Whenever I talk to other people, I say “I love open source software and hate proprietary ones”. However, have you ever read the source code yourself? I rarely read the source code of any tools that I use, but I benefited so much whenever I took a look. Also, these days, our team got stuck with our hadoop environment. Some people complaint it is all screwed up but they cannot correctly identify what is going wrong. Other people say everything is doing fine but they also cannot face the fact that all the Hive queries take way much longer than everyone expected. Based on two things that I mentioned above, I decide to take a look at the source of Hadoop/HDFS …etc. I am more like a Python programmer and my only knowledge of Java is no more than `System.out.println()` and `java -jar` to run the jar file. However, since I have already follow this tutorial to set up the hadoop maven project in Eclipse, I think it will be a good start.
These series of posts are more about some random study notes about how I try to understand the nut and bolt about the hadoop and wish I will figure out what is really going on behind the screen of `hdfs dfs -copyFromLocal source destination`..etc
Today, it is all about the DFSOutputStream.java, the reason that why I started with this class is from the book by Tom White – “The Definitive Guide of Hadoop”. He described the process behind hdfs write. And DFSOutputStream is one of the most important classes involved in this process. To describe the role of DFSOutputStream in a nutshell, the comments at the beginning of the source code is the most authoritative one.

5 MB = 5 * 1024KB = 5120 KB = 80 Packets * 64 (KB/Packet) = 80 Packets * 512 (B/Chunk) * (128 Chunk/Packet).
As we can see from the class definition. DFSOutputStream is a subclass of FSOutputSummer, or DFSOutputSream extends class FSOutputSummer – “This is a generic output stream for generating checksums for data before it is written to the underlying stream“.
Keep going down the code, we can see there are many attributes declared which might be interesting too take a look at first.

- MAX_PACKETS=80, PACKET=64KB -> 5MB, also there is an another attribute “chunksPerPacket”, each packet doesn’t have to be completely filled up to be sent out. At most you can have 128 chunks per packet.
- There are three variables that are super interesting, “dataQueue” and “ackQueue” which are both LinkedList type whose elements are Packet class. Also, another variable “streamer” is the object who will grab available data nodes from the pipeline and distribute the user write data to different data nodes.
- Another few variables who are either user arguments: ‘fieldId, src, ..’ or variables to describe the queuing behavior ‘currentSeqno, lastQueuedSeqno, …’.
After the variables, here comes the definition of the most important class type ‘Packet’. There are two constructors for the class `Packet`, one is used to create a heart beat packet, and the other one is used to create a new packet. ‘pktSize’ is teh maximum size of the packet, including checksum data and actual data, chunksPerPkt is the max number of chunks per packet(128), ‘offsetInBlock’ is the offset in bytes into the HDFS block, our default block size is 128MB.
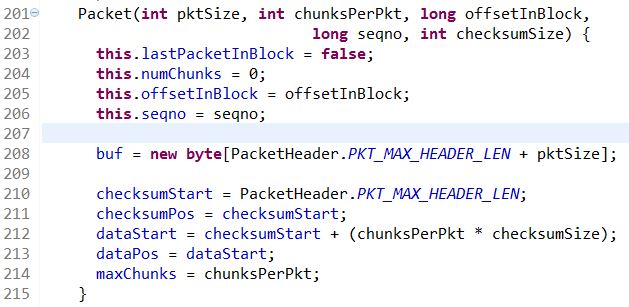
Here, we might need to take out a paper and draw the buffer to help understand how a packet really looks like. First, packet need to declare a buffer whose length is the sum of PKT_MAX_HEADER_LEN and pktSize. The variable PKT_MAX_HEADER_LEN is defined in another class called `hdfs.protocal.datatransfer.PacketHeader`.
