There is a project called Luke has been designed and maintained by several different parties and now the most active version is maintained by Dmitry Kan hosted on Github. The set up is super easy and you must be really amazed at how much this handy tool can bring to you.
First, we need to download Luke by issuing a git clone command:
git clone https://github.com/DmitryKey/luke.git
Then change the directory to the repo and you should realize it is a Maven project since it has a POM.xml file there 🙂 There is a bash script luke.sh which is the script you should use to run Luke, however, if you run the script directly, it will error out saying that unable to find the LUKE_PATH environment variable. If you take a quick look at luke.sh, you will realize it is demanding a jar file with all the dependencies included – luke-with-deps.jar.
You can easily generate that jar file by issuing the following command:
mvn package
This command should take a minute and you will see it started downloading all the dependencies.
Then we are good to go!!!! issue the command `.luke.sh` and you should see a screen like this:

I have to admit aesthetically speaking, this definitely isn’t the most beautiful application on Mac, but know what this tool does, you will forgive it 🙂
First, you need to change the path to point to any index folder with Solr service turned off, I feel like when you tried to open a index folder which a running Solr service is using, it will complain about index locking. Or you can force to unlock and at the same time set readonly mode so you can read the index.
Anyway, for a brand new Solr installation, you can issue the command “./bin/solr start -e techproducts” which will not only start a Solr instance but index a few records. We will use the generated index file as an example to illustrate how Luke works.
Like what I have done to most applications, I went to preference and changed the theme of the application from yellow to grey so it looks a bit modern…. Before I dive into too much detail, you can first go the Tools option and export the whole index into an XML file. In that case, you can open the XML format of your index and see what is fun there.
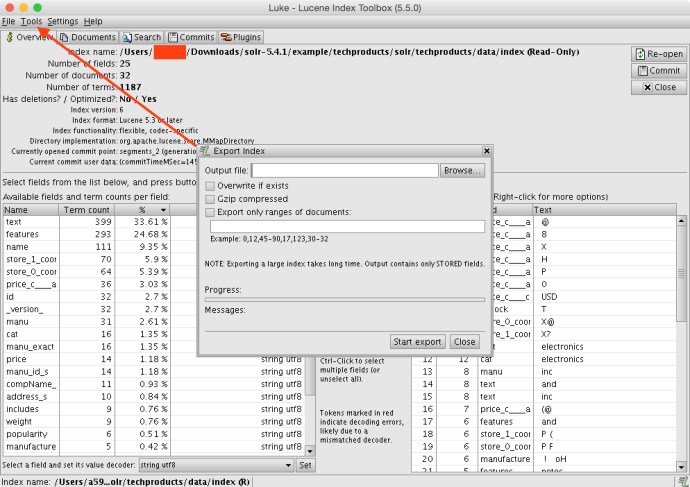
There is a tab in Luke called search where you can simulate how the search part really works but with lots of customization capability like text analysis, query parser, similarity and collector. I post the screenshot of Luke search here along with one from Solr web app search. So you can easily see they have exactly the same search result but Luke absolutely gives you more flexibility if you want to understand what is going behind the scene.


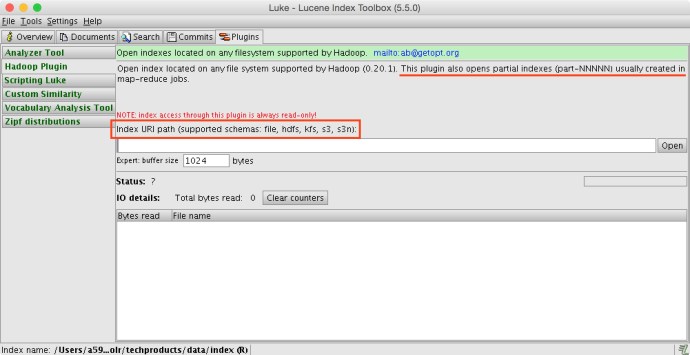
There is also a really cool feature in Luke Plugins called Hadoop Plugin, it is capable of reading partial index file generated by Map Reduce, something like part-m-00x. Here is a screenshot:
In the end, I highly recommend using Luke when you work with Solr and Lucene.
Good luck search!
References:
