You can view the source code of tokenizer.c from Github. I highly suggest you download that file to your computer and view it in a legit C development IDE in order to easily navigate through and potentially fold or unfold some big blob of code for easier readability. I am not going to compile/debug/run the code in this post. So tools like sublime will suffice. (Also, I am not a C programmer by any means and only took 2 courses back in college, so do not feel intimated at all because we are probably on the same boat).
The code starts with disclaims that is always a good practice to articulate the license and responsibility for using the code. After that, it state the high level purpose of the code:
*************************************************************************
** An tokenizer for SQL
**
** This file contains C code that splits an SQL input string up into
** individual tokens and sends those tokens one-by-one over to the
** parser for analysis.
*/
So now we must expect the code will take a string as input, and split into tokens, and call some parsing function to analyze them one by one.
/* Character classes for tokenizing
**
** In the sqlite3GetToken() function, a switch() on aiClass[c] is implemented
** using a lookup table, whereas a switch() directly on c uses a binary search.
** The lookup table is much faster. To maximize speed, and to ensure that
** a lookup table is used, all of the classes need to be small integers and
** all of them need to be used within the switch.
*/
#define CC_X 0 /* The letter ‘x’, or start of BLOB literal */
#define CC_KYWD 1 /* Alphabetics or ‘_’. Usable in a keyword */
…
#define CC_ILLEGAL 27 /* Illegal character */
Then this blob of code defined several constants, which wherever the identifier like “CC_X”, “CC_ILLEGAL”, or actually any constants defined here starting with prefix “CC_”, will all be substituted by the token-string which is the small integer 0 to 27. This will increase the readability in the code and guarantee the optimized performance when it is actually executed. To learn more about why using small integers is faster, check out this article written by Zuoliu Ding.
static const unsigned char aiClass[] = {
#ifdef SQLITE_ASCII
/* x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 xa xb xc xd xe xf */
/* 0x */ 27, 27, 27, 27, 27, 27, 27, 27, 27, 7, 7, 27, 7, 7, 27, 27,
/* 1x */ 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
/* 2x */ 7, 15, 8, 5, 4, 22, 24, 8, 17, 18, 21, 20, 23, 11, 26, 16,
/* 3x */ 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 5, 19, 12, 14, 13, 6,
/* 4x */ 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
/* 5x */ 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 9, 27, 27, 27, 1,
/* 6x */ 8, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
/* 7x */ 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 27, 10, 27, 25, 27,
/* 8x */ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
/* 9x */ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
/* Ax */ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
/* Bx */ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
/* Cx */ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
/* Dx */ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
/* Ex */ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
/* Fx */ 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2
#endif
When I first saw this paragraph of code, I just found it to be so well formatted that anyone who has the minimum amount of patience and understand it perfectly. It is a lookup table which can quickly map the first FF (16 * 16 = 256) characters to its corresponding character class. Then there is this discussion of ASCII EBCDIC which we will omit because the code has a condition group “#ifdef” which will be initialized only based on the underlying coding format.
Then there is a basic normalization which is to convert upper case to lower case which is a bit more complex in EBCDIC. This also explains why sqlite is not case sensitive for certain tokens like keywords, you can use “SELECT”, “select” or even “Select” which makes no difference.
/*
** The sqlite3KeywordCode function looks up an identifier to determine if
** it is a keyword. If it is a keyword, the token code of that keyword is
** returned. If the input is not a keyword, TK_ID is returned.
**
** The implementation of this routine was generated by a program,
** mkkeywordhash.c, located in the tool subdirectory of the distribution.
** The output of the mkkeywordhash.c program is written into a file
** named keywordhash.h and then included into this source file by
** the #include below.
*/
#include “keywordhash.h”
Here is a link to the genrated keywordhash.h.
