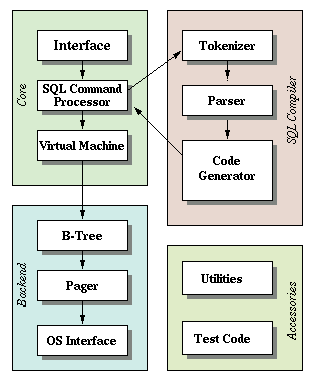
A simple Google search led me to Wikipedia who defined Tokenization as the process of “breaking a stream of text up into words, phrases, symbols and other meaning elements called tokens”. The next step is of course, to pass the list of tokens as the inputs for further processing like parsing as indicated in the architecture of SQLite.
The SQLite tokenizer is implemented in the src/tokenizer.c file of its source code, for easy access, we will use its Github repo as the future master place when we discuss code. That file was written in 2001 ( 16 years ago!) and has only a few hundred lines of C code including comments. But before, we even start going through the code, we want to have a better understanding of the purpose for this SQLite tokenizer. “what should my code do?”
As we have articulated above, this tokenizer.c should taken in a stream of characters, and then do something to break them into tokens, and categorize them into different types of tokens “words”, “phrases”, .etc. So there are a few key questions that we have to agree on or define before we move on.
What is the definition of a “token” within the realm of SQLite, that might include several sub questions like what should be included in a token, and what should not be included in a token, and what is allowed as being the “separator”, .etc. Then the second big topic will be what are the key categories of tokens, variable? SQL keywords? separators? I found this great “draft” that we can follow in order to better answer those questions.
Character Classes
In this draft documentation, it first lay down the foundation of defining all the characters (actually unicode) into 6 fundamental classes, whitespace, alphabetic, numeric, alphanumeric, hexadecimal, special.
There are two classes that I want to highlight and discuss more.
First is the definition of whitespace, based on the definition from a unicode lookup website.
- u0009 character tabulation
- u000a line feed (LF)
- u000c form feed (FF)
- u000d carriage return (CR)
- u0020 space
I think if you were born after the typewriter era, please check out this stackoverflow question and this wikipedia page to better understand what is the difference forms of switching to a new line. Also, a picture borrowed from Stackexchange can probably explained in a much better way.

Second is the interesting definition of alphanumeric, or actually alphabetic essentially, it is not only A-Za-z but also include “_” and any other character larger than u007f, so it includes all the “weird” characters including emojis like white smiling face and foreign languages .etc. Since the definition of alphabetic is so wide hence the definition of special has actually been narrowed down to only the limited number of “weird” characters at the beginning of the unicode world.
Token Categorization
After understanding how character classes are defined, the draft listed all the requirements related to token. There they categorized tokens into several categories:
- Whitespace tokens
- Identifier tokens
- Literals : string, integer literals .etc.
- Variables : Variables are used as placeholders in SQL statements for constant values that are to be bound at start-time
- Operator tokens: “-“, “=”, “(“, etc.
- Keyword tokens: “AFTER”, “SELECT”, “JOIN”, etc.
The tokenizer requirements are extremely helpful to read through just to get a sense of how the code is “supposed” to behave like in a plain English way. For example, we will go through one or two tokenizer requirements listed in the draft as an exercise:
The first requirement there is described as below:
Processing is left-to-right. This seems obvious, but it needs to be explicitly stated.
H41010: SQLite shall divide input SQL text into tokens working from left to right.
In the draft, all the requirements come in this format where a description comes first and then there is a more concise form in the tone of”shall” starting with an identified in the format of “Hddddd”. It is good that the formats are consistent but actually this format is not the “ideal state”. There is an official SQLite requirements page which documented ALL the requirements in one place. You are more than welcome to read through only the first section “About SQLite Requirements” just to get a sense of why the tokenizer requirements document is only a draft 🙂
OK, that is quite a high level overview of the tokenizing process along with some of the requirements. However, before jump into reading the source code, it will be great if there is a way where we can play with the “SQLite Tokenizer” directly in order to have a hands-on and intuitive understanding of what a tokenizer does by “writing code”! Sadly, a quick Google search did not provide any fast way of really hooking up the SQLite tokenizer directly to a tool that end user can easily use, there are tools out there like Python sqlite3 which can interact with SQLite pretty fast from the application perspective, but not as deep as the level we want.
So maybe we can go through the source code of tokenizer.c and see if there is a good place where we can inject some print statement to print out the output of the tokenizer before it feed into the parser. Since the source code is a few hundred of lines and we might even want to discuss and delve into the details. We will write up another post and go through the source code.
Please click this link to visit that post.

{kind=link}