In the previous post, we managed to start up a Solrcloud cluster and indexed a few thousand documents, we know they got distributed, we know they got splited, but how the indexes look like in each node. This post might not be helpful for those who are seeking for actions items, but for the ones who is really curious into how Lucene works, this should be helpful.
Solr in a nutshell is a transformation of data into an inverted-index format. Inverted-index is basically the book index page where it is search term oriented and suited for quick look up. Now let’s look into the index folder of each shard. To find the directory path of index, you can get on Solr web app and you should see the absolute path in the shard overview session.

Looking into the index folder, there are a few files with file type extensions that are not commonly used or seen. You can take a quick look of the file extension definition here. But clearly, the _k.fdt is the first file and happened to be the biggest file in this directory which I assume it should store some valuable information there.
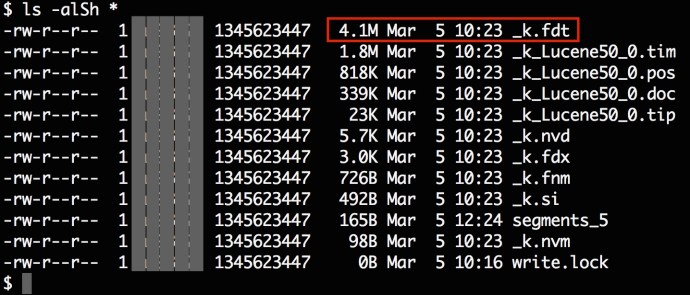
When you open the file in VI.
After a few hours of research, to understand the Solr index file is actually starting to get out of the domain of Solr, and it is getting to the core of Lucene.
I have asked a stackoverflow question here and people pointed me to the package description of lucene.codec. I will temporarily mark this post as the first step towards to the success. And need one or even more posts to cover this topic.
