There are two key concepts in parsing any Python code, one being the concrete syntax tree and the other being abstract syntax tree. This post provide some introductory information about what they are, their roles in the parsing process, commonalities and differences between them.
In fact, as this post is written in 2021, it is a possibility, or probability that the term CST might be rendered obsolete because of the new parser implementation parser in newer versions of Python. parser is a built-in python language that has been there for a long time that works with CST. However, given the latest implementation, it won’t be a two stage process CODE -> CST -> AST anymore. As CST is still a very important concept in understanding any programming language, I think it will still be a good idea to learn about it since it will be a while for us all to move into 3.9 and CST and AST still serves its general educational purpose when it comes programming language.
CST is the exact parsed tree representation of your code conforming to the language grammar, while the AST is a simplified CST keeping only its gist. Based on this Stackoverflow post, depending on how the developer writes the code, eg. a = 1 + 2 * 3, there could be different variations like a = 1 + (2*3) or a = (1 + (2*3)), the CST for each variation is different as the code literally are different, the CST will contain all the different placement of parenthesis. After all the operation precedence got taken into considerations, the CSTs will be simplified and end up being the same AST. Of course, for the same CST, if the underlying executions are different, the same code can lead to different AST.
In the following example, two implementations have different CST but all share the same AST in the end.
Today I was studying the notebooks that published along with the book AI Powered Search and realized that author was using the “fence code block” quite a lot. We all know the jupyter notebook comes with the markdown which is a content focused language. To be content focused, it means the users use the precanned markdown syntax to explicitly set the relationship between contexts, like what is a header, what is a paragraph. In that way, you don’t have to worry about the formatting yourself, as there is a fixed way and consistent way of doing it. If you ever failed to add in a new line in your content, you will understand that this “inability of adding a new line” is a feature and benefit that comes with Markdown (just like latex) instead of a bug (“this sucks, I cannot even add in a new line”).
Attached are several markdowns of using the fenced code blocks.
Can you guess what will be the output after it is rendered?
Even if there seems like two new lines between L1 and L4. Due to the very reason mentioned above, Markdown will treat as two paragraphs and only insert a new line. And the fenced code block will be treated as inline, if the opening triple backticks are on its own line, like L11, it will be formatted as a standalone code block with a different formatting. Inline code blocks comes with greyed background while standalone comes with a white background but indented differently. In addition, when you have fenced code block with a programming language next to the open backticks, the text within the code block will be highlighted per the syntax of that programming language.
When you consider deploying your model into production, a key step is to understand the resource requirement. It is not only the machine learning prediction part, but everything that goes inside the container. This requires us do some profiling and understand the performance of the container under different scenarios of load.
Here we are going to profile the container which has the local deployment of the sample AzureML project – diabetes prediction which is a ridge model.
The concept is simple. We artificially generate some requests, test the performance under different resource allocation – how long it took to serve these requests. If the computing resource is insufficient, your container will be slow. On the other hand, if the resource is over allocated, your performance won’t improve further and extra resource will only be a waste of money.
The first question will be how to create the load. Ideally, you will want to the payload to be as close to production requests patterns as possible. For example, if you reuse the same payload and only change the number of requests, there could be activities like caching that skew your tests results (your code looks faster in testing but act slower in production). And at the same time, the true performance of a web server can hardly be measured synchronously. You can also make asynchronous calls to maximize the throughput.
Here is a small test script to demonstrate the idea. You can pass in the number of workers and the total number of requests for a test, and the final returned value is how long it took to finish all these requests, ideally the shorter, the better.
After you have a test script, the next step is to try out different configurations and take some measurements.
In this test, I am only changing different cpu_limit assigned to the containter.
cpu_limit is a threshold that your container at most can consume. There are many other parameters could limit the actual cpu resource available to your container. For example, setting cpu_limit to be 24 doesn’t guarantee any type of cpu resource available. In a typical laptop, you might have only 4 cores in the first place. In that case, setting cpu_limit to be 24 makes no sense. Another is competing activities, if there are other activities during the testing, the cpu available to your container could take another hit.
During the test, if the payload is low, and your application is perfectly capable of handling it, you might not reach either the physical and cpu_limit assigned to it. During the stress test, you probably want to avoid other irrelevant activities so the cpu resource available is sufficient and it is only the cpu_limit that you apply actually dominates.
In my testing script, I generated a list of cpu_limit starting as small as 0.01 cpu ~ 10 millicpu. (I actually started with large cpu assignment because they finish faster). And for each cpu_limit, I tried out different number of workers to simulate the behavior of required concurrency.
Following is the result of the first test, instead of 1000 calls per test, I used 100 calls just to be fast. It is quite straight forward that the more CPU resource you assign to it, the better the performance. For example, when you assign 0.512 cpu, it took only less than 3 seconds to make a 100 calls. And by giving it more cpu, the performance is not further improved. Meanwhile for the worker count, the performance is improvement is not obvious as you expected. One imagine that if the tasks is io bounded, having two workers will double the throughput etc.
In the next test, I increased the number of calls from 100 to 1000. And you can immediately see the performance improvement from the client side. When you assign sufficient cpu, the performance will keep improving from the client side the more workers you assign, until no more.
