How to read and write block from/to a datanode.
Lets start from the blocksender – who “Reads a block from the disk and sends it to a recipient.”

There might be two methods out of all that interest people the most, sendBlock and sendPacket. Since sendBlock is actually using sendPacket, I will went through the code of sendPacket first.

All the input arguments are fairly straightforward except for the “transferTo”, which “use transferTo to send data”. So what is “transferTo”? transferTo was added into hadoop by Raghu Angadi in this jira ticket. And he claimed that it might reduce the datanode CPU by 50% or more. Clearly, it is some sort of java function to transfer data in a much more efficient way. Here is a much detail explanation of how transferTo works. It basically moves the data from one fileChannel to another one directly without “copying” it. It is better than writing a for loop and move the data bits by bits from one channel to another.

This paragraph of code above is how the data node actually sends data out, in two different mode. The “normal transfer” is basically using the “hadoop.io.IOUtils.readFully” to read the data using a while loop from the inputstream and write it to the output buffer.
If the flag “transferTo” has been turned on, it will go straight to the “socket” part of code. First write the header and checksum, then write the data part using transferToFully function. On the other hand, if the “transferTo” flag has been turned off, it will do the normal transfer first, send the data first to verify the checksum, then write the header/checksum/data together to the buf. Beyond of the codes here, there are some exception catch and logging code which I won’t explain here.

It is much easier to understand the “sendBlock” class after going through “sendPacket”, because it basically first determine what the size of `pktBufSize` should be. There is an interesting thing here. When the flag transferTo is true, the `pktBufSize` is only the sum of the `PacketHeader.PKT_MAX_HEADER_LEN` and `checksumSize * maxChunksPerPacket`. The first adder is basically a place holder large enough to hold the limited biggest header. However, the second adder is only the number of bytes for all the checksums. Yes, it doesn’t create a packet buffer big enough to hold the data. You might be so confused if have not followed through the `sendPacket`, actually when you are doing `transferTo`, the way how data got transferred is directly move data from one fileChannel to another fileChannel and in this case, you even don’t need to buffer to be used for the temporary buffer to hold the “copying” data. Now we can see it not only improves the CPU performances but also saves tons of space when transferring the data. Of course, if you are not using `transferTo`, it will create a buffer that big enough to hold chunk data and checksum data for so so many chunks per packet.
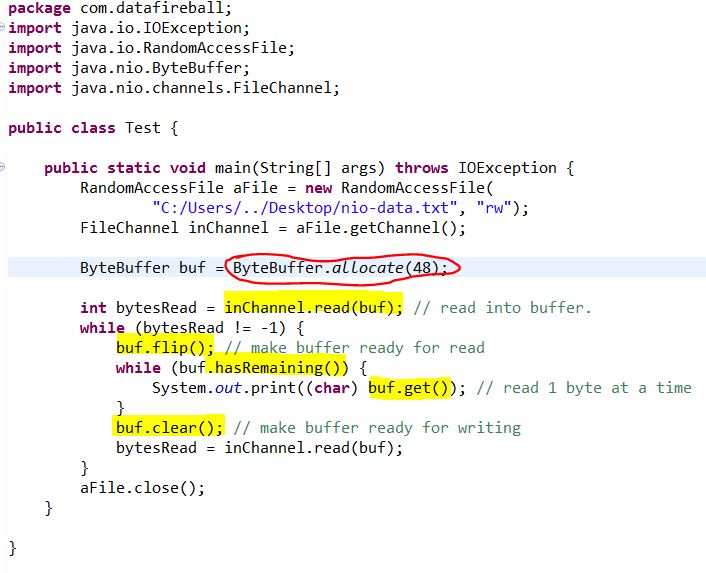
After the buffer got successfully created, the javaNIO will allocate enough space to create pktBuf, and then send the block packet by packet.
In the end:
(1) Why is ‘transferTo’ so fast? Answer: DMA(Direct Memory Access)
(3) How buffer works in Java.