In the previous post, we managed to load Lucene index straight into a standalone Solr instance, now lets try to do the same thing for a Solrcloud.
First, we generated four Lucene indexes using code similar like this, however, to make sure we don’t screw up, I modified the code a little bit to make sure the id field is unique.
Now we have four indexes sitting on my local system that wait to be loaded.
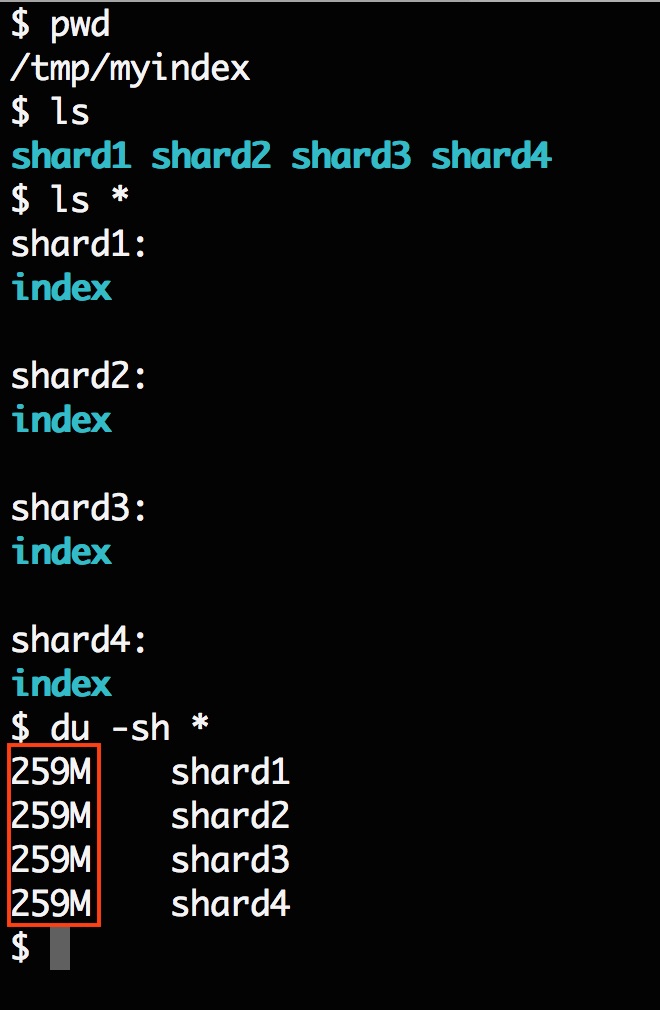
Then I started a Solrcloud with 4 shards, 1 replica (or no replication) running on my laptop using the techproducts configuration set where the field id and manu already exist.
Here is the API call behind the scene to set up the cluster.
http://localhost:8983/solr/admin/collections? action=CREATE& name=gettingstarted& numShards=4& replicationFactor=1& maxShardsPerNode=1& collection.configName=gettingstarted
Here is a screenshot of four nodes running in our gettingstarted collection.
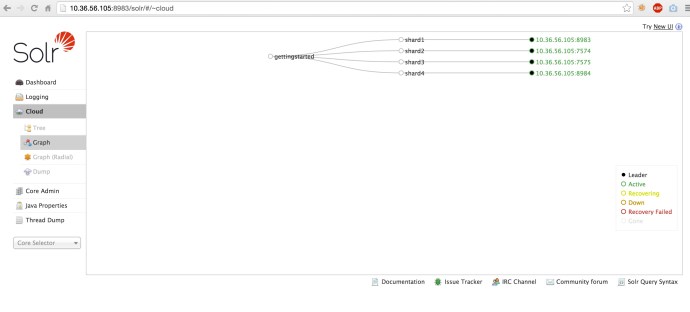
Now the next step is to simply replace the index folders of each Solr shard by the index folders that we generated. In the previous post, we went to the solrconfig.xml and modified the dataDir to point to a Lucene index folder, and it seems like you don’t have to move the data at all. However, when I look in each shard, there is not even a solrconfig.xml.
 So we can tell the there is only one configuration set for this collection regardless of how many nodes we have and it is stored in the zookeeper folder for this collection. I will have another post diving into zookeeper but now, lets do it in an easy way, let the collection using the same dataDir as it did and replace the index with our generated index.
So we can tell the there is only one configuration set for this collection regardless of how many nodes we have and it is stored in the zookeeper folder for this collection. I will have another post diving into zookeeper but now, lets do it in an easy way, let the collection using the same dataDir as it did and replace the index with our generated index.
rm -rf example/cloud//node1/solr/gettingstarted_shard1_replica1/data/index cp -r /tmp/myindex/shard1/index/ example/cloud//node1/solr/gettingstarted_shard1_replica1/data/index
Here is the command to delete the index and repopulate using my index. And just do the same for the rest of the nodes.
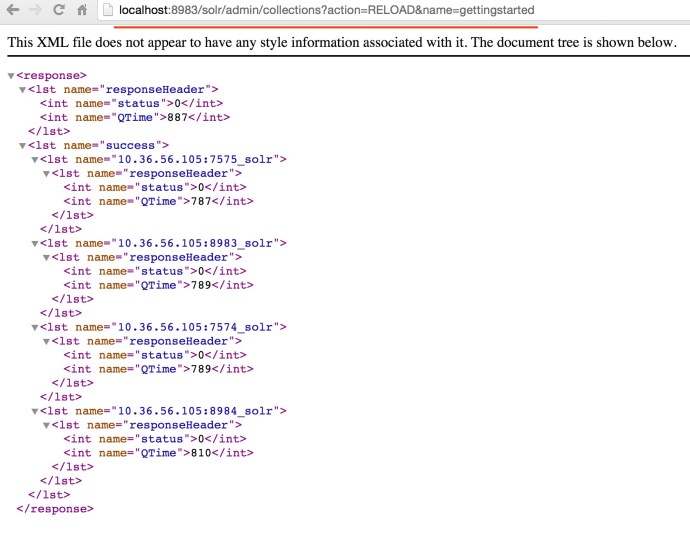
In the end, the easiest way is to run the reload command to make sure Solr is running against the latest indexes.
You can either go to each node in the Solr web GUI and click the button one by one.

Or you can issue a http request to the Solr collection admin API.
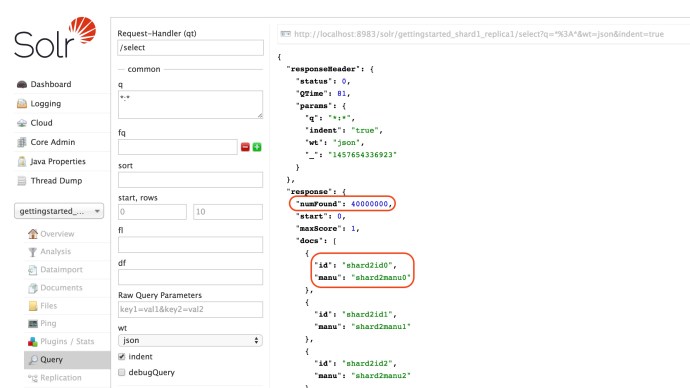
And now, we can see all our documents 4 * 10 million ~ 40 million records is searchable.
Fast Search! Happy Search!

How setup multiple solr clouds with zookeeper in diffrent windows servers. I am using solr 5.4.1 and zookeeper 3.4.6
Ha Manohar, I am not an expert working with Windows servers, you might want to consult the Solr user mailing list.