How surprising! The more resource we give it, the faster we get? 🙂 This is like a typical optimization problem that for a fixed amount of CPU resources, how to size the container so we can handle the most throughput.
Let’s do some math, say if we have total TOTAL_CPUS, and each cpu is being sized with the cpu_limit as SIZE. Then we can afford TOTAL_CPUS/SIZE number of containers without running out of resources. Based on the our choice of SIZE, we will be able to understand how many requests each container can handle.
In order to find the optimal point, let’s first model the response time versus the cpu_limit. We can fit a curve to it. In this case, I picked the exponential decay curve and it works pretty well.
My take away is that the smaller you can make a container, actually the more efficient it is despite the fact that it will be slow. As you can see from the blue line, the latency is getting better and better as you throw more cpus to it, but that limit the total number of containers that you can fit into an environment, and the overall total time almost grow linearly.
Rather than find the optimal point, this is almost like a greedy theory in which you just need to understand what is the acceptable SLA, and almost work backwards and chose the minimal amount of cpu to guarantee that SLA. In addition to that, any extra cpu assignment won’t help at all.
As we have discussed previously, finding the most efficient keyboard could be viewed as a shortest distance problem where we arrange all the keys in a way that will minimize the total traveling distance given a specified typing task.
At first glance, it is different from commonly used graph algorithms as they mostly start with a graph (V, E) and our problem is actually to find the graph given the path. This blog post is meant to implement a solution using dynamic programming, reducing a challenging problems into smaller ones and then we will discuss the efficiency next.
Previously we have mentioned that there are n! permutations of different key layouts. For example, we face n different possibilities when we decide the the position of A, then if we fix B, there could be n-1 positions available as one position just got occupied by A, so on and so forth. We have n*(n-1)*…*1 = n! possibilities.
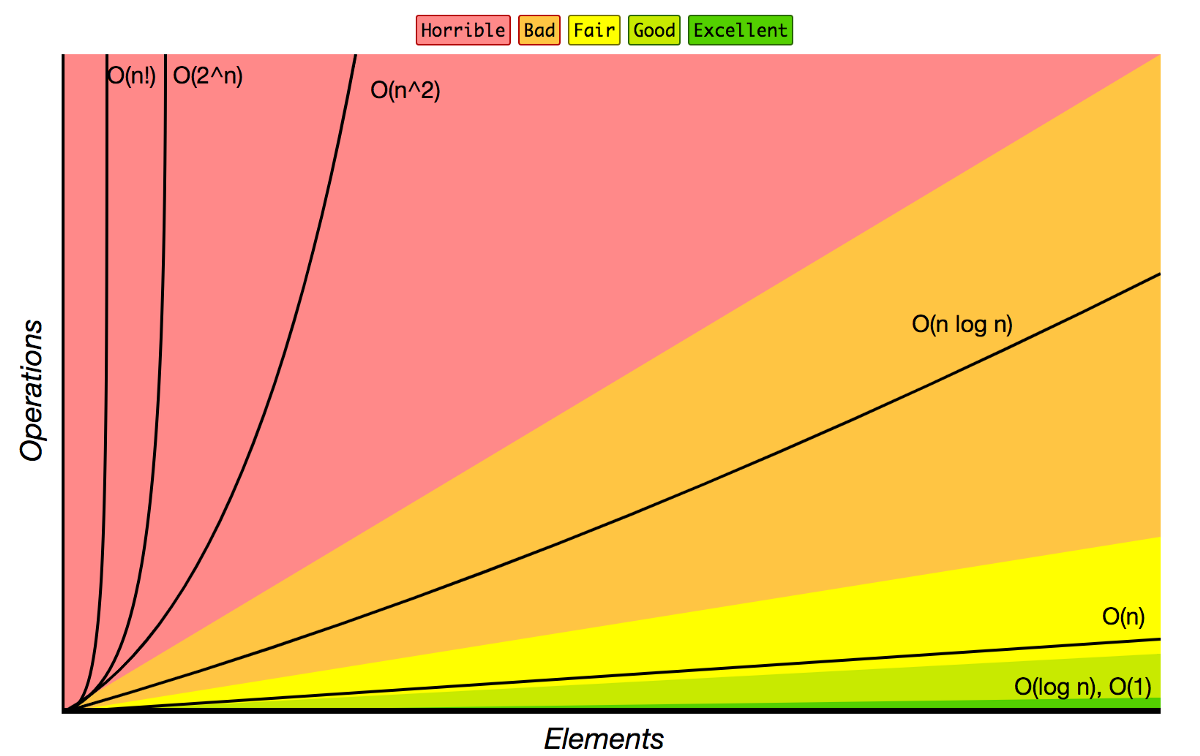
To refresh everyone’s memory, here is a graph of computational complexity. Factorial growth is obviously the worst growth pattern, so bad that with only 60 elements, you can end up with 60! ~ 10e82 which is the same number as the total atoms count in the known universe. Actually, there are more than 100 keys on a full size standard keyboard. So here we go, we know that a brute force approach will stand no chance of searching for the best layout.
Now let’s discuss what are some of the unique properties that might enable us to avoid some searches. Or if we view our search paths as a tree, what are some techniques that we can use to prune the tree. Or can we reduce a huge problem into smaller subproblems.
