A Block is a hadoop FS primitive, identified by a long.
If you go to the data directory of the hadoop datanode, you can usually see a whole bunch of files starting with blk_ followed by a long number, or similar file name but end with .meta. Also some other subdirectories that recursively include all the block files. These files are block files. If you open those files using text editor (VI), you can even see the plain data partially, if some data got compressed, you might see the binary format representation. Anyway, the Block is the unit of the data. Understanding the Block class will be helpful to understand how hadoop distribute data later.
This post will walk through the source code of hadoop.hdfs.protocol.block class.
Very first of all, block class extends the interface Writable and Comparable, which are the two classes that every key, value variable in the map reduce job should extend from. So let’s first take a look at the methods that Block implements from Writable and Comparable.

Here there are basically three pairs of methods to read and write the fields, helper and blockid.

These two methods indicates that a block might contain different content, but to judge if two blocks are the same, blockId is the only variable that matter. BTW, the `?:` statement really simplifies the code and interesting to read.
There are also a few routine java methods like the class accessor(setter/getter), constructor…etc. However, beyond that, there are a few methods which will use regular expression to extract the id/generationstamp from the file name which might worth mentioning here.
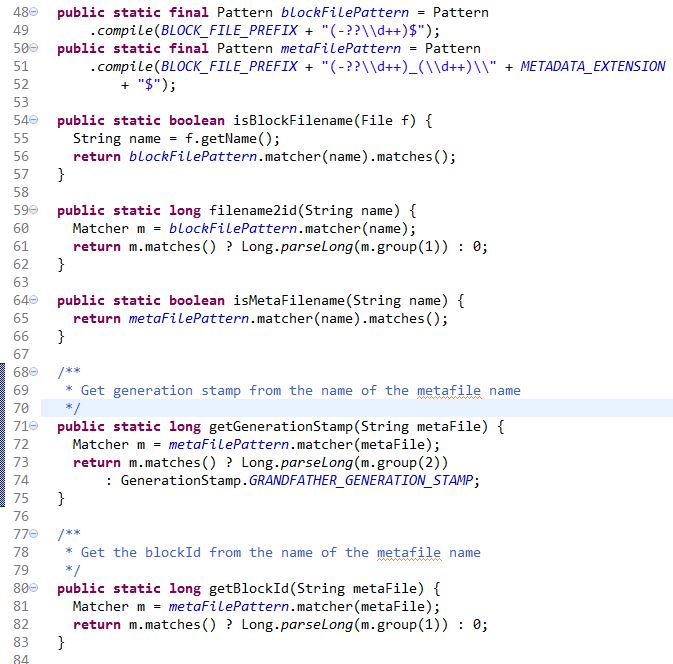
And here is the screen shot of a data node with block file, block meta file, and current working directory highlighted by light yellow marker.

You can write a test class, include the hadoop-core in the to pom file using Maven, and see if those regular expression functions will be able to parse out the blockid, and gentime.
