This is a post where I brought up a 3 node solrcloud on my laptop with default settings, and then benchmarked how it takes to index 1 million records using SolrJ.
You can view the SolrJ benchmark code on my github and I also wrote a small r program to visualize the relation between index time and batchsize. You can view the source code here.

In this case, there are three nodes running in the Solrcloud and three shards with one replica each. So we have 3 * 2 = 6 cores in the end and two cores each node.
This is how the solrcloud graph looks like for the gettingstarted collection. And you can also see when I log into localhost:8983, which is node one, I can only see two cores which is shard2 and shard3 there.


In the end, we got a sense of how fast this API could be using one thread and it is around 12 dps (Documents Per Second). However, the question is can this be improved?
There is a presentation on Slideshare from Timothy Potter that I found really inspiring and helpful.
He claims that the performance could be improved by optimizing the number of shards and at the same time, replica is expensive to write to, and in this case, I don’t want replication.
Then I reran the solr cloud gettingstarted example and set the number of shards to be 4, (it has to be in a range between 1 and 4) and replication factor to be 1 which means no replication.
I reran my code and put together the benchmark data together.
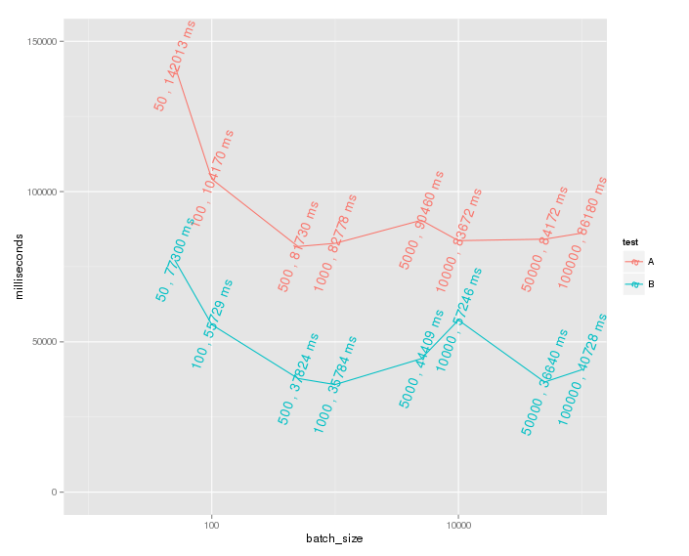
Clearly, we can see the performance dramatically increase and the now the record is 30K dps. I think the next step will be researching what is the optimized number of shards to use.