Say for example, we need to map N characters to N keys and there also exists a typing task which is a sequence of those characters which we need to enter. There must exist one or at least one layouts that will yield the shortest distance. So let’s find a random layout called L. And we can decompose the total cost into several components. In the layout, let’s start with a key say K1.
Total Distance for L = Distance (sequences that contains K1) and Distance (sequences that don’t contain K1)
To be more specific, the sequence is a simple string of characters which we can break down into pairs of characters (from, to). For example “hello” can be broken down into “he”, “el”, “ll”, “lo”. If we pick character “e” as the target, the total distance can be categorized into two groups, (“he”, “el”) and (“ll”, “lo”). The reason being now we can reduce it to a smaller problem, one that is independent and easier to compute. In Distance (sequences that don’t contain K1), it has one less key, one less position, and the sequence doesn’t contain K1.
Distance (sequences that contains K1) is not determined yet as it is dependent on the positions on the rest of the keys. This is also the part where we can potentially improve some efficiency as the frequencies are not evenly distributed, you probably have pairs like “th” much more often than “xz”. If we will be able to follow certain order (maybe by frequency) when loop through all the keys, the most influencers will be focused on first. Even if we cannot afford a full search and we still follow a strategy like breath first search, those unknowns might only contain less frequent used keys, positions and pairs which could be immaterial so it might turn out to be a good approximation.
D(K, P) = sum( D(k, p) + D(K-k, P-p) ) for p belongs to P for a given k
If we need to first and only fix one key, and this key can have certain number of positions, for each position, we can call the same function to a smaller problem for the rest of the keys and rest of positions.
By looking into this search tree, we can find opportunities for improvement. For example, In K2 layer, there should be N * (N-1) total children, but in reality, we can cascade down to layer N-2, we already see computational duplications that can benefit from memoization. For example, when we fix K1 at Pos_i and then fix K2 at Pos_j contains the same subproblem as we fix K1 at Pos_j and then fix K2 at Pos_i. How many redundant calls we can eliminate, N*(N-1) – C(N,2).
Now if we go deeper, for any given layer i, we theoretically will have N * (N-1) * (N-2) * … * (N+1-i) in the most naive way but there will be tremendous amount of redundancies. We will have (N-i) many keys that need to be mapped in the next layer.
There is an interesting property of combination. Which C(N, i) = C(N, N-i) = N! / (i! * (N-i)!). Intuitively speaking, we have N nodes in the first layer, and we can also say at the very last layers, we only need to calculate how to place that last key on the keyboard which is still N different choices. Given this symmetric property, the real execution actually has a shape similar to an envelope where the head and tail are skinny and grow as it approaches the middle.
So in layer1, there will be N = C(N,1) nodes. In the last layer, we also need only N = C(N,1) nodes. So if we are going to arrange 26 keys. The widest layer will be right in the middle. C(26, 13) = 26! / 13! / 13! ~ 10e6 ~ 10 million, this is much smaller than 26! ~ 10e26.
So the total nodes across all the layers can be summed up as:
C(N,1) + C(N,2) + … C(N,N) = 2^n, actually the complexity is exponential rather than factorial. This is a huge progress by just using memoization.
As you can see, this only includes the recursion part, it still has not included the known key part. As we fix more and more keys, it position will need to propagate back to the previous layers to update the distance. So, let’s think about how complex that will be.
When we fix one key, the typing pairs related to that one key will be stored separately and excluded from future recursive calls, and its value can only be gradually updated as more and more keys got fixed.
In the first layer, we have N positions, and all those N branches share the same characters pairs as they are the same subset related to the key that we are fixating. The only difference being that key is being stored at different positions.
In the 2nd layer, we have N – 1 positions left with N – 1 characters. And we fix another key, as we are positioning the second character at N -1 positions, it will go back to the previous step and being able to calculate the distance with pairs that contain these first two keys. In reality, we will have N*(N-1) different unique position pairs that we will be able to populate. There is an interesting property here as switch the position between two keys won’t change the distance, so in reality, we only need to calculate N*(N-1) or C(N,2) positions pairs. At the same time, it will identify and include all the pairs with key2 (without key1), store it at this layer and send the rest of the pairs (without key1, key2) to the next layer.
In the 3rd layer, we fix another key with N-2 positions available. As we now have the 3rd key positioned, it will send its position to the previous layers. It will not only send its position to the 2nd layer so the pairs with key2, key3 can now being computed, and theoretically speaking, there is also C(N,2) positions or pairs that we need to calculate. Also send back to the first layer so key1 and key3 and also now being computed. So the total is C(N,2) for key1 and C(N,2) for key2, which the total “call back” are like 2*C(N,2).
So on and so forth, we can calculate the total work for this kind of call back
Total Call Back = 1 * C(N,2) + 2 * C(N,2) + … N * C(N,2) = (1+2 + … + N) C*(N,2) = (1+N)*N/2 * N * N (N-1)/2 ~ N^4
Comparing with the recursively calls 2^N, N^4 is still polynomial and its computational complexity is probably so small that can be ignored as we increase N. (eg. if N=30, 2^N=1B, and N^4 < 1M).
