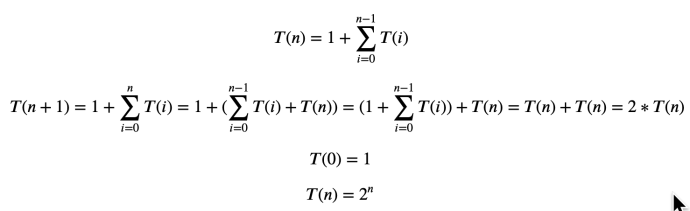Introduction
As the Cloud providers are coming up with more and more services, the life of being a software developer just becomes easier and easier. As to get something up and running usually requires many technical aspects which one individual can hardly gain. Now many of the ground work got packaged and handled well by the cloud, usually a small team or even individuals can focus on the “coding” rather than the “administration”. In this post, I will document my first experience of leveraging AWS Lambda and API gateway to build a RESTful API, using Python.
As a Python developer, usually the go-to solution is to prototype an API using frameworks like Django or Flask. However, getting something up and running on your laptop is not sufficient. In order for any API to be online, there are many requirements like it needs to be hosted in an environment outside your laptop, logging and auditing, monitoring, load balancing, authentication and authorization and even auto scaling. It is very hard work but sometimes, actually most times not very exciting. I certainly see more people who prefers to develop new features during the day time rather than keep the lights on during the night time. Cloud providers are here to achieve the purpose of facilitating developers and take those ground work away.
In this little project, I am planning to have an API that the client can submit a URL, and check if a certain keyword exists on the page or not. Of course, you can find most of the instructions just by reading AWS Lambda’s user guide.
Hello World
First, you can start by logging into your AWS console and navigate to the page for Lambda.
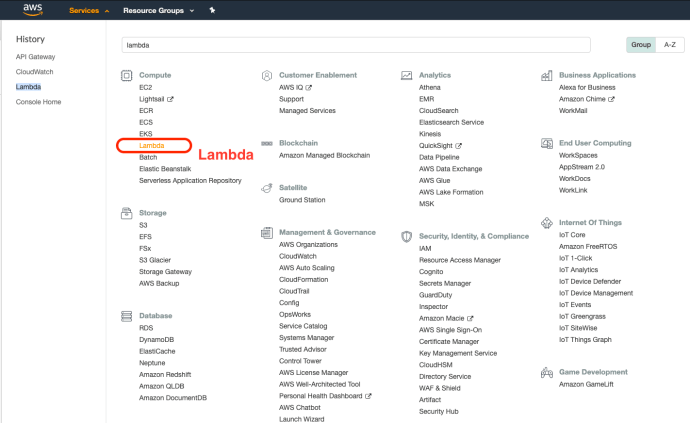
The lambda console is extremely clean, as the service itself :). The easiest place to get started is to create a function by using one of its blueprints. The sample functions range from easy ones like an echo API to complex API with hundreds of lines of code using machine learning. Hello-World-Python is a very great starting point.
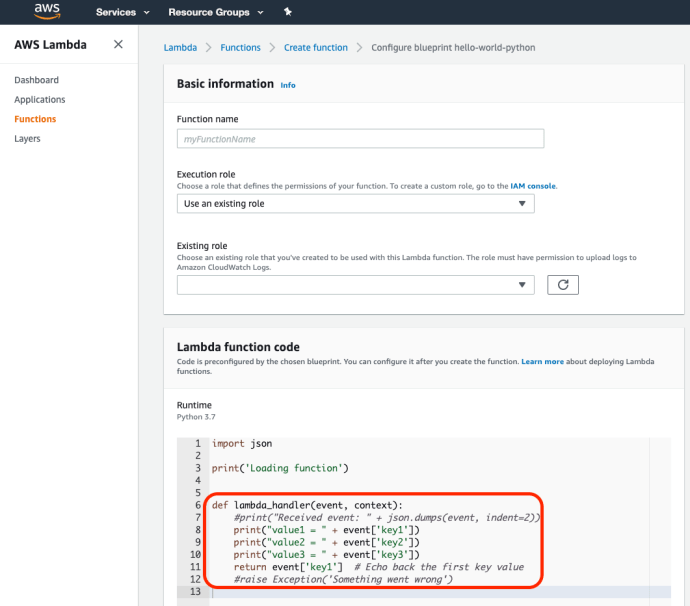
If you have used Flask or Django before, the resemblance is uncanny. The event object here in the handler is very much like the requests from flask and it stores the payload.