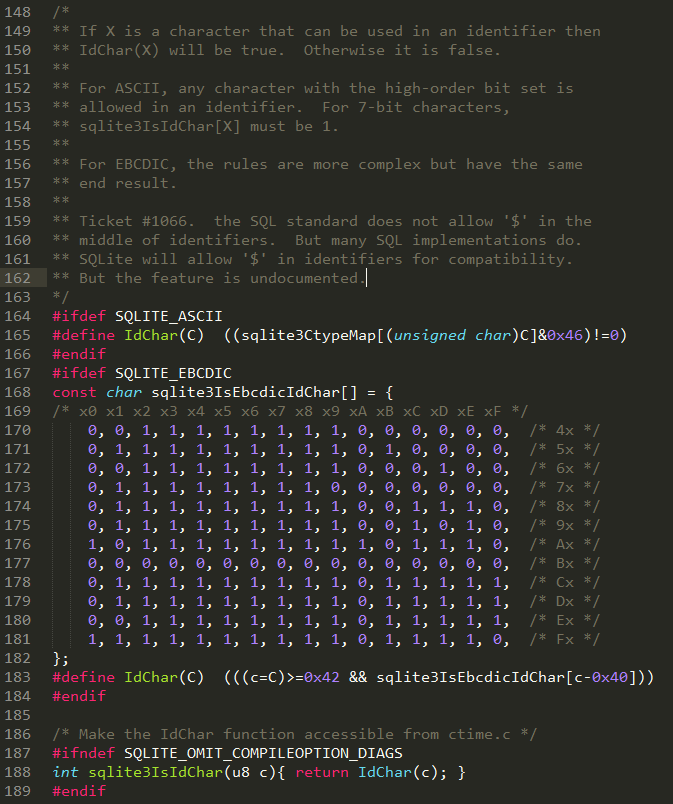
Again, depending on the platform, if we are using ASCII encoding format. This paragraph of code is the same as below, much shorter right?
#define IdChar(C) ((sqlite3CtypeMap[(unsigned char)C]&0x46)!=0)
#ifndef SQLITE_OMIT_COMPILEOPTION_DIAGS
int sqlite3IsIdChar(u8 c){ return IdChar(c); }
#endif
That is plenty of preparation work that we just went through. Now let’s take a look at this exciting function “sqlite3GetToken” that will
/*
** Return the length (in bytes) of the token that begins at z[0].
** Store the token type in *tokenType before returning.
*/
for example, if z is a string “select * from table1”, then z[0] is of course “s”, and this sqlite3GetToken will return two things:
- length of the token: 6 is clearly the length of the first token “select”
- token type is clearly a keyword which is CC_KYWD
Then you can imagine it will start looping this type of execution from the left to the right.
/* line 177 */int sqlite3GetToken(const unsigned char *z, int *tokenType){
int i, c;
switch( aiClass[*z] ){ /* Switch on the character-class of the first byte
** of the token. See the comment on the CC_ defines
** above. */
case CC_SPACE: {
testcase( z[0]==’ ‘ );
testcase( z[0]==’\t’ );
testcase( z[0]==’\n’ );
testcase( z[0]==’\f’ );
testcase( z[0]==’\r’ );
for(i=1; sqlite3Isspace(z[i]); i++){}
*tokenType = TK_SPACE;
return i;
}
case CC_MINUS: {
…
case CC_KYWD: {
for(i=1; aiClass[z[i]]<=CC_KYWD; i++){}
if( IdChar(z[i]) ){
/* This token started out using characters that can appear in keywords,
** but z[i] is a character not allowed within keywords, so this must
** be an identifier instead */
i++;
break;
}
*tokenType = TK_ID;
return keywordCode((char*)z, i, tokenType);
}
case CC_X: {
#ifndef SQLITE_OMIT_BLOB_LITERAL
testcase( z[0]==’x’ ); testcase( z[0]==’X’ );
if( z[1]==’\” ){
*tokenType = TK_BLOB;
for(i=2; sqlite3Isxdigit(z[i]); i++){}
if( z[i]!=’\” || i%2 ){
*tokenType = TK_ILLEGAL;
while( z[i] && z[i]!=’\” ){ i++; }
}
if( z[i] ) i++;
return i;
}
#endif
/* If it is not a BLOB literal, then it must be an ID, since no
** SQL keywords start with the letter ‘x’. Fall through */
}
case CC_ID: {
i = 1;
break;
}
default: {
*tokenType = TK_ILLEGAL;
return 1;
}
}
while( IdChar(z[i]) ){ i++; }
*tokenType = TK_ID;
return i;
/*line 448*/ }
If you look at the source code of this function, it accounts for (448-177) / 598 ~ 45% which is almost half of the tokenizer.c. And looking at the structure of the code, it is nothing other than a giant switch case statement. As you can see from the code, “i” is a very important variable that stores the length of the current token and return it when it matches.