Thoughts:
Is there something else that we can leverage by looking into the properties of our specific problem?
As we are searching for the minimum, there could be cases that we might be able to prune the a whole branch of tree if there are cases that “we have not arranged these keys yet, but assuming that they all share the same possible minimal distance, the sum still exceed our record minimum, then we can give up those branches completely”.
Looking into the distance calculation, it is strictly looking up spatial distance in a 2D Euclidean space through like a distance matrix, if that is the case, is it possible to vectorize some of the calculations so we are not going to boring for loops to improve efficiency.
Taking legacy QWERTY layout into consideration, a complete different layout without material improvement won’t be well accepted. Is it possible that we start with qwerty and then switch keys 1, 2, 3 at a time so the majority of the layout stay intact but we find the ones that with the highest return on investment given the minimum amount of changes.
There are many other approaches to solve NP-hard problems which I other people advised me this problem belongs to. Like certain type of heuristic search, simulated annealing, genetic algorithm or different types of reinforcement learning. Those all will be interesting topics to look into.
Before we think about how to find a better algorithm, this is actually already too much talk and we better off write some program to evaluate our reasoning making sure it is not flawed. In the next post, we will be writing some programs and validate many of the statements here.
Likely you are using a keyboard with the letters ‘q’ , ‘w’, ‘e’, ‘r’ on the top left, which is also commonly being referred to as the qwerty layout. This layout was created in 1870s. You may have asked the same question as everyone first started learning typing “why A is not next to B, why the layout looks like total random”. The answer to it was the inventor back then claims this randomness actually helps improve the typing speed by distributing the tasks equally to different fingers, and also due to some mechanical designs limitation that jamming too many frequently typed keys together is not a good idea.
Nowadays, many of those premises no longer holds true and constraint also being removed. Now you can literally make the keys as small as you want, or concentrate certain keys as close as you want without worrying about physical limitations. At the same time, the content that end users entered has also shifted so much that certain keystrokes got typed more frequently than 150 years ago. For example, in the modern digital world, the symbols got typed much more often and sometimes dramatically exceeded even certain letters. For a programmer, they use symbols like semicolon as frequently as how writers use period because semicolon actually means end of a statement in several programming languages. In a typical tweet, people have to use characters like “@” and “#” maybe without using any traditional punctuations.
There has been some efforts to adjust the keyboard layouts by adding certain keys like multimedia keys but the qwerty has certainly never been challenged to a degree that the society cares enough to make a change. Maybe because it is not a problem at all. I agree that for those who work extra hours they certainly not think because they cannot type fast enough. And maybe it is just such a prevalent layout that the cost of change and inconvenience that it will cause outweigh the benefit (many softwares like video games, editors actually choose certain shortcuts because they were convenient under qwerty).
The question now becomes, can you quantify the efficiency or even prove that for a different layout, there will be a significant efficiency gain, or if we take it one step further, out of all the different layouts, is there a way that we can find the most optimal layout that worth the effort to ditch what everyone has been using for the past 150 years.
Key Performance Indicator
There is a saying “if you cannot measure, you cannot manage”, so let’s first start by coming up with a way of measuring efficiency. There are common metrics like (word per minute – WPM) that people use to brag to their friends how fast a typer they are. If we introduce a different layout to two groups of people who are not biased (maybe students or kids who are just learning typing). That will be a great experiment. However, just like covid vaccine test, in order to be scientific, we will need to conduct experiments and the cost of that is just too prohibitive at the early selection stage. But sometime down the road, it certainly will be required.
Now let’s think about the typing process, it boils down to a sequence of actions about moving fingers fast and accurately to push down certain button. There has already been tremendous amount of conversations around what kind of keys are the easier to type, then there comes along inventions like mechanical keyboard, what kind of cherry switch is the most suitable, clicky versus linear etc. However, it is quite obvious that time spent is not only about pushing the button, but also moving the fingers to the right position. Think about how easy it is to type “asdf” because it is literally all next to each other. Now try to type “?\=`”, you will need to lift your pinkie finger to the corner of the keyboard and move it around even with the assistance from your eyes too.
So maybe one angle when we are looking for the best key layout is actually to seek for one that that the user to not move their fingers that much.
For those of you who has an engineering background, this probably already sounds similar to an optimization problem and some of you might already start thinking about “shortest distance”, “traveling salesman”. Yeah, there are many mature algorithms which is designed specifically to solve similar problems and find the shortest distance.
The question is now “can we find a keyboard layout that yields shorter traveling distance than ‘qwerty’ or even better, can we find the best layout that guarantees the shortest travelling distance given modern typing task”.
There are many assumptions that we are going to make in this exploration process and those assumptions might be too naive which lead us to flawed conclusion, but they will dramatically help simplify the problem at the beginning and we can challenge them later and build more complexities as we want.
Key Positions and Size
In a typical keyboard, most keys are same size (square or round) key caps that are perfectly aligned horizontally and tiled vertically. Certain keys even come with a different size like space bar being the biggest, left and right shift, enter, etc. For now, let’s assume that all keys have the same size and are positioning perfectly on a meshgrid, like a chess board. In that way, it is much easier to calculate any distance for two given keys without worrying about the specifics. Another benefit is that the keys can be stored in certain data structure and being calculated in an efficient way like ndarrays when it comes to computing.