One thing worth highlighting is that AWS Lambda supports not only Python, but also many other languages, it even support many different versions of Python from classic 2.7 to 3.8 as the date this post was written, here is another blueprints using node.js.
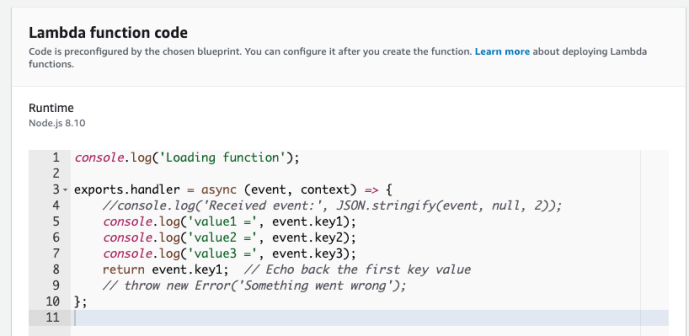
By creating a handler, you can submit and you are almost ready to go.
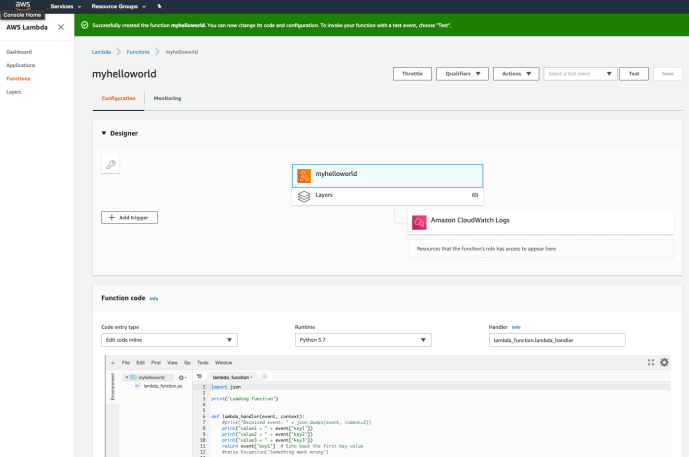
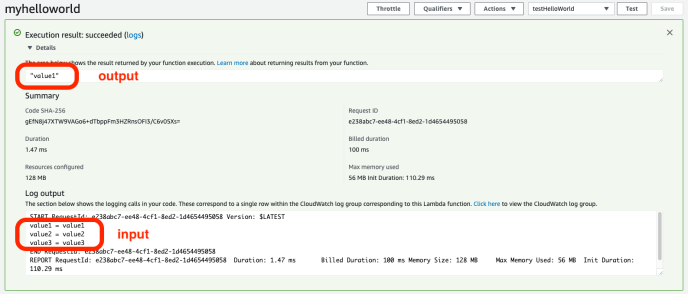
Immediately, you will have a lambda function, along with Amazon CloudWatch Logs. Your print statement or even future highly customized logging events will be stored there for debugging purposes. In the bottom of the console, there is an embedded IDE in which you can do some basic development. In order to “run” your code, you can create a test case by passing in some data to test your lambda function.
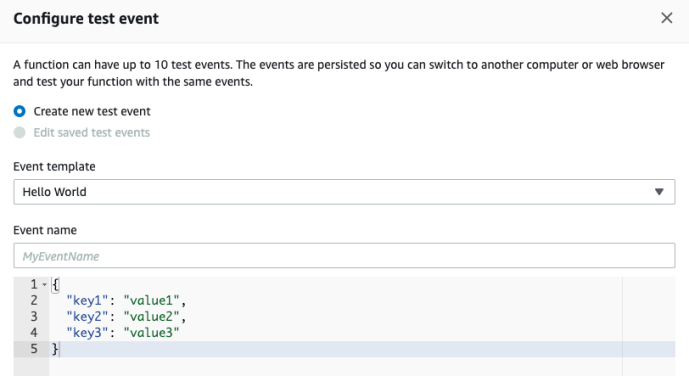
And you can check out the test result to make sure everything is fine.
