In Hive, there is an idea called schema on data, you can first use whatever tool you want to generate a file following certain format (CSV, ASV, TSV, Avro), then you can create an external table pointing to the data sources. Some people even call it schemaless because you really don’t have to create a table before having data. The data even doesn’t have to be retransformed and after you create the table, the data can stay exactly where it is. Imagine you have a huge dataset, write a dataloader to transform and feed into the database will double the disk space in nature and Hive you don’t have to. This really makes Hive powerful and scalable.
Thinking about Solr, it is a database in essence just somehow has a different file format – inverted Index (Lucene Index). Based on my knowledge, here is a short list of approaches to load data into Solr.
In the end, all the approaches are somehow going through the Solr update API and writing to Solr Index. So there is always a layer in the middle which might become a bottleneck when the need is bigger than the API threshold. In this case, people might start asking, what if I already have a huge data in Lucene format, is it possible to load? If so, what if I can transform my data into Lucene much faster using parallel processing (Spark, Mapreduce), does that mean I can overcome the bottleneck of indexing API? The short answer is yes and this post is a proof of concept of how to write your own lucene index and load into Solr.
Here is a screenshot of the Java app I wrote to index 10 million dummy documents into a Lucene index, you can find the source code here.
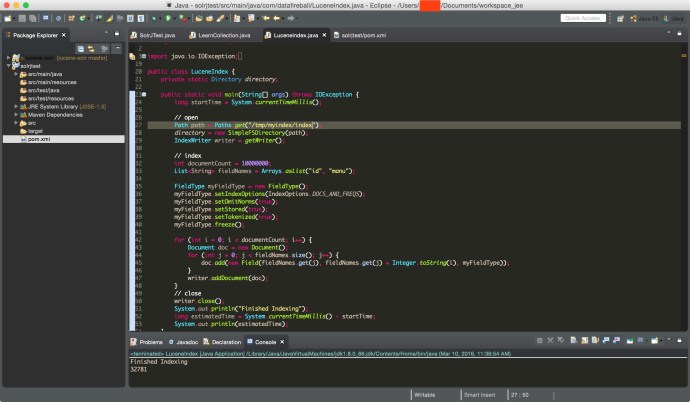
Here is another screenshot showing how the index finally looks like in the end on my local file system.
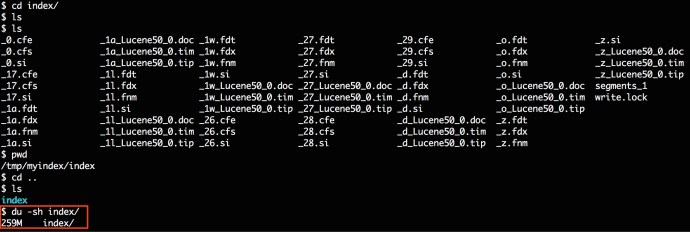
At a high level, it took 30 seconds to write 10 million records into a local Lucene Index and the Index folder is 260MB.
Now lets take a look at how easy it is to load the data into an existing Solr core.
The loading part can be summarized into 3 steps:
- making sure you have a Lucene index 🙂
- modify schema.xml (managed-schema) to include existing field in your Lucene index
- modify solrconfig.xml to point <datadir> to where Lucene index is sitting
- restart solr
Step1: Lucene Index
I have just shared how to write a Lucene index, if you already have one, you can use Luke to inspect the Index, understanding if it is a legit index and what are the fields and corresponding types.
In my example, there are only two fields which is id and manu and both of them are string types. This is how my index looks like in Luke.
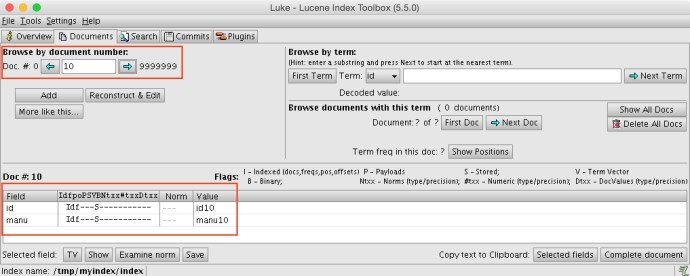
Step2: Schema.xml.
To make sure we don’t skip any step, I am just download a fresh Solr and start a brand new core using the data_driven_config.
Here is a screenshot of how I did it.
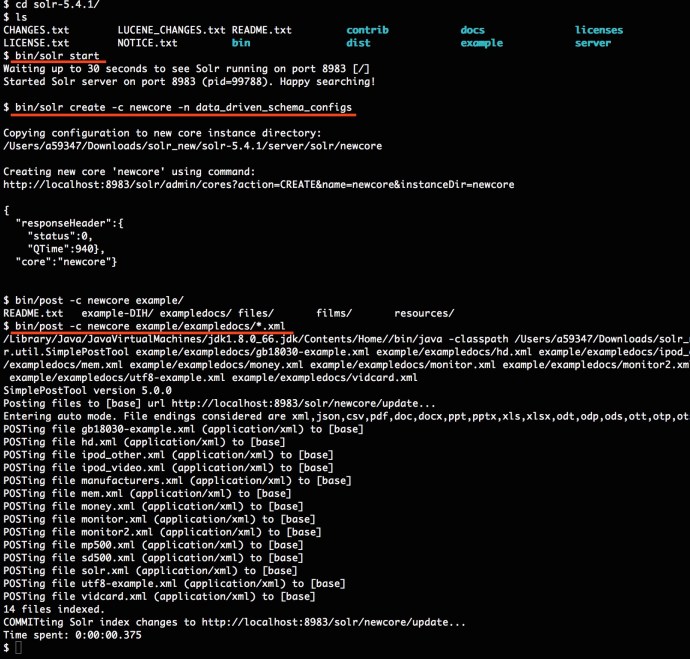
And now we have a bunch of random documents in our newcore and the schema should have recognized all the fields.
Here are the existing documents.
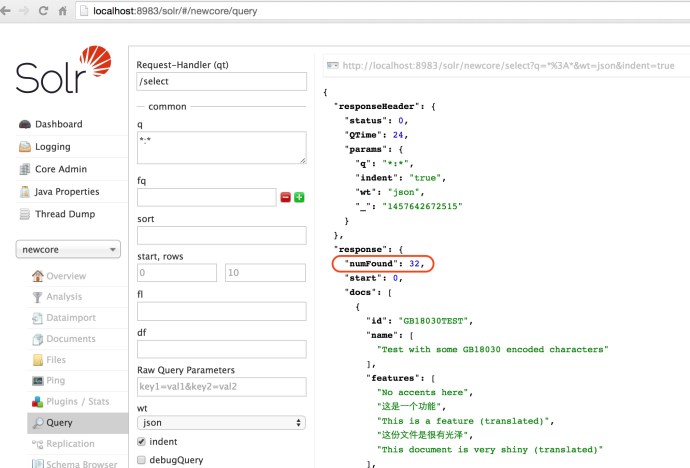
The post tool managed to index 32 documents. And in this case, I am using the configuration set named “data_driven_schema_configs”. As you can tell from the name, this schema configuration is data driven which is smart enough to add new fields into schema.xml based on whatever data got posted to it.
Here is a screenshot of how the default managed-schema looks like and how it looks like after posting documents.