Characters
Each key on your keyboard usually carries two meanings like you can change the case for letters and entering a different symbol by holding the shift key. This is certainly an important topic as it is those symbols that previously got assigned to the corners or even share the same physical switch that grows its usage lately. If there is a need to separate out certain characters, or even promote certain character to be at a prominent positions are certainly changes that worth exploring. In that case, we will treat all printable characters on a keyboard as its own entity with several exceptions.
Maybe for numeric characters, it worth the effort to exclude them for now as regardless of which frequency to use, they gains its benefit of staying in the numerical order regardless of its usage. At the same time, the case for letters might keep sharing the same key as I can totally imagine what kind of criticism that we will receive if a share the same key as upper case Z. What the hell? There might certainly relationship in symbols like pairs of brackets, smaller than or greater than. In reality, there are even autocomplete features that very few developers have to type the closing parenthesis or brackets because they come autocompleted by IDE. In that case, maybe temporarily removing those closing symbols also makes sense.
So now this is what we ended up with 58 characters:
This is probably the most important part of this analysis as it directly determines how our final score will get calculated.
Simple Travel Distance
A naive scenario will be treating all different keys as physical locations. Calculating the total traveling distance for typing a sentence will be equivalent to calculating the total distance of a taxi trip which we just need to sum up the distance between subsequent characters in this physical space.
In order to type the word “hello”, it includes 5 keystrokes and 4 inter button movements. The totally traveling distance will be the sum of moving D(h, e), D(e, l), D(l, l) and D(l, o). One might say that D(l,l) requires no travel at all as it is just pushing the same button twice.
In our case, we can easily calculate the Euclidean distance between e and h as their horizontal difference is 3 and vertical difference being 1. So based on the Pythagorean theorem that the direct distance will be calculated as sqrt(3^2 + 1^2) = 3.16 = D(e,h). In this way, we can calculate the distances being
Well, pretty straightforward right? so let’s see if we can write a small Python script so it can be calculated easily.
After we populated the keyboard layout for qwerty and extract the coordinates, now we can write a function that takes in any given layout, any given text, and then we will calculate the total traveling distance. (note: the np.linalg.norm is a pretty handy and high performing function to calculate the Euclidean distance between coordinates)
It matches our calculation!
Different Layouts in Action
Now we have some basic functions to help us evaluate performance. Why don’t we feed it some real life layouts and content and see how it works in action.
So far, other than qwerty, there are indeed some alternatives like coleman or dvorak. Let’s create those two layouts and compare it with qwerty.
In order to work with some real life content, there are some small adjustments that I made to the code which I previously mentioned to skip through travels which involves the characters that we have not entered yet. And also created a counter so the returned travel distance is normalized so we can compare it across even different content or text length.
Here we grabbed the Shakespeare’s sonnets from the Gutenberg project and it is interesting to see that our popular qwerty outperforms other mainstream layouts by quite a bit.
However, now this prompts a few other questions:
is there any other layout that we can generate that proves to outperform qwerty. In theory, we can generate all the possible permutations of layouts and calculate the travel distance for each and find the best one, is it computational feasible, is there a good algorithm that we can use, if not, will there be any approximation technique that we can deploy?
here we are assuming that we actually have only 1 finger. In reality, there are regions and the distance should be calculated in a different way that letter “f” and “j” are really fast traveling wise as both of your index fingers are resting there.
we should also try to work with some different content just to play with as there might be some adjustments depending on your profession that certain keys might need to be adjusted
Hopefully this helps you understand the keyboard is actually a fascinating topic and I will try to cover some of the pending questions in more depth in future writings.
I have a interesting question that is related to calculating the shortest distance. However, rather than choosing a path for any given graph (vertices and edges), in this problem, the path is given and it requires generating a graph under certain constraint.
So let’s go through this problem in a bit more detail:
Problem
There is a fixed amount of positions (N) into which we need to place N different objects. The traveling distance between all the positions are pre-determined and fixed. The task includes a sequence of objects to pick in an order that cannot be changed and the same objects can be picked multiple times. The question is how to place those objects in an order so that the total traveling distance can be minimized.
Example
Now, let’s give an example.
Position
Assuming that we have 4 positions in a 1D dimension (list). And we can easily calculate the pair wise distance between those positions.
P0
P1
P2
P3
P0
0
1
2
3
P1
0
1
2
P2
0
1
P3
0
Task
Now let’s go through our task. Our task might be any sequence of any length of different combinations of 4 objects. For example, it could be 1232213. It means first to pick up object1, and then pick up object2, then 3 so on and so forth. To calculate the total distance, it is as simple as adding up the distance between each objects. (for the first element and last element, we can simply by assuming a situation which all picks needs to originates from a starting point and ending point that doesn’t belong to any of these positions, but they take equal amount of travel to go to all the positions). In that case, our total distance will be:
Distance is a function of positions and to pick objects, objects will be mapped to the position.