Virtual Env
For our use cases, it won’t be as simple as the hello world. As we will need to use some 3rd party libraries like requests to scrape user submitted site, parse it using a library maybe like beautifulsoup. Each programming language has its own ways of handling dependencies, the Python go-to solution is usually by creating a dedicated environment for your application, so you can pinpoint which libraries you have to use in the end. And then figure out a way to pass that the whole environment or requirements to a new environment. AWS already took this into heart and provided a good solution by using virtualenv. You can find the detailed instructions here. You basically follow the following steps:
- create a virtual environment
- develop the function there with necessary libraries installed
- zip the libraries along with the python function you wrote
- submit to lambda
My code is super simple.
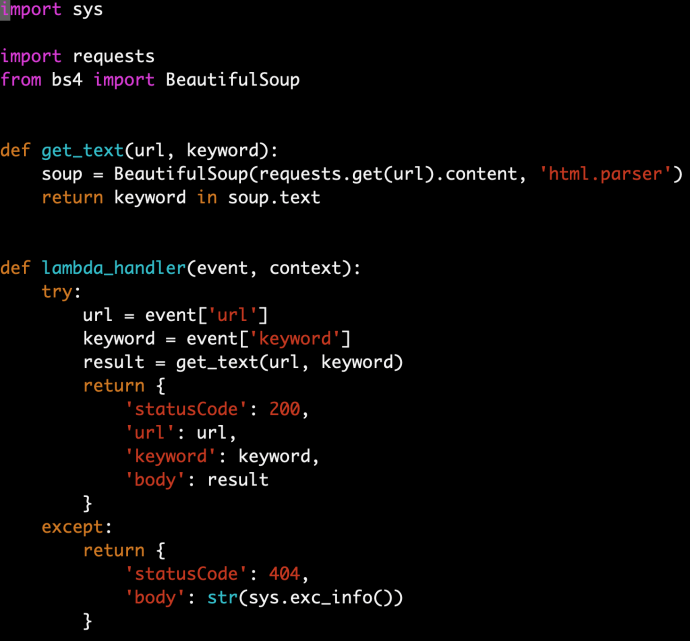
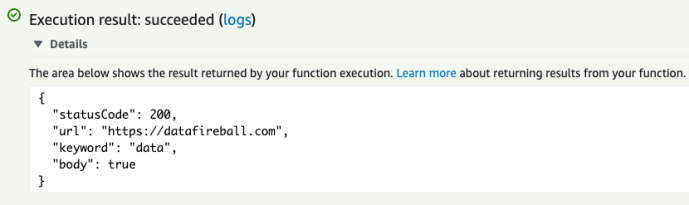
And in the end, the zip file (function.zip) is only 4.7MB. So we can upload it AS-IS, however, if your environment is a bit large, for example, if you use some heavy duty libraries like sklearn or tensorflow, you can easily exceed the limit of 50MB which then you have to use S3 to store it first.
There are still a few configurations that you can make in the Lambda function console:
- concurrency
- time out in seconds
- audit using cloudtrail
- memory usage
- error handling
However, you don’t have to do any of these if you don’t want to change the default.
AWS CLI
Again, whenever you use your mouse, you know that next time you still have to do it. For example, if you are developing more future versions of the same API or even want to create more Lamda functions, logging into the console might become a bit tedious and subject to error. After a few times, you can script your workflow using AWS CLI through the command line or event using Python to call boto3 to achieve the same goal.
The installation is pretty trivial and the set up is also only one time. The first time you use AWS CLI, you do have to copy paste a few commands from the tutorial or tinker with the command line help to get all the arguments right. However, like programing, once you get it done right once, next time is just cookie cutting and can also be automated if needed.
Conclusion
Now we have a Lambda function just like that, however, lambda itself is not necessarily a web service yet. Lambda can be integrated into many other components within the AWS ecosystem but in the next post, we will use AWS API Gateway to put a wrapped on top of it so it becomes an endpoint that is visible to the public.