The funny part is you won’t even see a schema.xml, but the file “managed-schema” is supposed to play the role of defining the schema, you can find more information about nitty gritty details about managed-schema from here.
Here are a few screenshots of the interesting managed-schema even didn’t show up in the files tab in Solr web app but it is there in the file system.


After all of this, we realized that the example documents actually contains the fields id and manu but it is not stored nor indexed. However, in our Lucene index that we are going to load, we made those two fields both indexed and stored. It will be interesting to see what if the schema doesn’t match the index but for now, lets move on by modifying the manu field to be stored and indexed.
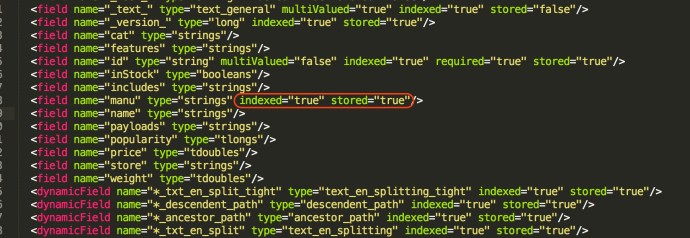
Step3: Solrconfig.xml
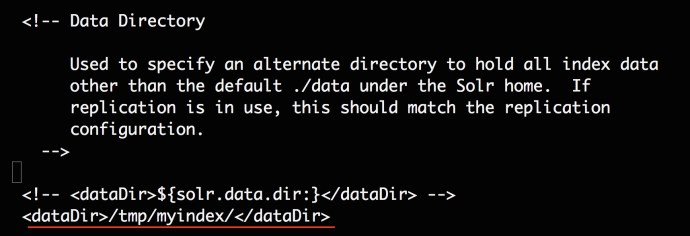
Now we have corrected the schema and then need to change Solrconfig making sure the core is pointing to where our Lucene index is.
You need to locate a tag called dataDir and change the value, for more information about dataDir, you can visit this wiki page.
Step4: Restart Solr
Now we are done modifying both configuration files, however, how to take effect? people were saying you can use the ADMIN RELOAD API. However, it has also been mentioned in the Wiki that:
Starting with Solr4.0, the RELOAD command is implemented in a way that results a “live” reloads of the SolrCore, reusing the existing various objects such as the SolrIndexWriter. As a result, some configuration options can not be changed and made active with a simple RELOAD…
IndexWriter related settings in <indexConfig>
<dataDir> location
Bingo, there is exactly the configuration that we changed, so we have to restart the Solr instance to take effect.
bin/solr stop && bin/solr start
Now lets take a look if our 10 million indexes got loaded or not.
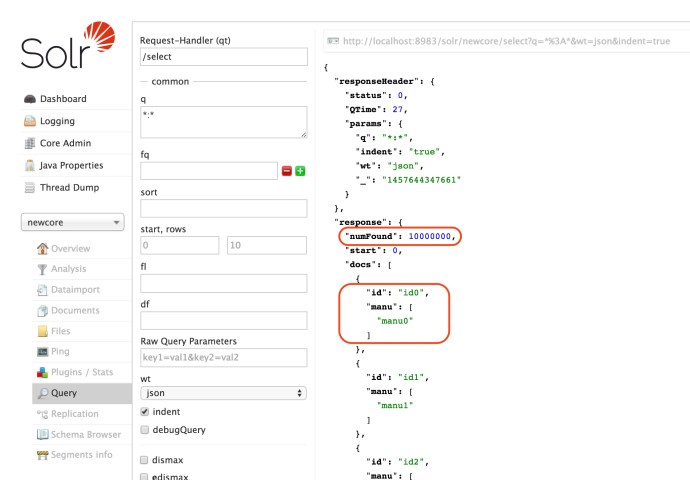
Mission Accomplished!
TODO:
- benchmark against other indexing approaches SolrJ, CSV…
- load lucene index into Solrcloud
References:

Interesting and useful, but “here” is the code does not lead anywhere. Do you mind providing the code? – Thank you