Distance between two objects x, y = D(p(x), p(y)) where p is one mapping
Scenario1
Keep in mind that the numbers above are not indices to positions, they are objects. But if we put all the objects in the same order as the positions, the calculation is as straight forward as:
So far, we have two different positioning and each yields a different total traveling distance. And the default one is considered better than the second one.
The goal is to find the most optimized positioning that yields the shortest total distance.
Bruce Force
Here is a small demo of the bruce force approach given 4 objects at 4 positions. There are in total 4! = 24 different permutations and there are two positioning that yield that shortest distance. Luckily, one of the examples that we covered above happens to the the most optimal solution.
I have thought about some of the previous models that I have worked with but none seems to be a good match right off the bat. For example, the Dijkstra is to find the shortest path or sequence given the graph, the Knapsack’s is to find the subset of the goods to maximize the weight.
Now the question is can we find an existing algorithm that solve this problem in an efficient way, if so, how efficient?
Honestly, I have never been a work-from-home person, at least not used to. When I was in school, I was the kind of student that only studies in the library or the classroom, very rarely in the dorm. When I started working and even after being a home owner, I am still the kind of person who come by the office during the weekend just because I feel more “productive”. Everyone faces different kinds of challenges and live in a different way due to the pandemic, and the biggest change to me is work from home.
As the pandemic is getting worse, I realized that we might be there for a long run, or frankly speaking, this might just be a permanent change that industries need to switch to. I started to accept and think about ways to reflect and consider options to improve my work productivity and personal comfort level and health.
There is a post where I will list some of the changes I observed and adopted and want to share this my readers.
Routine
Probably the most important part of working from home to me, is to establish a routine, one that suits you the best, your family/roomate the best and your team the best.
For me, I started by applying the same routine as if I was going to the office and then slowly came to the following schedule after trial and error:
Two meals a day: 8:30AM and 6:00PM: this is probably the biggest change to me as I used to have regular 3 meals a day and dedicated workout hours almost at daily level. During the pandemic, I changed and workout time become a luxury, frankly speaking only limited to light events like jogging, walking and some basic stretching. Having 3 meals turns out to be time and mentally consuming, inconvenient. I don’t feel the craving nor the happiness as I used to. Then I cut out my lunch and replace with snacks. To everyone’s surprise, it turned out to work great for me. For almost a year, my body weight has increased from 75kg to 80kg but most of the gain was at the first month or two, then it has been pretty stable since then.
Healthy food: “marry well”. I cannot over emphasize the importance of the quality of the food. Luckily, my lovely wife has been helping out preparing the food and meals and she is so well organized with usually a full weeks plan of what to eat with a great variety of diffrent kinds of food. All the raw ingredients have been ordered from Amazon Fresh. Our diet mainly contains high protein food like chicken, salmon, eggs, very little red meat and heavy in fruits, low fat and fiber.
unhealthy food: it might just be me, but sometimes I just become so craving for the “wrong” type of food, and my wife told me it is so visible that looks like I almost have my “menstruls cycle” for certain food. Later on, we agreed on having maximum two meals a week for restaurant take out (Pork Belly from Chinese food, or just classic Medium Pizza from Domino, hot dog or whatever the hell I want)
4000 steps a day: “long sitting is dangerous”, regardless of how comfortable your work station is, getting out and have some outdoor time is essential to me. I tend to start having lower back pain and higher level of intensity and anxiety if I sit too long, like long hours meeting, coding, or gaming. Avoiding big blocks of screen time by even taking a 10 minute break makes a huge difference.
sleeping: I do have to acknowledge that I have one of the most comfortable bed and mattress and I am proud of that decision when we first got our place. I tend to stay up late and thought that “I am taking advantage” by staying 30 minutes extra late watching youtube videos but we all know those hours are just biological debt that you owe and need to pay back one way or the other. I tried to guarantee at least 7~8 hours of quality sleep. And sometimes a 30 minutes to 1 hour nap really really makes a difference if you simply don’t know what is wrong but hell as sure something is wrong.
dog: these days are the best time to have a pet if you don’t already have one, if so, maybe get two :). My wife and I were dogsitting neightbour’s corgi for a long weekend and it turned out we had so much fun. Afterwards, both of us agreed that having a dog is a responsibility that we will be able to fulfill and an experience that we both want to have. Having being a dog owner for 3 month. I don’t regret the decision a bit, neither of us. An interesting observation I made is now there is someone else in the room that you can blame to when your partner started being unreasonable. You can start making up execuses like “puppy doesn’t like what you just said” and by having a common goal, this made my wife and I bound better and act as a responsible couple. There are so many to just being a first time dog owner. However, keep in mind, dogs are the best friends.
Home Office Setup
Now, let’s move on to the physicals, there are so many things that a real corporate office can offer you even unconsciously, the face time with your team members, the great chichat with the funny guy on your group, etc, or even not realizing how good the soda drinks your office did offer.
Here I will try to list several things that I purchased which greatly improved my home office experience.