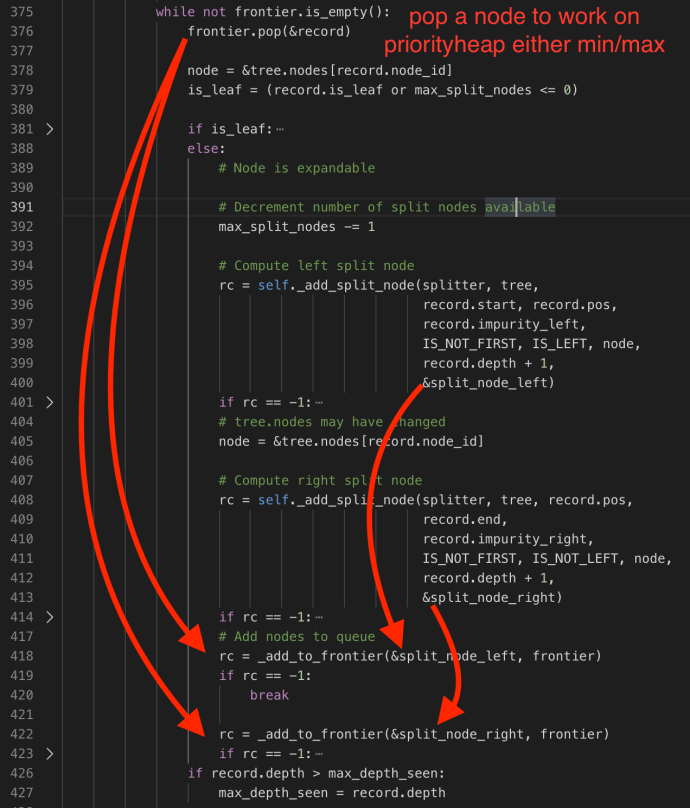



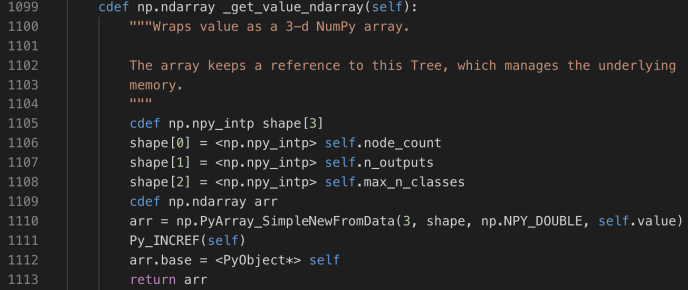






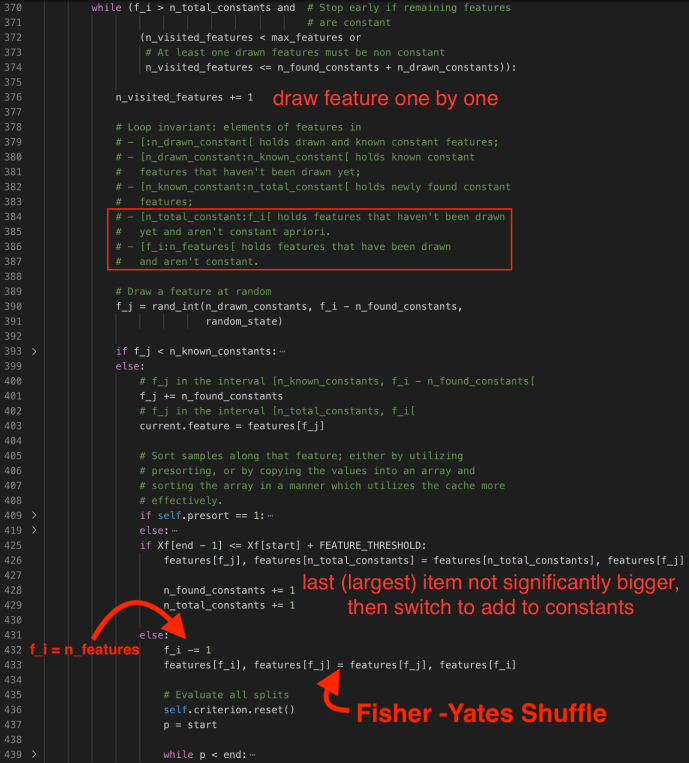





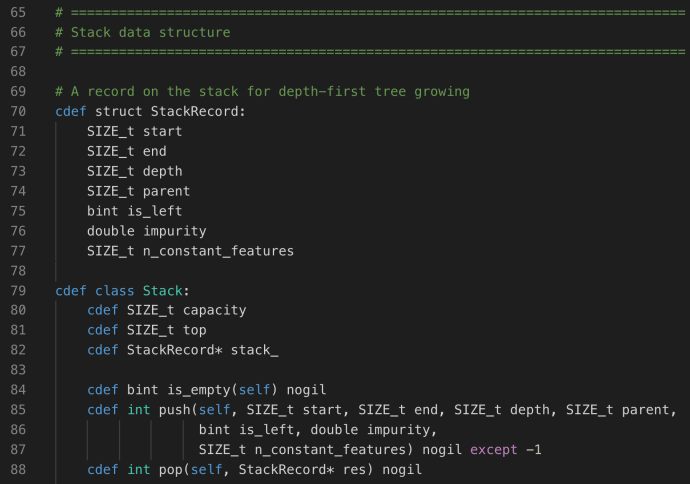

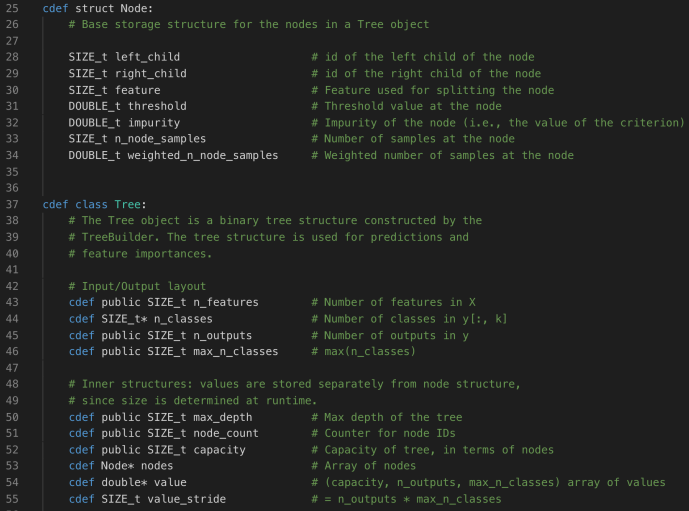
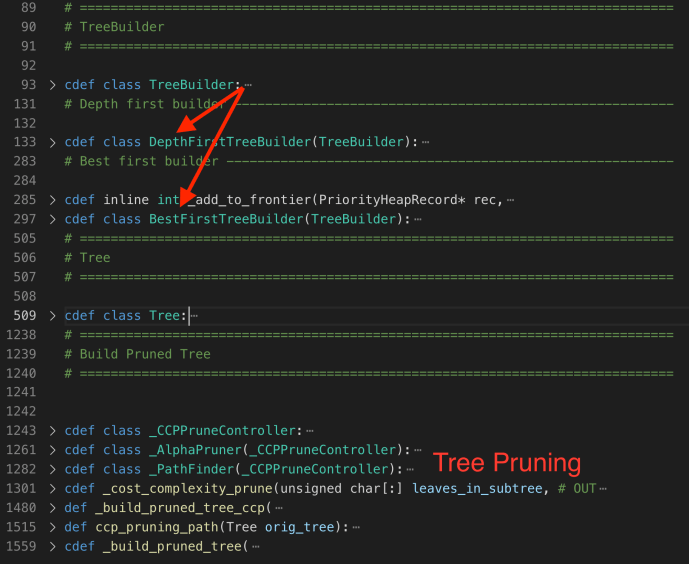

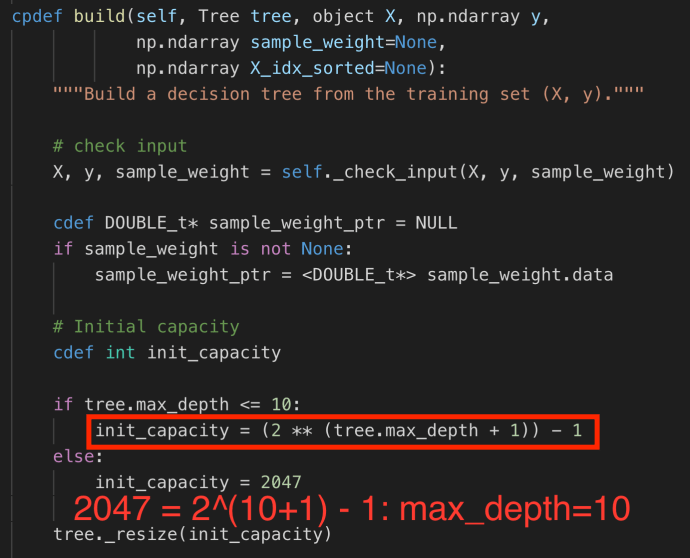