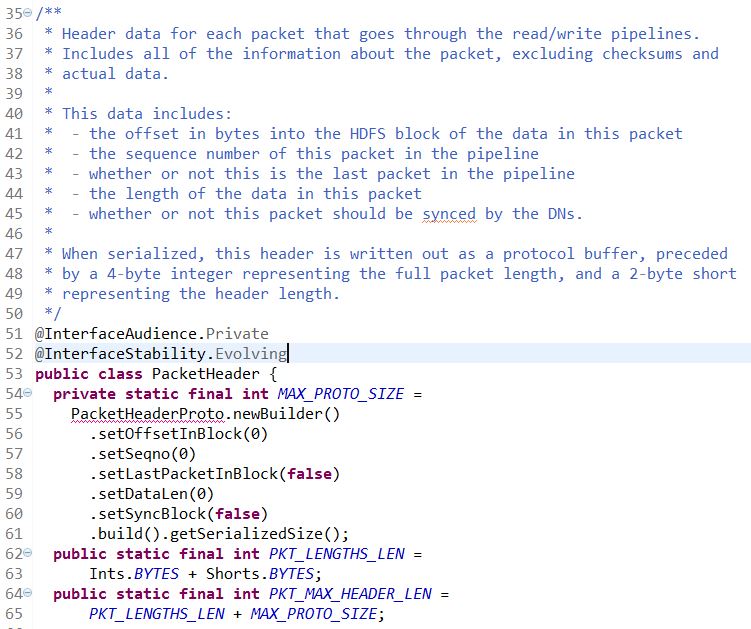
Instead of trying to dive into another class, I will just paste the related code here and keep the scope inside the class `DFSOutputStream`, basically, the order of is 1.header, 2. checksum 3. data….when I was first looking at the graph-ish description of the buf at the beginning of the class. I was thinking the checksum and data was inconsistent, somehow cut off by some data represented by underscore. Well, I guess the reason that they put underscore there is because the checksum and data might not fully populate every bytes and they start from the beginning and might leave the later part empty…
After the Packet has been constructed, there are three methods containing the word ‘write’:
- writeData(byte[] inarray, int off, int len), which will read the input data from the buffer inarray, validate the size of the input, make sure it will not exceed the limit set by the constructor. (dataPos + len <= buf.length). Then use System.arraycopy to copy the input content to the packet buffer.
- writeChecksum(byte[] inarray, int off, int len), it has almost exactly the same code structure as the writeData function.. but this method is used to write Checksum to the packet buffer.
- writeTo(DataOutputStream stm) which “Write the full packet, including the header, to the given output stream.”, in the writeTo function, it first get the absolute length of the data and checksum, then build the pktLen by adding up the data and check, PLUS an extra bytes.. not sure what used for. Then it build the header based on several header information. (1). pktLen, (2). offsetInBlock, (3). seqno, (4). lastPacketInBlock, (5). dataLen, (6). syncBlock which matches the comment in the PacketHeader class. After the header get successfully built, the interesting parts comes. How to arrange the position of these three parts, header, checksum, data before sending. If the checksumPos doesn’t equal to the dataStart, which means that there is a gap between the checksum and actual data in the buffer. Then the code will move the checksum to the right so the checksum and data are right next to each other and will leave more room for the header. After all of this, there are a few “assert” to check everything is fine and send out the contiguous full packet to the output stream.
So till here, we went through the source code of DFSOutputStream-Packet definition which is very inspiring to help understand how the atomic packet looks like which sending the data. And after we are done with it, we will take a close look at what is the “DataStreamer”. From the number of code lines, there are 2000 lines of code in total for DFSOutputStream, and there are about 1000 lines dedicated to define the data streamer, I will say it is a good example of how important this subclass matters.