Standing Desk: There are times that you just cannot be away from your keyboard, back to back meetings that requires your full attention. Remember, long time sitting is as harmful as smoking. I know that there is no medical evidence proving that having a standing desk has positive effect on your health but it makes a difference to me. By sometimes lifting and shifting the workflow for one hour. I relaxed my hip, my shoulder, and neck so much by unconsciously stretching, changing my pose, relaxing my wrists or just overall more freedom than what you can do on a chair. Also a great opportunity to have your butt breathe the air a bit, there are many medical reasons to it, my friend. Previously, I have got myself a cheap standing desk, or more like a laptop stand, the challenge is that it is very unstable and feels like a wabble head that you have to carefully type just so your desk is not shaking. Even with the expensive standing desk that I have, it is still not as solid as a real desk, but for light typing and conference calls, it works great. If you are doing some intensive typing like documenting or blogging, standing desk overall might not be the greatest experince, or there must be a higher price that you need to pay.
Monitor: I used to have a decent Samsung 27 inch as the extended monitor for my laptop. It used to, or at least I thought it was working great, until I changed later this year. During the holiday season, I just couldn’t resist the temptation to purchase some devices and after some research, I made my mind to purchase a fancy 34 inch ultrawide gaming monitor. Honestly, it is probably the best purchase decision that I made this year. It is different, very different, and that difference can feel uncomfortable at the beginning but once you get used to it, it is just so much better. You not only have more screen real estate, but by having a single pane of glass without two monitors is just an experience you have to try before you judge. I switched from Mac to Windows also this year. In windows, there are some basic features where you can snap windows, multiple virtual desktops, adjust the split between windows etc. I personally feel this being my biggest productivity boost so as the comfort level. The video game that I happen to play DOTA2 also support ultrawide screen and many applications, youtube videos now is just a pure net new experience a regular 27 can never offer you.
Headset: I bought myself a Bose Quiet Comfort35 due to the annual big discount on Amazon. It might saved only one less cable on my desk but improved the cleanness by a lot. Now you can comfortably swing by the kitchen or even the bathroom without losing the context or flow of your meeting because of the wireless. To me, I have a balcony and sometimes, I even put on my headset and just walk doors to relief my dog while still being able to work effectively. Also, as a resident in Colorado, having a headsets comparing with earpod is that yours ears will thank you for that warm cover.
Keyboard: Full confession, I bought several keyboards this year, maybe too many. I got myself a Logitech Mx Key, KeychronV2 red and KeychronV1 Low Profile brown. Bottom line, all of them are very different and you start to realize certain keyboards work best in certain scanerios. In the end, I nowadays use the MX keys most for day to day for regualr typing like work, coding and others and my cheap REDDRAGON blue switches for gaming. Every now and then, I swtich between all these keyboards just to get some fresh feeling.
Mouse: I replace my previously wired Razer Deathadder Elite with Razer Mamba wireless. Don’t take me wrong, the previous mouse works great for several years, the only reason I made the swtich was because of the cleaness because of the wireless. The mouse feel virtually the same to me but the experience is wireless is just great. The standing desk that I have
Docking Hub: I brought home my DELL working hub from work which works really well with my windows laptop. I have two PC laptops and sometimes hooking up all the peripherals are the most annoying experience if you do it on a daily level, or multiple times a day. This hub is a pretty solid as it can offer sufficient power of not only directly powering all your devices and laptop at the same time, but at he same time, it makes the switching to be one cable only and all the peripherals are directly connected to the hub itself. It also keeps most of the connections a bit far away from you so you don’t have all the wires and devices all tangled together right in front of you.
Writing Board: A very important experience missing out in the WFH days is the “white board experience” that you can no longer doodle with your colleagues and brainstorm for solutions and technical ideas. Yes, you can share screen and all kinds of stuff but have you tried to use your mouse to write anything? it is very hard. I bought myself a basic version of writing board XP-pen start G6740. I can easily plug it in and start white boarding by using either the built in app of windows or use the draw feature in Powerpoint to have productive and quality writing experience that others won’t. The only thing that I might regret slightly is it is still wired and you need to plug it in, but given the infrequent usage and the cheap price, I can live with it.
Cable Organizer: Packaging and modularizing is a very important concept in software developer, when things become very complex and you can gain benefit and simplicity by abstracting one level above. As I started to have more cables, charging stations, I purchase myself a cable organizer just to bury the cables. It looks certainly cleaner and that is all I need.
Here is a list of a devices that I have mentioned in my home setup in case you are curious.
The pandemic is not easy, but as long as we can all have faith, an open mind for change, adjust and adapt, we will come out of the other side finally, strong and better. Hopefully this blog post is helpful to you, if so, leave in the comment what other things you want to learn about my workflows and all the links at the end are affiliated with Amazon, by purchasing using the link I provided might help me explore more options which I can share later. Thanks for your reading and happy working from home.
Concurrent.futures is a module that started being included in Python since the release of version 3.2. That being said, in most of the Python 3 versions, like 3.5, 3.6 or newer, it is a standard library just like os and system that is readily available.
It has the benefit of “democratizing” parallel processing and the developers no longer have to understand, or write tens of lines of code for the basic setups that usually comes with multithreading or multiprocessing.
Without further ado, let’s start with an example by simulating how much time could be saved.
Preparation
Here we have a very basic function, it takes some input, do something and return a result.
In this case, to simulate the time saving, we intentionally let the function sleep for i seconds to mimic the behavior of delay due to computing, network, io, etc. Also for analysis purpose, we captured the thread_id, the time the function got started, ended, the input and output (a simple square).