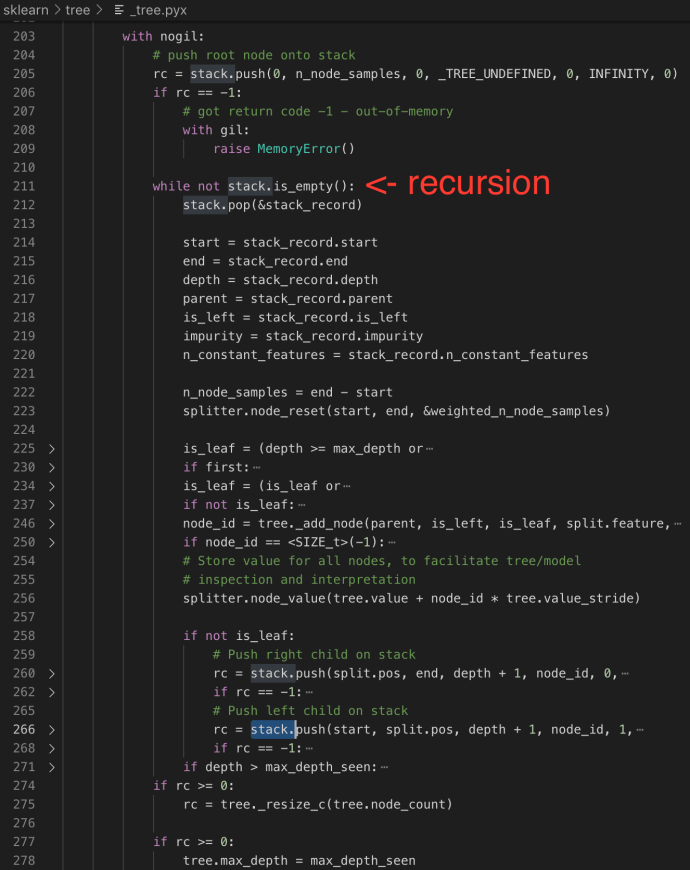
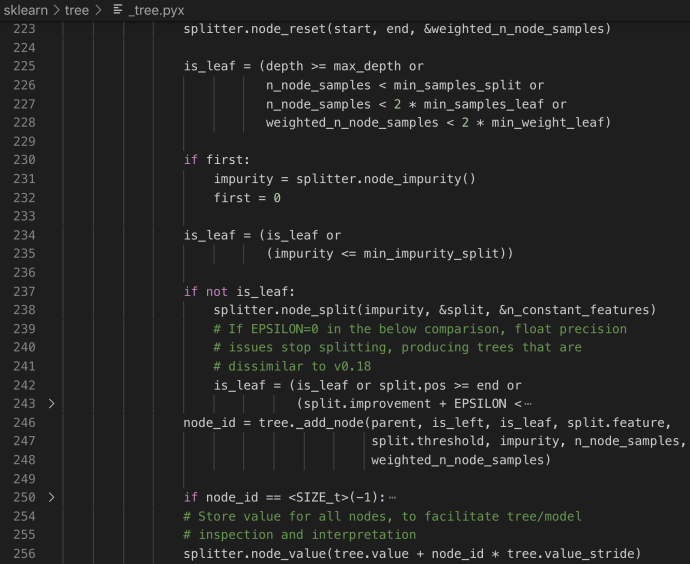
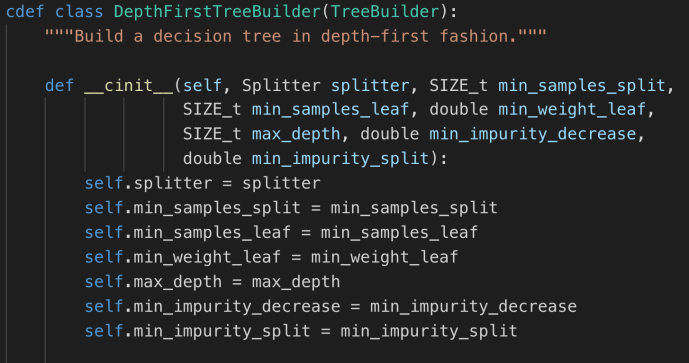 The constructor of DepthFirstTreeBuilder includes several key parameters when builder a tree. Splitter is the various splitter implementation which we will cover later. Now let’s go through the build method and see how each attribute drives the building process.
The constructor of DepthFirstTreeBuilder includes several key parameters when builder a tree. Splitter is the various splitter implementation which we will cover later. Now let’s go through the build method and see how each attribute drives the building process.