For example, looking at the first case,
case CC_SPACE: {
testcase( z[0]==’ ‘ );
testcase( z[0]==’\t’ );
testcase( z[0]==’\n’ );
testcase( z[0]==’\f’ );
testcase( z[0]==’\r’ );
for(i=1; sqlite3Isspace(z[i]); i++){}
*tokenType = TK_SPACE;
return i;
}
So first, it checks if the “first” character is whitespace or not, then it goes through a for loop where the number of loops is returned by “sqlite3Ispace(z[i])”. So if there are 4 space contiguously and i was initialized to be 1, then sqlite3Ispace(z[1]) will check if the second element is space or not, which holds true, then i got incremented to be 2, and it goes to the second loop, and this will keep iterating till i = 4, which z[4] is actually the fourth element which is not a space any more. then the for loop statement will not hold true and break which left i to be 4. The tokenType will be returned to be TK_SPACE and the length of the token will be 4.
As you can see in the source code, many of the case statements were implemented in a looping format of either for loop or while loop meant to iterate through all the characters and complete this token.
Now we understand how this function sqlite3GetToken works, the last function which is sqlite3RunParser fits together with sqlite3GetToken.
There are several group conditions defined in the rest of the code. I took a screenshot of a while loop which I personally think best describes the functionality of how a tokenizer operates.

First, a few variables were defined a few lines above this screenshot where zSql is a pointer to the input SQL statement, for example, zSql[0] is the very first character “s” if the input statement is “select * from table1”. Then sqlite3GetToken function will take the input of the sql statatement and return the length of the token, and meanwhile updates the pointer of tokenType to refer to the right tokenType for the token. Hopefully this is not too confusing after the explanation of the study of sqlite3GetToken first. Next, there is a variable mxSqlLen has we first need to understand how it is initialized. It was defined as a int first and then initialized to be the value of “db->aLimit[SQLITE_LIMIT_SQL_LENGTH]”. db is the connection to the sqlite database and let’s take a look at the rest. Here is a link which listed a few SQLite run time limits which SQLITE_LIMIT_SQL_LENGTH is actually an identifier whose value is 1. At the same time, aLimit is a structure which stores all the limits and the value of index 1 which is the second element in the structure stores the maximum sql statement length. In the end, we know that mxSqlLen was initialized to be the possible maximum sql statement length. For every loop, sqlite3GetToken will retrieve the next token length, and this variable will subtract the length of that token. The following if statement also showed that as we tokenize the SQLstatement, if the length is too long, it will exceed the limit and error out and break. This is a good break condition check but probably the code is rarely executed for most of the scenarios. The else statement describes the scenario when it is reaching to the end of the statement. In the end of the else statement is to subtract n from zSql, so the pointer zSql now should point to the next token of the input sql statement.
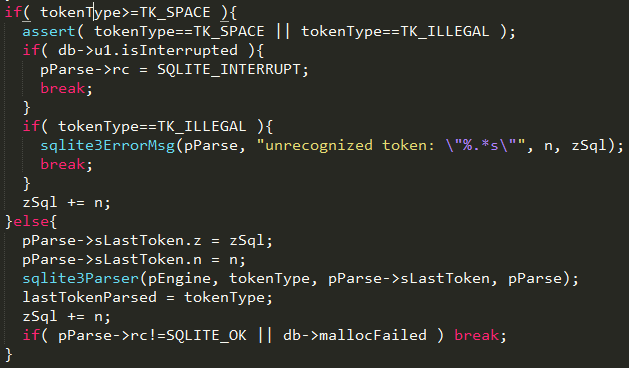
This 20 lines of code is probably the most important part. Here is the decision tree where it determines if we need to pass the token to be parsed or not. In the if statement, it listed the scenario that if the token type if interrupt or illegal, then exit by either interrupt or error out, otherwise, it is a space, it will just update the zSql pointer to point to the next token by skipping the space token. In the else statement, it means it a valid a token that need to be passed to the parser. It will hand over the pointer and length of the next token to the parser.
The rest of tokenizer.c are mostly group condition which are suggested to read if you want to explore all conditions when specific flags are set up, etc.
In this tokenizer.c, we have covered two functions very extensively, sqlite3GetToken and sqlite3RunParser, hopefully it gave you a rough idea of how a tokenizer is implemented and how it is hooked up with the next step in the workflow – Parsing.
In the next post, we will look into how the parser are generated by lemon and potentially a lot of information around how parser works in general.