Baseline – Synchronous
Let’s start with a base line where we randomly generate a list of tasks and loop through tasks one by one.
In this test, we generated 5 tasks with different delays, and the total task should take 9 seconds to complete. By executing them sequentially, we captured the output and also displayed in the form of a pandas dataframe. As expected, we have 5 rows that corresponds to the 5 tasks. And all 5 tasks were executed by the same thread (23440) and the total time difference, the delta between when the first task get started and the last one got finished is 9 seconds.
This is very typical for most processing tasks, many tasks that are similar but are fairly independent, maybe each of the tasks is to read in some files and process it, or take a url and collect the HTML and transform it.
In this visualization, we can see that all tasks are handled by one worker and the word is done sequentially or synchronously.
Map
This is a very basic yet powerful script to show how to use concurrent.futures. First, we start by creating an executor that we are currently using ThreadPoolExecutor which you can also use ProcessPoolExecutor if you want. Rule of thumb is to use multithread when it is io blocked but use multiprocessing when it is cpu bound.
Here, we actually specify the worker or the number of thread to be 1 just to get the syntax working first. Here we are calling a method of executor called map which does all the heavy lifting. It actually took the task list and IMMEDIATELY distribute the task to the executor.
As you can tell, the code works, it does exactly what we did above and the execution plan looks virtually the same as the baseline.
Now let’s modify the number of workers to be 2. There is where we start seeing parallel processing working in action. The moment one worker took on the 3 seconds task. A different worker took on a different task of 1 sec. And after that task got finished, it acknowledges and took on another one, so on and so forth.
The total execution time now is only 5 seconds which cut the total execution time in about half (9 seconds). An interesting observation is that theoretically, you can further improve the total execution time by having two separate workers handle the 3 seconds and 2 seconds and it should cut the total time to 4, but that is another problem.
Of course, to see the full power of concurrent.futures, the total execution time can be minimized to 3 seconds when we provide enough workers.
Submit
So what is “submit”? IMHO, one will use submit more often than map in real life so this is probably the function that you should familiarize yourself more. By looking into the source code of map function, it is actually calling submit behind the scene.
It is actually very simple to use, in addition, you can pass on *args and **kwargs which gives you more flexibility to it.
The key difference between map and submit is that calling with map will retain the order when accessing the futures while calling with submit + as_completed will loop through the objects as they were being yielded.
max_workers
Speaking of the number of workers, the obvious answer is the more, the merrier. However, for any given machine, the computing resources are usually limited, the number of CPUs and the number of threads available.
In this case, I have created 500 tasks and requested 500 workers and they seem to work fine.
In the threadpoolexecutor, if you don’t specify max_workers, there will be some default values being applied which you can find more information from the documentation.
For example, in the latest Python 3.8 as indicated in the documentation. os.cpu_count() return 12 from my DELL XPS, so the default max_workers will be min(32, 12 + 4) = 16 workers. Based on some reading, people say there are limited amount of physical threads and the introduction of virtual threads can virtually be as large as you want, however, when it approaches the limitations of physical threads, there won’t be any marginal benefits as you increase the number of threads / max_workers.
Conclusion
In this blog post, we have covered several basic usages of concurrent.futures.ThreadPoolExecutor and you should be ready to save some execution time by leveraging all those beautiful threads. However, there are more to it rather than simply distributing lots of work.
Some key topics that worth pursuing in the future:
how to collect all the results and persist making sure it is thread safe
when should you use multithreading and when should you use multiprocessing? how do you know that
how to configure timeout and handle the error properly
There is this great paper talking about a key measurement named information ratio – which is the excess return for a unit of active tracking error [JPMorgan]. Keep in mind that it is different from the Sharpe ratio as the information ratio is related to the excess return and risk with respect to an existing benchmark, so instead of the absolute volatility, it will be the tracking error.
At a very high level, IC is the information coefficient between -1 and 1 that indicates how good a manager expect to be and turn out to be. The information ratio also grow with the number of independent decisions and the last item, transfer coefficient means the level of constraint.
If you are particular interested in information coefficient on its own, this is an video from Quantopian teaching you how it is being measured from the practical point of view.
Yield curve change is referring to as time passes, how the different yield changes for different maturity. Rather than calculate the difference for each single maturity, industry has always been seeking a way to simplify the and find a simple explanation. And the three key components behind any yield curve change is the famous shift, twist and curvature.
Just like you can use x, and y to explain all the positions on a 2D space, you can use shift twist and curvature to explain all the yield curve changes. These three components are also constructed as uncorrelated factors.
There is this great youtube video that further explained how the three components are being calculated using Principal Component Analysis.
Yield Forecasting and Principal Component Analysis
Once we understand that three components of changes, the next step is usually to prepare the actions in anticipation of changes in each component. For example, if you have three different options of structuring your portfolio as laddered, barbell or bullet.
Then you can use them to list all the possible combinations of three factors, and calculate the potential outcomes.
You can weight the different scenarios differently based on your own forecast of the yield curve and use the probability weighted average as the expectation to pick the best action item.
Exhibit 76, and Exhibit 77 are screenshots from the CFA Curriculum and copyright reserved to them.