Deep learning has been widely adopted to recognize images. A necessary step prior to use other people’s model or build your own is to massage your data in a way that is machine learning friendly. Udacity is offering a deep learning class with Google where they published a Jupyter notebook which covered the whole process in tens of lines of code. There is a snippet of the code in lesson 2 – Fully Connected which I want to highlight, and hopefully this method will come handy when you work with data.
They have a function called “reformat” which is very interesting. First of all, the train_data variable is a nested array of size (N, M, M) where N is the number of records, think it as the number of images that you want feed. We are also assuming we are feeding normalized images in a unified square format of the size M * M (M pixels both horizontally and vertically). In this case, let’s imagine we have 3 pictures of size 2*2. And the ndarray might looks like this:
[
[ <- first image
[ <- first row of pixels of first image
0, <- first column of first row (the very top left pixel of the first image)
0 <- second column of first row
],
[0,0] <- second row of pixels of first image
],
[ [0,1], [1,0] ], <- second image
[ [1,1], [1,1] ] <- third image
]
And a requirement is to convert this highly nested structure into an easier format where each element contains all the data points for one image in a unified way. One way is that we still keep the method of looping through pixels left to right and then top down. So the final format should be
[
[0,0,0,0],
[0,1,1,0],
[1,1,1,1]
]
Ndarray has a method called reshape can totally do this magic easily.
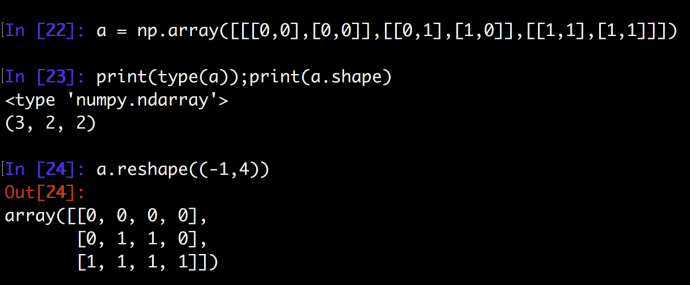
We only need to tell reshape that we want each element to store an image, which has the size of 2 * 2 = 4, and leave the first element as -1 so that numpy will be intelligent enough to infer how many total elements they need to create to hold all the images, which is three in this case.
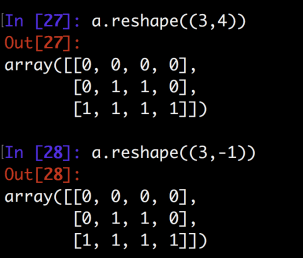
Of course, if you know the end result dimension for sure, you can pass in the first argument explicitly while omitting the second or provide two arguments at the same time. As you can tell, the end result are the same. After that, astype(np.float32) will convert all the elements from type int to be numpy.float32. We are now done for the training data grooming. The next step will be working with the labels. The label variable even simpler which it is a 1D array which each element is an integer between 0 and 9. For example, the first element could be 4, which means that the first hand written image has been recognized as a hand written 4, however, a key step to work with classification problem is to convert “factors” or “classes” into a one-hot encoding format.
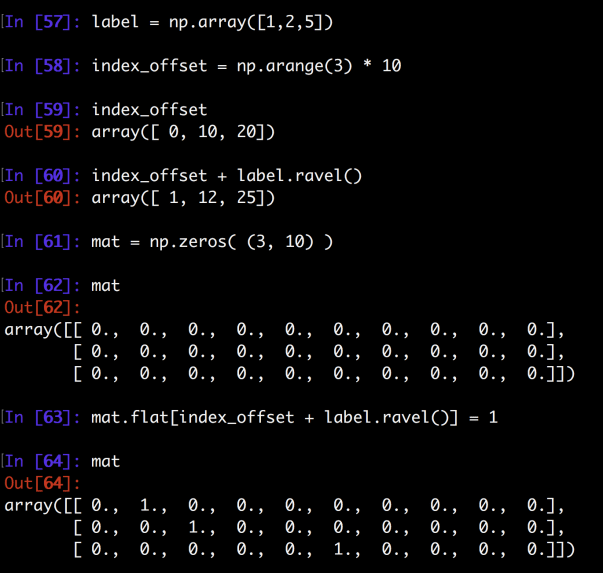
There are two ways I came across who people do it. One way is to first create an empty expanded matrix of the right size and then flip the corresponding element from 0 to 1. The second approach is what the author has been using in this notebook. Let’s take a look at both of them.
First, say our label variable is [1,2,5] which we have ten classes from 0 to 9. The end result will be to transform [1,2,5] into the following result:
[
#0 1 2 3 4 5 6 7 8 9 <- the corresponding bit of each record need to be flipped
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
]
Approach One:
Approach Two:
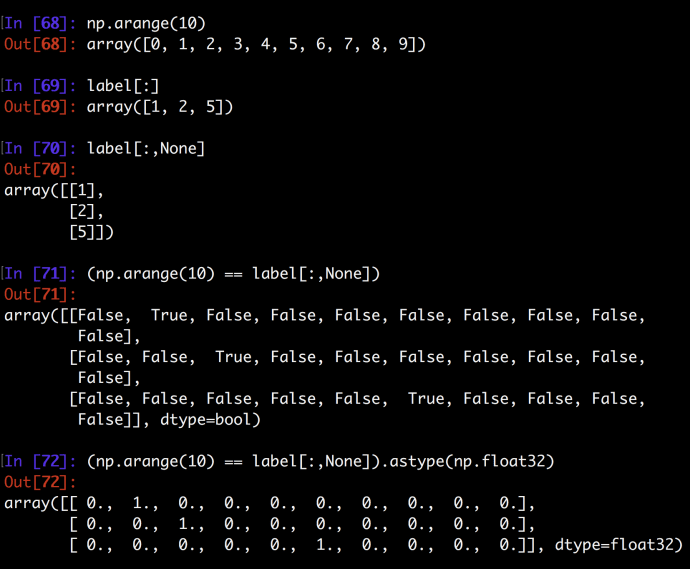
The second approach really nailed this down but fully utilizing how to slice a ndarray. Clearly, np.arrange(10) is of the size (10,1) and label[:,None] is of the size (3,1,1). Doing a equal comparison between the two will force this magic to happen. This looks very short and efficient but lack quite a readability for people who have never seen the magic, read more about numpy broadcast will help you understand what is happening behind the scene.
In the end, hopefully you have learned a thing or two massaging data.
