This blog post from Florian is fantastic! I followed his tutorial with a few modifications of the code and got it working!
Here is a screenshot of it working!
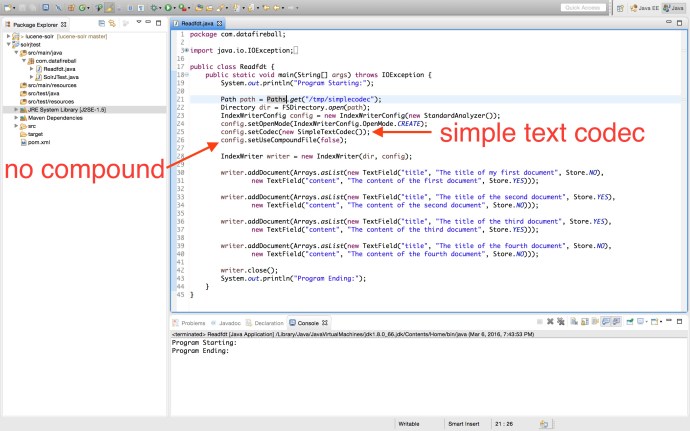
In the code, I configured the index writer to use SimpleTextCodec instead of the default one. So what does SimpleTextCodec do then? In the Java doc, there are only two lines of description which indicates the purpose of this package:
plain text index format.
FOR RECREATIONAL USE ONLY – Javadoc
Clearly, when your index is in plain text format, the access to the index won’t be as efficient as the object serialization and at the same time, the disk usage is not optimized and your index disk usage can easily go through the roof. However, it is really fun to take a look at the raw index file and understand how that works at a high level.
First, when the program finishes, the files in the index folder are different from the ones that the standard Lucene codec or Solr generated.
- _0.fld
- _0.inf
- _0.len
- _0.pst
- _0.si
- segments_1
- write.lock
If you read the Java code carefully, there are four documents got indexed and each document has two text field, since it will be interesting to learn the difference between stored field and indexed field, I tried all the permutations of index and store.
Now lets take a look at _0.fld.
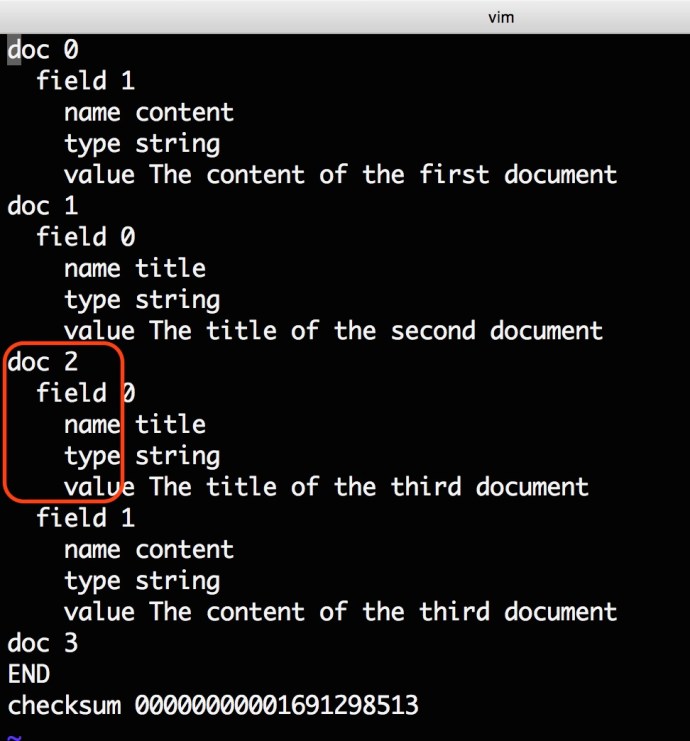
The fld file contains all the stored field information, all the documents are inserted record by record and there is a numeric document id started from 0 and increasing one at a time.
Followed by the doc is the field tag, clearly, for document 1 and document 2, we stored the first field for doc 0 and the second field for doc 1. And for doc2, we have stored both fields and for doc3, neither field has been stored.
Within each field tag, there are three tags which is the name of the field, the field type and field value.
In a nutshell, the fld file bascially transformed all the indexes into a much organized way, however, the whole point of index is the inverted index, so where is the inverted index? There is another file called _0.pst, which contains all the inverted index and the pointer information.
