr/techproducts/update/extract -Dparams=literal.id=pdf1 -jar post.jar solr-word.pdf java -Dauto -Dc=gettingstarted -jar post.jar * java -Dauto -Dc=gettingstarted -Drecursive -jar post.jar afolder java -Dauto -Dc=gettingstarted -Dfiletypes=ppt,html -jar post.jar afolder The options controlled by System Properties include the Solr URL to POST to, the Content-Type of the data, whether a commit or optimize should be executed, and whether the response should be written to STDOUT. If auto=yes the tool will try to set type automatically from file name. When posting rich documents the file name will be propagated as "resource.name" and also used as "literal.id". You may override these or any other request parameter through the -Dparams property. To do a commit only, use "-" as argument. The web mode is a simple crawler following links within domain, default delay=10s.
In the end, you can get the crawler working by entering the command:
java
-classpath /Users/myuser/Downloads/solr-5.4.1/dist/solr-core-5.4.1.jar
-Dauto=yes
-Dc=gettingstarted
-Ddata=web
-Drecursive=3
-Ddelay=0
org.apache.solr.util.SimplePostTool
https://datafireball.com/
SimplePostTool version 5.0.0
Here is the log of crawling datafireball.com at the depth of 3: solrwebcrawl_datafireball
For more information about how the webcrawler was written click here.
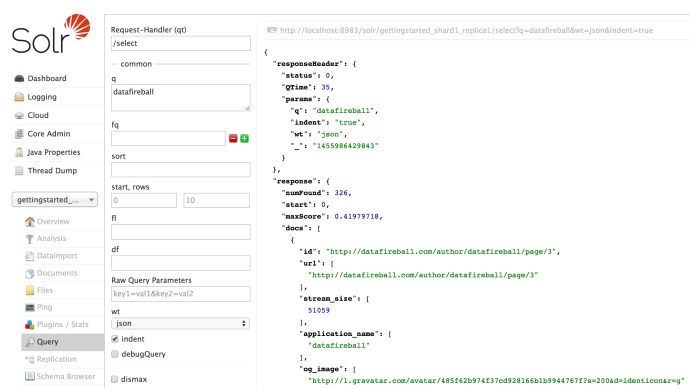
In the end, here is how the data is indexed:









 Here
Here