First, let’s take a look at the DataStreamer constructor:

To build the DataStreamer, you need: (1) last block of the file to be appended (2) status of the file to be appended (3) number of bytes per checksum
The DataStreamer constructor is very interesting, it first read in the information of the previous written block, and do some math calculation of whether there is enough free space in the previous block. Here we take a few parameter just to prove the concept. For example, we assume the blockSize is 128MB, which is the default value for CDH. And assume we are loading a file with size of 2GB, which is 2048 MB. And the variable bytePerChecksum is 512Bytes as default. Lets walk through these few lines and try to do some calculations:
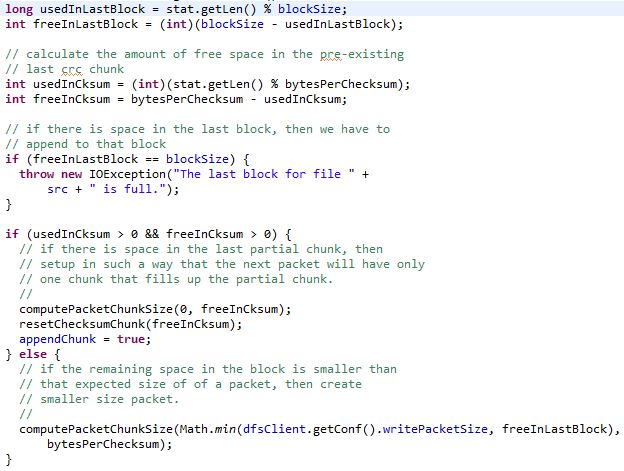
stat.getLen() will be 2000MB, say blockSize is 128MB, then
usedInLastBlock = 2000 % 128 = 80MB, in another way, it is 15 complete blocks plus another block whose complete size is 128MB and only 80MB got populated. Then freeInLastBlock turns out to be (int)(blockSize – usedInLastBlock) =(int)(128-80)=48MB.
say bytesPerChecksum=0.5 MB which is 512Bytes. Then usedInCksum = (int) (2000%0.5)=0, then freeInCksum = 512 – 0 = 512. Then there will be a if statement to check “if there is space in the last partial chunk, then set up in such a way that the next packet will have only one chunk that fills up the partial chunk.”. However, there is a function that we need to take a look before moving on called “computePacketChunkSize”.
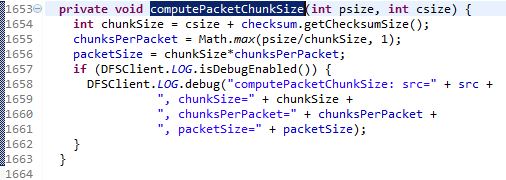
This function will calculate the packetSize based on psize and csize. You can populate these variables with a few random numbers to just have a go with how this function works. But after all of this, it will trigger another function called ‘setPipeline(lastBlock)’…
To Be Honest, I am Running Out of Patience, and Really Think I Cannot Finish All the Codes This Afternoon. But I Won’t Leave This Very First Post Unfinished, I Went Through the Functions and I Think “transfer” is the Most Interesting One to Me. And I will Also Take a Look At the Other Functions Later!
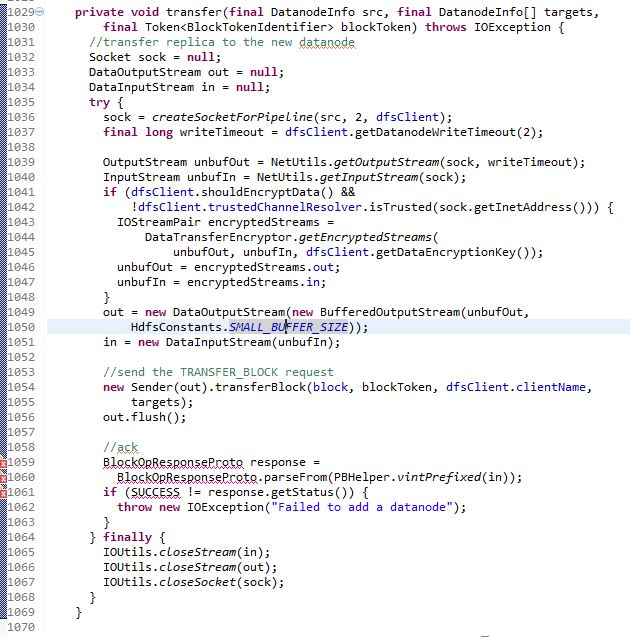
Sender(out).transfer(block, blockToken, dfsClient.clientName, targets);
out.flush();
Done!

Reblogged this on trungduc.
Say many thanks, I am reading hadoop hdfs source code too.
I am by no means a Java programmer, however, I feel the source code really interesting and in a combination with `The definitive guide to Hadoop`. It helped me a lot!
Great post!