Here is a screenshot of part of the pst:
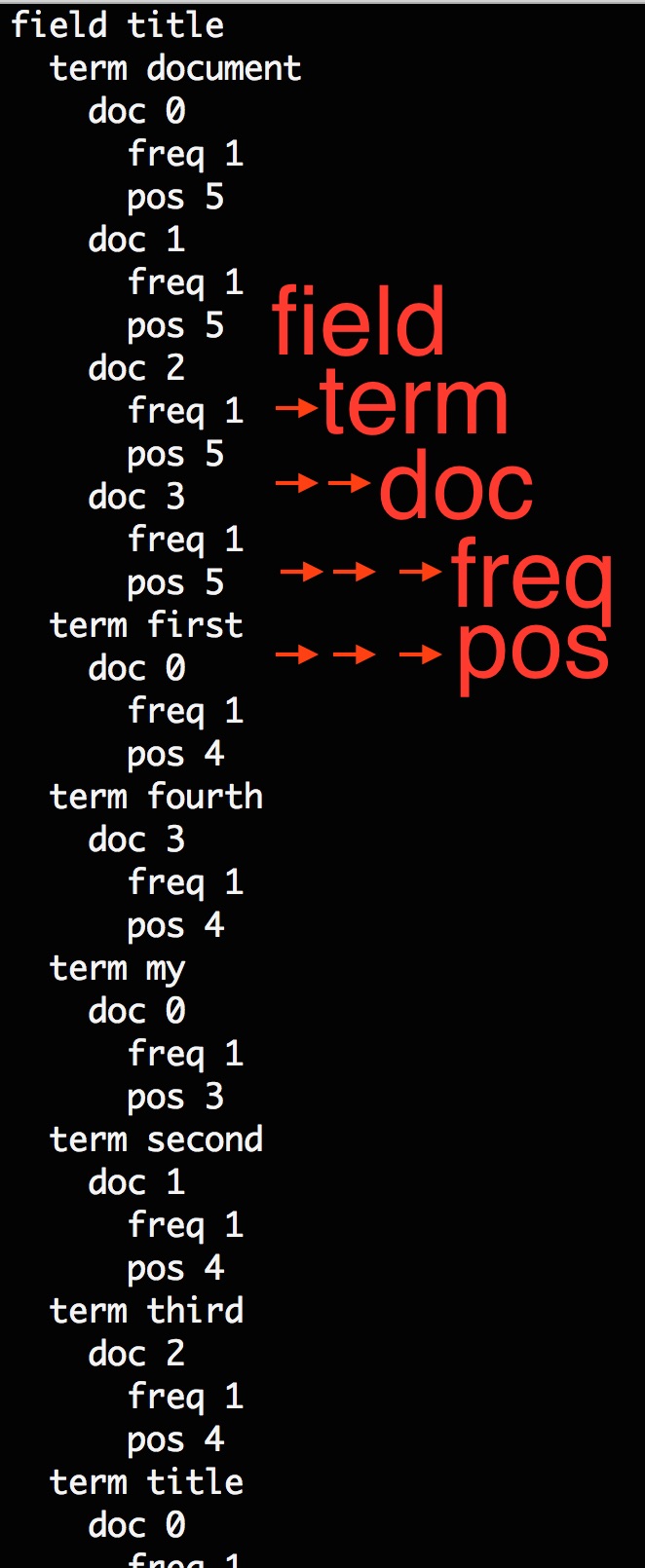
If you are familiar with how the Index and Search works in Solr/Lucene, you should know that all the documented turned out to be inverted index after the text analysis, and when use issues a search, the search term will also first be processed by a compatible text analysis and then turned out to be a search term, which is the field name and the term value itself. As you can see from the screenshot, once you have provided the field and search term, you should easily locate which documents that search term have appeared.
Say for example, the search term is the word “third”, we know it only appeared in doc2 and the frequency is 1 which means it has appeared only once in that document and meanwhile, the position is 4. Now, lets switch back to the fld file and see how it looks like there.

Frequency will be used for calculating the score and the position can easily help you locate the document and the value in fld.
Well, there isn’t really that much to cover and this SimpleTextCodec really illustrate how the indexing part works.
In the end, this is how the segment info file looks like:

